揭秘 Nacos 的 AP 架構 「Distro 一致性協議」
你好,我是悟空呀。
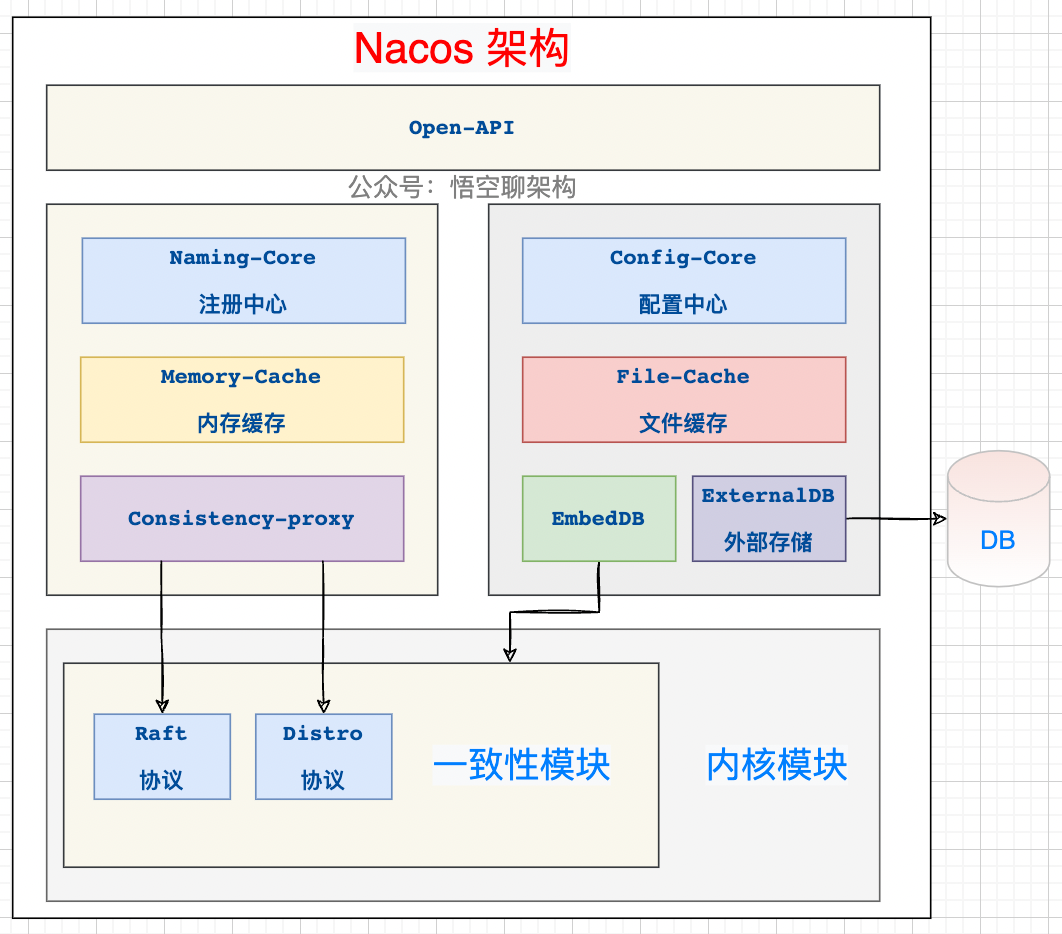
這次我們要進入 Nacos 的一致性底層原理了,還是先來一張架構圖,讓大家對 Nacos 的架構有個整體的印象,本篇會主要講解一致性模塊中的 Distro 協議。
上篇留了兩個知識點:
- ① 服務實例注冊到 Nacos 節點后,通過 UDP 方式推送到所有服務實例。讓其他服務實例感知到服務列表的變化。
- ② 如何復制數據到其他節點:當前 Nacos 節點開啟 1s 的延遲任務,將數據同步給其他 Nacos 節點。(分區一致性)
第 ② 個知識點就是 Nacos 自研的 Distro 一致性協議的核心功能。
首先這個 Distro 協議是針對集群環境的,比如下面這三個集群節點組成了一個集群。服務 A 和服務 B 會往這個集群進行注冊。
Nacos 集群節點
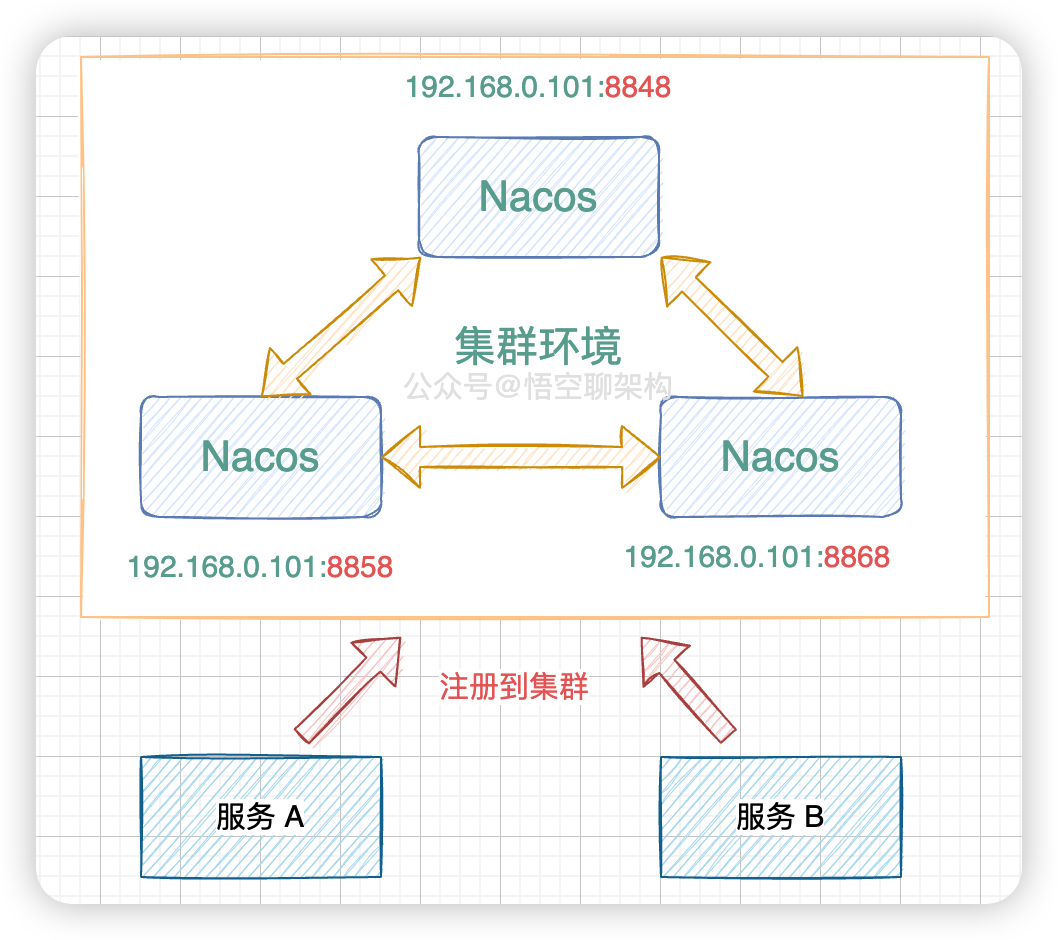
Nacos 集群環境
我們知道 Nacos 它是支持兩種分布式定理的:CP(分區一致性)和 AP(分區可用性) ,而 AP 是通過 Nacos 自研的 Distro 協議來保證的,CP 是通過 Nacos 的 JRaft 協議來保證的。
因為注冊中心作為系統中很重要的的一個服務,需要盡最大可能對外提供可用的服務,所以選擇 AP 來保證服務的高可用,另外 Nacos 還采取了心跳機制來自動完成服務數據補償的機制,所以說 Distro 協議是弱一致性的。
如果采用 CP 協議,則需要當前集群可用的節點數過半才能工作。
問題:Nacos 哪些地方用到了 AP 和 CP?
- 針對臨時服務實例,采用 AP 來保證注冊中心的可用性,Distro 協議。
- 針對持久化服務實例,采用 CP 來保證各個節點的強一致性,JRaft 協議。(JRaft 是 Nacos 對 Raft 的一種改造)
- 針對配置中心,無 Database 作為存儲的情況下,Nacos 節點之間的內存數據為了保持一致,采用 CP。Nacos 提供這種模式只是為了方便用戶本機運行,降低對存儲依賴,生產環境一般都是通過外置存儲組件來保證數據一致性。
