CPU 緩存一致性問(wèn)題深度解析
在現(xiàn)代多核處理器系統(tǒng)中,數(shù)據(jù)的一致性和訪問(wèn)效率是確保高性能計(jì)算的關(guān)鍵因素之一。隨著技術(shù)的發(fā)展和應(yīng)用需求的增長(zhǎng),傳統(tǒng)的單核處理架構(gòu)已經(jīng)無(wú)法滿足日益復(fù)雜的計(jì)算任務(wù)要求。因此,多核乃至多處理器系統(tǒng)的出現(xiàn)成為必然趨勢(shì)。然而,在這樣的并行計(jì)算環(huán)境中,如何保證各個(gè)核心之間的數(shù)據(jù)同步與一致成為了新的挑戰(zhàn)。

緩存一致性問(wèn)題是多核系統(tǒng)中最為核心的問(wèn)題之一。當(dāng)多個(gè)處理器核心共享同一塊內(nèi)存區(qū)域時(shí),每個(gè)核心都可能擁有該內(nèi)存區(qū)域的副本。如果一個(gè)核心修改了其緩存中的數(shù)據(jù),其他核心必須能夠及時(shí)感知這一變化,以保持?jǐn)?shù)據(jù)的一致性。為了解決這個(gè)問(wèn)題,各種緩存一致性協(xié)議應(yīng)運(yùn)而生。
本文將從最基本的總線嗅探技術(shù)入手,逐步深入探討幾種主流的緩存一致性協(xié)議,特別是MESI協(xié)議。我們將詳細(xì)介紹這些協(xié)議的工作原理、優(yōu)缺點(diǎn)以及對(duì)系統(tǒng)性能的影響。希望通過(guò)本文的講解,讀者能夠?qū)彺嬉恢滦詥?wèn)題有一個(gè)全面的理解,并掌握解決這一問(wèn)題的有效方法。
一、詳解CPU體系結(jié)構(gòu)和數(shù)據(jù)讀寫(xiě)機(jī)制
1.CPU Cache Line是什么
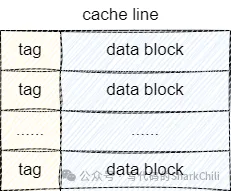
每個(gè)CPU都會(huì)有自己的二級(jí)緩存,其中一級(jí)緩存分為數(shù)據(jù)緩存和指令緩存,這些緩存的數(shù)據(jù)都是從內(nèi)存中讀取的,而且每次都會(huì)加載一個(gè)cache line,而CPU Cache Line的物理結(jié)構(gòu)大體如下圖所示:
關(guān)于cache line的大小可以使用命令鍵入如下指令進(jìn)行查看:
cat /sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size以筆者的服務(wù)器為例,可以看到對(duì)應(yīng)的輸出結(jié)果為64:

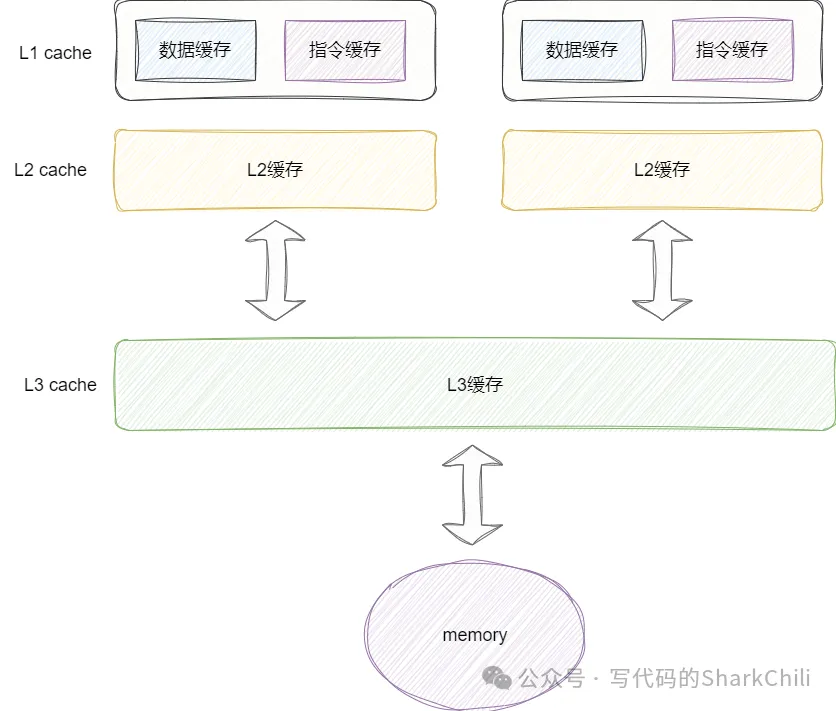
同時(shí)對(duì)應(yīng)的我們給出CPU緩存與內(nèi)存的體系結(jié)構(gòu)圖,其中按照數(shù)值減小訪問(wèn)速度越快,不同CPU核心都有獨(dú)立的二級(jí)緩存,而三級(jí)緩存則是共享緩沖區(qū),與物理內(nèi)存空間直接打交道:
如果開(kāi)發(fā)者能夠很好的使用緩存技術(shù),那么程序的性能就會(huì)很高,具體可以參照筆者之前寫(xiě)的這篇文章
計(jì)算機(jī)組成原理-基于計(jì)組CPU的基礎(chǔ)知識(shí)進(jìn)行代碼調(diào)優(yōu):https://blog.csdn.net/shark_chili3007/article/details/123038653
2.CPU Cache和內(nèi)存同步技術(shù)
(1) 寫(xiě)直達(dá)(Write Through)技術(shù)
寫(xiě)直達(dá)技術(shù)解決cache和內(nèi)存同步問(wèn)題的方式很簡(jiǎn)單,例如CPU1要操作變量i,先看看cache中有沒(méi)有變量i,若有則直接操作cache中的值,然后立刻寫(xiě)回內(nèi)存。 若變量i不在cache中,那么CPU就回去內(nèi)存中加載這個(gè)變量到cache中進(jìn)行操作,然后立刻寫(xiě)回內(nèi)存中。 這樣做的好處就是實(shí)現(xiàn)簡(jiǎn)單,缺點(diǎn)也很明顯,因?yàn)槊看味家獙⑿薷牡臄?shù)據(jù)立刻寫(xiě)回內(nèi)存,這其中的寫(xiě)入開(kāi)銷對(duì)于需要高速運(yùn)轉(zhuǎn)的CPU是一種災(zāi)難:
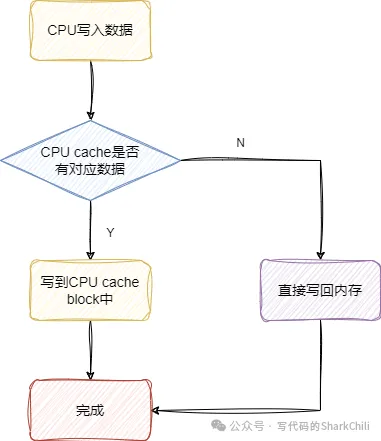
(2) 回寫(xiě)技術(shù)(Write Back)
Write Back即一種延遲寫(xiě)技術(shù),為了避免上一種操作頻繁寫(xiě)入內(nèi)存的資源開(kāi)銷而提出的一種方案,它的工作原理是將數(shù)據(jù)加載到CPU cache并修改但并不寫(xiě)入內(nèi)存,僅僅是將數(shù)據(jù)標(biāo)記為dirty,由此減少寫(xiě)入內(nèi)存的次數(shù),如果沒(méi)有發(fā)生緩存置換,這些數(shù)據(jù)就不會(huì)被寫(xiě)入內(nèi)存中。