- 針對配置中心,有 Database 作為存儲的情況下,Nacos 通過持久化后通知其他節點到數據庫拉取數據來保證數據一致性,另外采用讀寫分離架構來保證高可用,所以這里我認為這里采用的 AP,歡迎探討。
- 針對 異地多活,采用 AP 來保證高可用。
弦外音:
臨時服務實例就是我們默認使用的 Nacos 注冊中心模式,客戶端注冊后,客戶端需要定時上報心跳信息來進行服務實例續約。這個在注冊的時候,可以通過傳參設置是否是臨時實例。
持久化服務實例就是不需要上報心跳信息的,不會被自動摘除,除非手動移除實例,如果實例宕機了,Nacos 只會將這個客戶端標記為不健康。
本篇會帶著大家從源碼角度來深入剖析下 Distro 協議。
知識點預告:
- ① Distro 的設計思想和六大機制。
- ② Nacos 如何同步數據到其他節點。(異步復制機制,本篇重點講解)
- ③ Nacos 如何保證所有節點的數據一致性。(定期檢驗;健康檢查機制,下一篇重點講解)
- ④ 新加入的 Nacos 節點,如何進行拉取數據。(新節點同步機制)
一、Distro 的設計思想和六大機制
Distro 協議是 Nacos 對于臨時實例數據開發的一致性協議。
Distro 協議是集 Gossip + Eureka 協議的優點并加以優化后出現的。
Gossip 協議有什么坑?由于隨機選取發送的節點,不可避免地存在消息重復發送給同一節點的情況,增加了網絡的傳輸的壓力,給消息節點帶來額外的處理負載。
Distro 協議的優化:每個節點負責一部分數據,然后將數據同步給其他節點,有效地降低了消息冗余的問題。
關于臨時實例數據:臨時數據其實是存儲在內存緩存中的,并且在其他節點在啟動時會進行全量數據同步,然后節點也會定期進行數據校驗。
大家不要被這個協議嚇到,其實就是阿里自己實現的一套同步邏輯。
AP 中的 P 代表網絡分區,所以 Distro 在分布式集群環境下才能真正發揮其作用。它保證了在多個 Nacos 節點組成的 Nacos 集群環境中,當其中某個 Nacos 宕機后,整個集群還是能正常工作。
Distro 的設計機制:
- 平等機制:Nacos 的每個節點是平等的,都可以處理寫的請求。(上一講已經重點講解了?)
- 異步復制機制:Nacos 把變更的數據異步復制到其他節點。(??重點講解)
- 健康檢查機制:每個節點只存了部分數據,定期檢查客戶端狀態保持數據一致性。
- 本地讀機制: 每個節點獨立處理讀請求,及時從本地發出響應。
- 新節點同步機制:Nacos 啟動時,從其他節點同步數據。
- 路由轉發機制:客戶端發送的寫請求,如果屬于自己則處理,否則路由轉發給其他節點。(上一講已經重點講解了?)
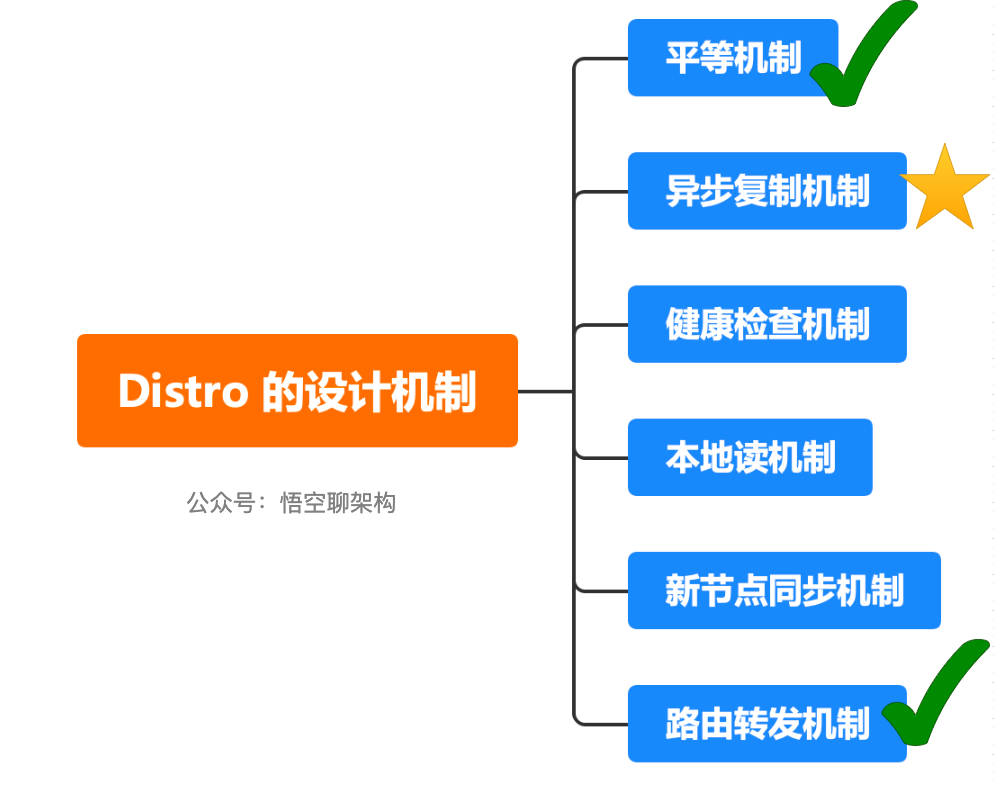
Distro 的設計機制
二、異步復制機制:寫入數據后如何同步給其他節點
2.1 核心入口
核心源碼路徑:
/naming/consistency/ephemeral/distro/DistroConsistencyServiceImpl.java
這個類的名字就說明它是 Distro 一致性協議的接口實現類。
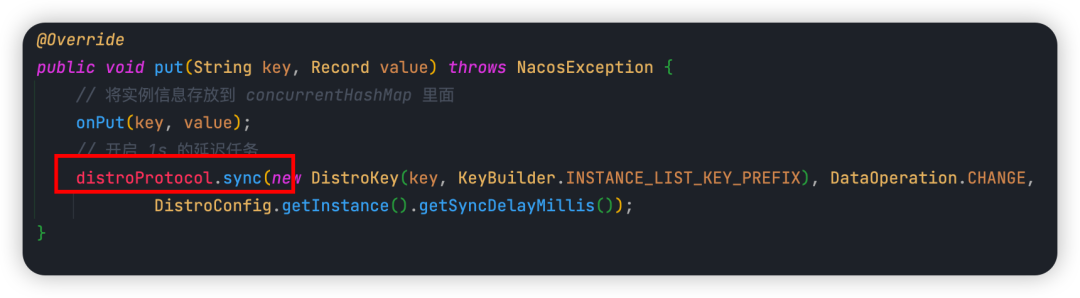
當注冊請求交給 Nacos 節點來處理時,核心入口方法就是 put(),如下圖所示:
上一講我們已經說過,這里面會做幾件事:
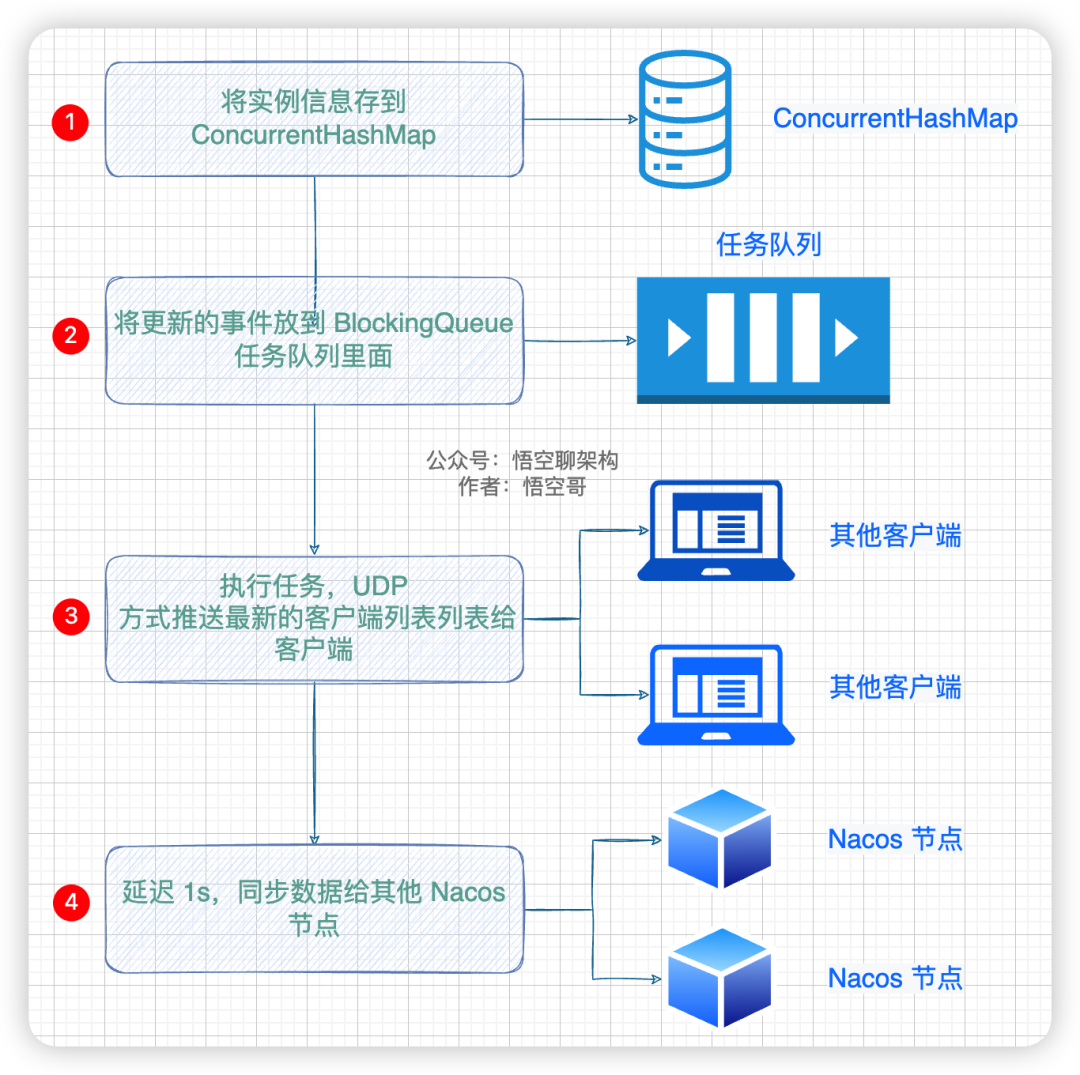
添加實例信息的流程
① 將實例信息存放到內存緩存 concurrentHashMap 里面。
② 添加一個任務到 BlockingQueue 里面,這個任務就是將最新的實例列表通過 UDP 的方式推送給所有客戶端(服務實例),這樣客戶端就拿到了最新的服務實例列表,緩存到本地。
③ 開啟 1s 的延遲任務,將數據通過給其他 Nacos 節點。
說明:第二件事是 Nacos 和 客戶端如何保持數據一致性的,第三件事是 Nacos 集群間如何保持數據一致性的,因本篇重點講解 Nacos 的 AP 原理,所以會針對第三件事來進行闡述。而第二件事,會在后續文章中重點講解。
2.2 sync 方法的參數說明
首先我們來看下 distroProtocol.sync(),這個方法傳了哪些參數:
第一個參數 new DistroKey(),它里面傳了 key 和一個常量。
key:就是客戶端的服務名,示例值如下:
com.alibaba.nacos.naming.iplist.ephemeral.public##DEFAULT_GROUP@@nacos.naming.serviceName
INSTANCE_LIST_KEY_PREFIX:就是 com.alibaba.nacos.naming.iplist.