舉個(gè)例子,CPU cache加載data1到緩存中,并進(jìn)行數(shù)次修改操作,隨后cpu cache發(fā)生data10不在緩存中需要從內(nèi)存中加載,又因?yàn)閏pu cache空間不足,此時(shí)觸發(fā)緩存置換算法便將最近最少使用且是dirty的數(shù)據(jù)寫(xiě)到內(nèi)存中,并將data10加載到cpu cache里:
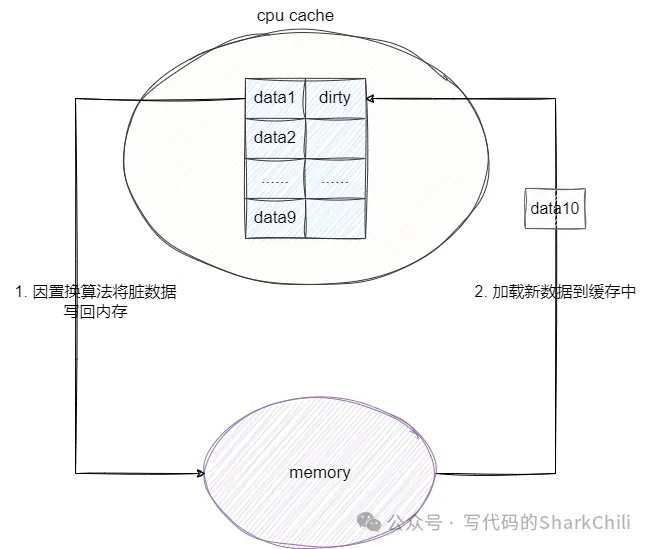
可以看出這種寫(xiě)法如果出現(xiàn)在毫秒級(jí)的斷電場(chǎng)景可能存在數(shù)據(jù)丟失問(wèn)題,又因?yàn)檠舆t寫(xiě)的原因,對(duì)應(yīng)的數(shù)據(jù)加載在讀未命中的情況下存在兩次操作:
- 將需要置換的數(shù)據(jù)寫(xiě)入內(nèi)存。
- 將需要加載的數(shù)據(jù)拉到cpu cache。
這里我們也補(bǔ)充一下幾種比較常見(jiàn)的緩存置換算法:
- Belady異常(Belady’s Anomaly)
- 最近最少使用(Least Recently Used Algorithm)
- 先進(jìn)先出(FIFO)
- 后進(jìn)先出(LIFO)
二、詳解CPU緩存一致性問(wèn)題
1.多核心緩存修改問(wèn)題
當(dāng)一臺(tái)計(jì)算機(jī)由多核CPU構(gòu)成的時(shí)候,每個(gè)CPU都從內(nèi)存里加載相同的變量i(初值為0)進(jìn)行累加操作,我們?cè)囅脒@種情況:
- CPU-0加載內(nèi)存變量i值為0。
- CPU-0自增為1準(zhǔn)備寫(xiě)回內(nèi)存。
- CPU-1加載內(nèi)存變量i值為0。
- CPU-1自增為1準(zhǔn)備寫(xiě)回內(nèi)存。 兩次自增得到結(jié)果1,這就是經(jīng)典的緩存一致性問(wèn)題:
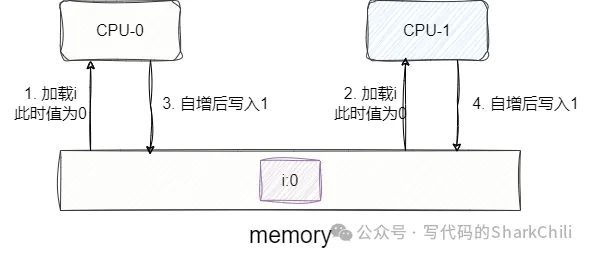
而解決這個(gè)問(wèn)題我們只要攻破以下兩點(diǎn)問(wèn)題即可:
- 寫(xiě)傳播問(wèn)題:即當(dāng)前Cache中修改的值要讓其他CPU知道
- 事務(wù)串行化:例如CPU1先將變量i改為100,CPU2再將基于當(dāng)前變量i的值乘2。我們必須保證變量i先加100,再乘2。
2.總線嗅探(Bus Snooping)