然后這兩個參數組裝成一個 DistroKey。
第二個參數是同步數據的類型,這里為 change。
第三個參數是同步任務的延遲時間,1s。
2.3 sync 的核心邏輯:添加任務
先上一張原理圖幫助大家理解,流程圖如下所示。核心邏輯分為以下幾步。
- 遍歷其他節點,拿到節點信息。
- 判斷這個任務在 map 中是否存在,如果存在則合并這個 task。
- 如果不存在,則加到 map 中。
- 后臺線程遍歷這個 map,拿到任務。
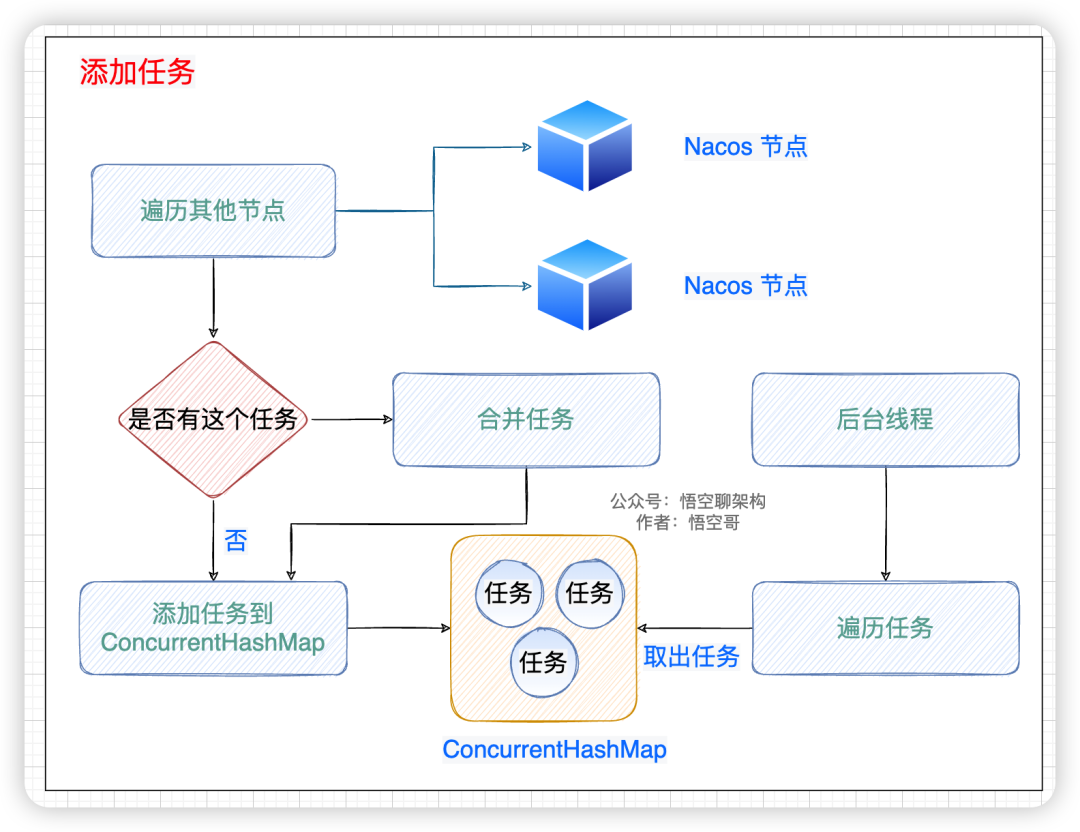
添加任務到 map 中
代碼的時序圖如下所示:
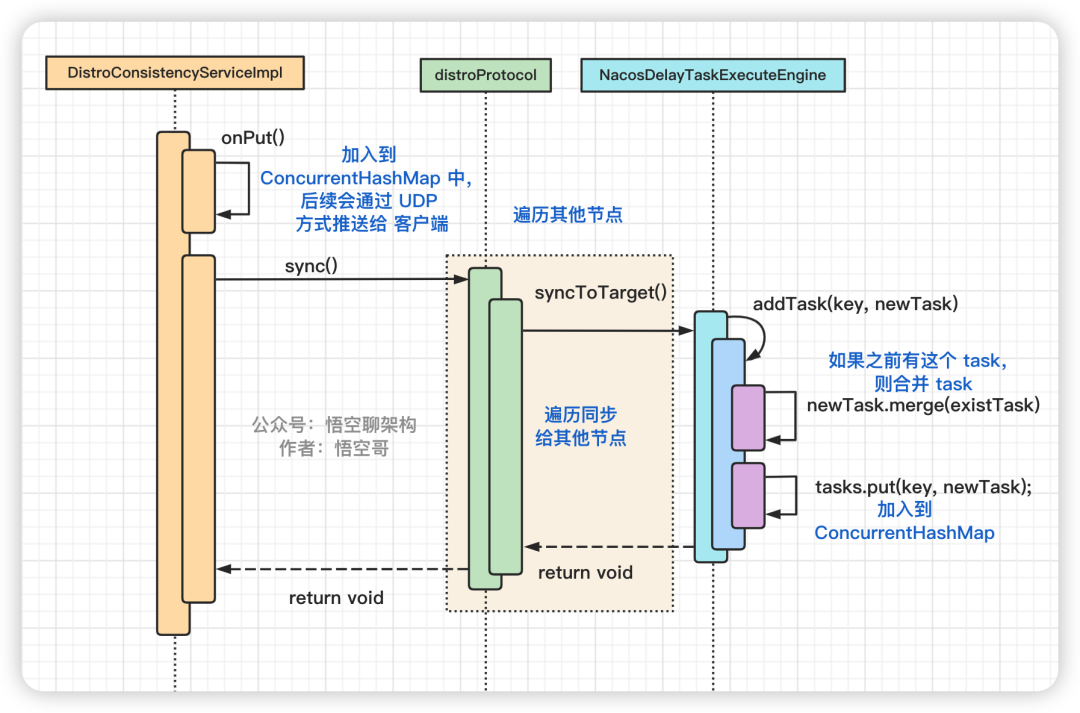
sync 的核心代碼時序圖
- 第一個類 DistroConsistencyServiceImpl 把實例信息加入 map 中,后續通過 UDP方式推送給客戶端。
- 第二個類 DistroProtocol 主要就是循環遍歷其他節點。
- 第三個類 NacosDelayTaskExecuteEngine 是核心類,創建了一個同步的任務到 ConcurrentHashMap 中。
2.4 sync 的核心邏輯:后臺線程異步復制數據
先說下哈,這個核心邏輯極其復雜,我們看的時候需要抓主線,知道其中幾個關鍵點就可以了。
悟空在畫代碼邏輯圖的時候,內心是崩潰的,Nacos 為什么寫這么復雜啊!大家不用細看,看了也會懵??,理解核心步驟就可以了。(圖中有個小細節,我對不同的類進行了顏色區分)
核心步驟:
- 遍歷其他節點,創建一個同步的任務,加到 map 中。
- 后臺線程不斷從 map 中拿到 task,然后移除這個 task。
- 把這個 task 加到一個隊列里面。
- 有個 worker 專門從隊列里面拿到 task 來執行。
這個 task 就是發送 http 請求給其他節點,請求參數中包含注冊的實例信息(序列化后的二進制數據)。拼接的請求 url 地址為:
http://192.168.0.101:8858/nacos/v1/ns/distro/datum
Nacos 異步復制數據到其他節點的流程圖如下:
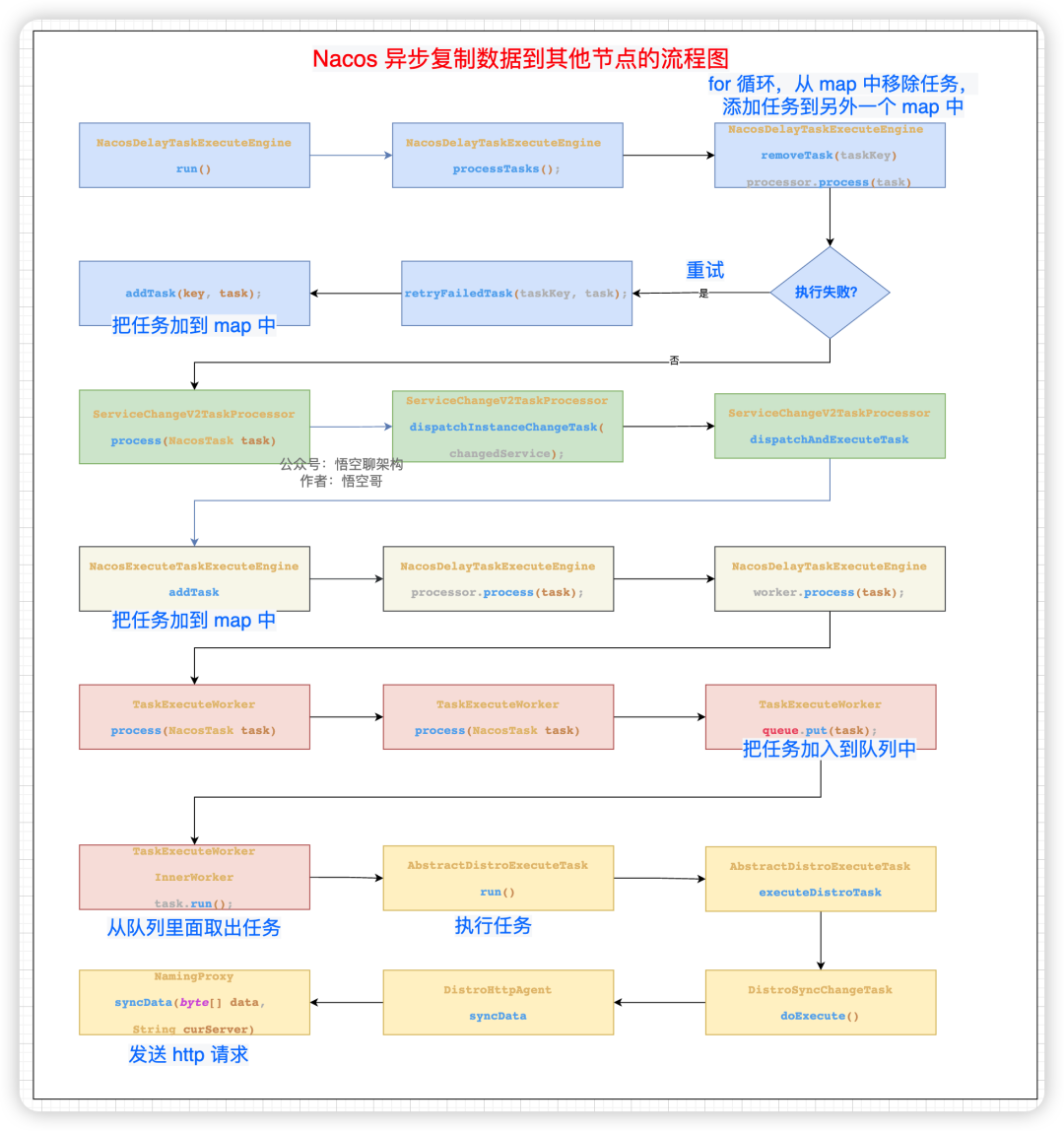