總線嗅探是解決寫(xiě)傳播的解決方案,舉個(gè)例子,當(dāng)CPU1更新Cache中變量i的值時(shí),就會(huì)通知其他核心變量i已被修改,當(dāng)其他CPU發(fā)現(xiàn)自己Cache中也有這個(gè)值的時(shí)候就會(huì)將CPU1中cache的結(jié)果更新到自己的cache中。 這種方式缺點(diǎn)很明顯,CPU必須無(wú)時(shí)不刻監(jiān)聽(tīng)變化,而且出現(xiàn)變化的數(shù)據(jù)自己還不一定有,這樣的作法增加了總線的壓力:
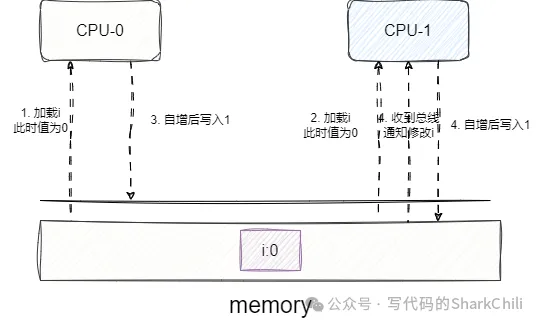
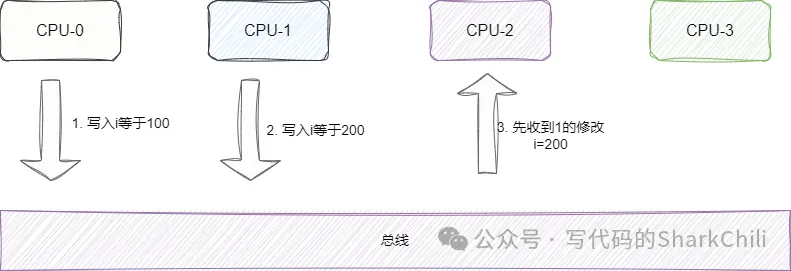
而且也不能保證事務(wù)串行化,如下圖,CPU-0加載了變量修改了值通知其他CPU這個(gè)值有變化了。 而CPU-1也改了i的值,按照正常的邏輯CPU-2、CPU-3的值應(yīng)該是先變?yōu)?00在變?yōu)?00。 但是CPU-3先收到CPU-2的通知先改為200再收到CPU-0的通知變?yōu)?00,這就導(dǎo)致的數(shù)據(jù)不一致的問(wèn)題,即事務(wù)串行化失敗:
3.MESI協(xié)議如何解決上述問(wèn)題
MESI是總線嗅探的改良版,他很好的解決了總線的帶寬壓力,以及很好的解決了數(shù)據(jù)一致性問(wèn)題。 在介紹MESI之前,我們必須了解以下MESI是什么。
- M(Modified,已修改),MESI第一個(gè)字母M,代表著CPU當(dāng)前L1 cache中某個(gè)變量i的狀態(tài)被修改了,而且這個(gè)數(shù)據(jù)在其他核心中都沒(méi)有。
- E(Exclusive,獨(dú)占),說(shuō)白了就是CPUA將數(shù)據(jù)加載自己的L1 cache時(shí),其他核心的cache中并沒(méi)有這個(gè)數(shù)據(jù),所以CPUA將這個(gè)數(shù)據(jù)加載到自己的cache時(shí)標(biāo)記為E。
- (S:Shared,共享):說(shuō)明CPUA在加載這個(gè)數(shù)據(jù)時(shí),其他CPU已經(jīng)加載過(guò)這個(gè)數(shù)據(jù)了,這時(shí)CPUA就會(huì)從其他CPU中拿到這個(gè)數(shù)據(jù)并加載到L1 cache中,并且所有擁有這個(gè)值的CPU都會(huì)將cache中的這個(gè)值標(biāo)記為S。
- (I:Invalidated,已失效):當(dāng)CPUA修改了L1 cache中的變量i時(shí),發(fā)現(xiàn)這個(gè)值是S即共享的數(shù)據(jù),那么就需要通知其他核心這個(gè)數(shù)據(jù)被改了,其他CPU都需要將cache中的這個(gè)值標(biāo)為I,后面要操作的時(shí),必須拿到最新的數(shù)據(jù)在進(jìn)行操作。
好了介紹完這幾個(gè)狀態(tài)之后,我們不妨用一個(gè)例子過(guò)一下這個(gè)流程:
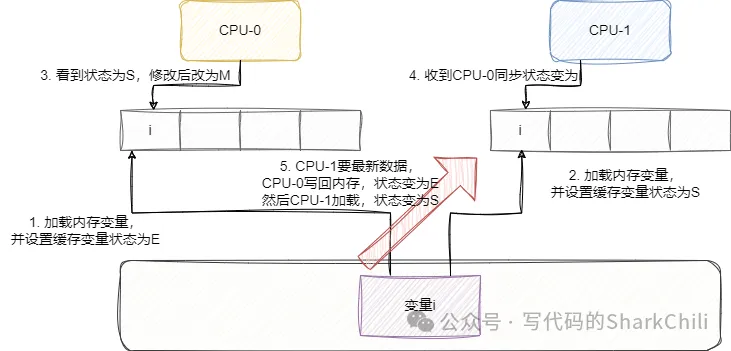
- CPU-0要加載變量i,發(fā)現(xiàn)變量i不在cache中,于是去內(nèi)存中加載數(shù)據(jù),此時(shí)通過(guò)總線發(fā)個(gè)消息給其他核心,其他核心的cache中并沒(méi)有這條數(shù)據(jù),所以這個(gè)變量的cache中的狀態(tài)為E(獨(dú)占)。
- CPU-1也加載這個(gè)數(shù)據(jù)了,在總線上發(fā)了個(gè)消息,發(fā)現(xiàn)CPU-0有這個(gè)數(shù)據(jù)且并沒(méi)有修改或者失效的標(biāo)志,于是他們一起將這個(gè)變量i狀態(tài)設(shè)置為S(共享)
- CPU-0要改變量i值了,發(fā)消息給其他核心,其他核心收到消息將自己的變量i設(shè)置為I(無(wú)效),CPU-0改完后將數(shù)據(jù)設(shè)置為M(已修改)
- CPU-0又要改變量i的值了,而且看到變量i的狀態(tài)為M(已修改),說(shuō)明這個(gè)值是最新的數(shù)據(jù),所以不發(fā)消息給其他核心了,直接更新即可。
- CPU-1要加載變量i,發(fā)現(xiàn)狀態(tài)為I,于是CPU-0將值寫(xiě)回內(nèi)存,此時(shí)狀態(tài)為E,然后CPU-1讀取這個(gè)值,大家狀態(tài)都變?yōu)镾共享。
- CPU-0要加載新的變量i了,而且變量x要使用的cache空間正是變量i的,所以CPU-0將值寫(xiě)回內(nèi)存中,這時(shí)候內(nèi)存和最新數(shù)據(jù)同步了。
三、小結(jié)
自此,我們從多核CPU體系結(jié)構(gòu)所引發(fā)緩存一致性問(wèn)題為入手,再?gòu)目偩€嗅探到MESI協(xié)議深度講解了緩存一致性問(wèn)題的解決方案,希望對(duì)你有幫助。