Nacos 異步復制數據到其他節點的流程圖
2.5 其他節點如何處理同步請求
2.5.1 如何存儲注冊信息
處理同步請求的邏輯還是比較簡單的,就是把注冊信息存起來,然后同步到其他客戶端。
注冊信息會存放到一個 datum 中,然后 datum 放到一個 dataStore 中。datum 和 dataStore 的數據結構如下圖所示:
- datum 包含 value、key、timestamp。value 就是注冊的客戶端信息(是一個 ArrayList)
- datastore 是一個 ConcurrentHashMap,包含多個 datum。
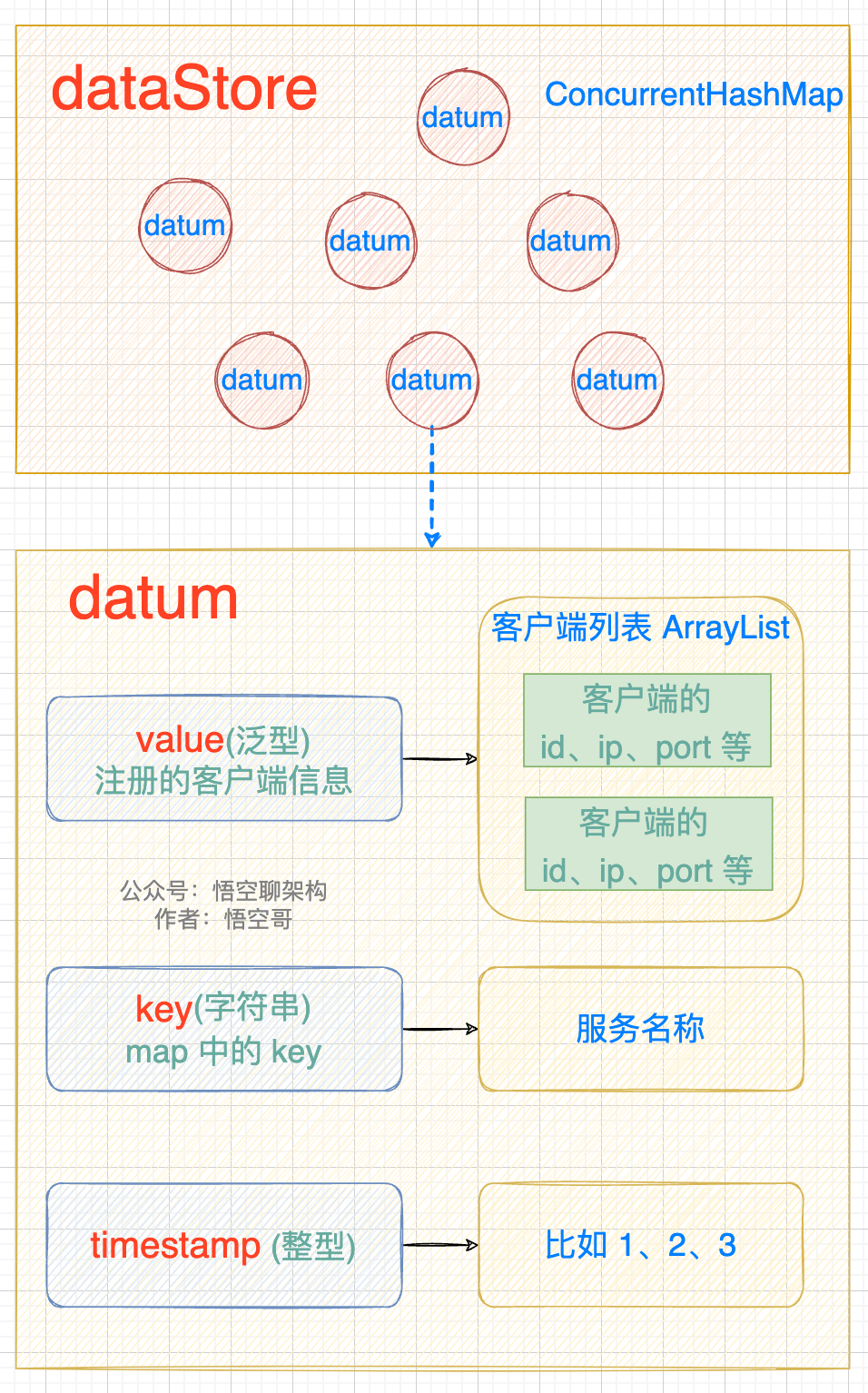
存儲注冊信息的數據結構
2.5.2 源碼分析
根據 2.4 講到的請求的 URL:/nacos/v1/ns/distro/datum,處理這個請求的類為
com/alibaba/nacos/naming/controllers/DistroController.java
入口方法為 onSyncDatum,里面做的主要事情如下:
- ① 把實例信息放入到一個 datum 內存中,然后又存放到 DataStore 的結構中,而 DataStore 的本質就是一個 ConcurrentHashMap。
- ② 將注冊信息通過 UDP 的方式推送給客戶端。
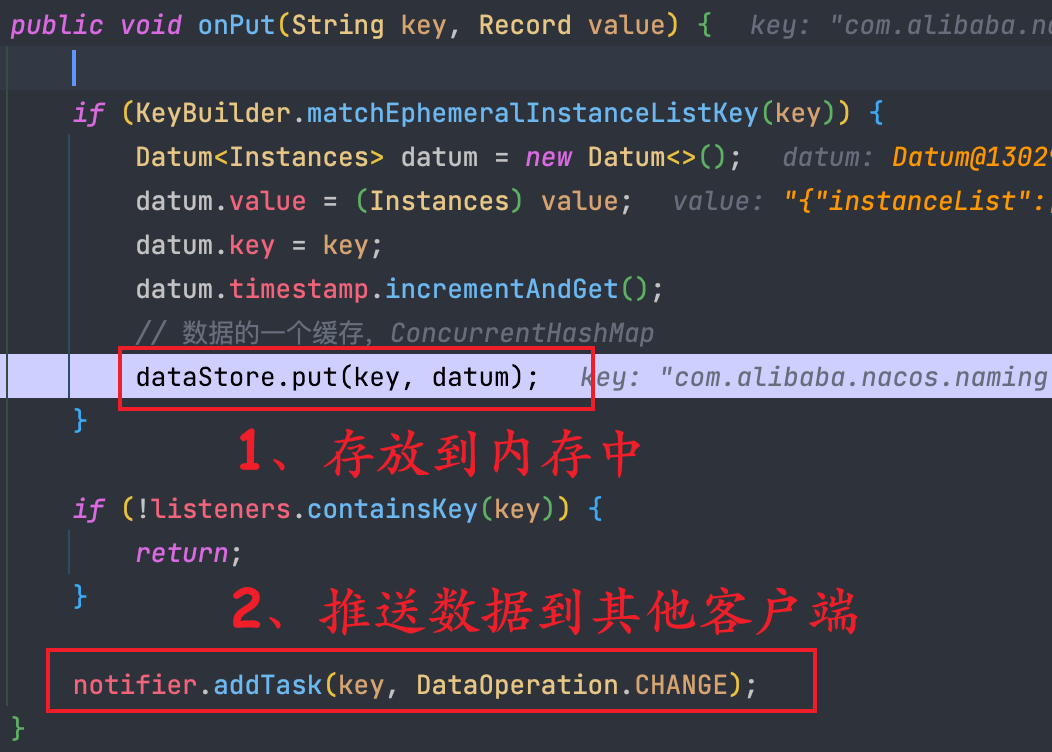
服務端處理注冊請求的源碼
三、定時同步:如何保持數據一致性
3.1 為什么需要定時同步
在 Nacos 集群模式下,它作為一個完整的注冊中心,必須具有高可用特性。
在集群模式下,客戶端只需要和其中一個 Nacos 節點通信就可以了,但是每個節點其實是包含所有客戶端信息的,這樣做的好處是每個 Nacos 節點只需要負責自己的客戶端就可以(分攤壓力),而當客戶端想要拉取全量注冊表到本地時,從任意節點都可以讀取到(數據一致性)。
那么 Nacos 集群之間是如何通過 Distro 協議來保持數據一致性的呢?
3.2 定期檢驗元數據
在版本 v1 中 ,采用的是定期檢驗元信息的方式。元信息就是當前節點包含的客戶端信息的 md5 值。
檢驗的原理如下圖所示:
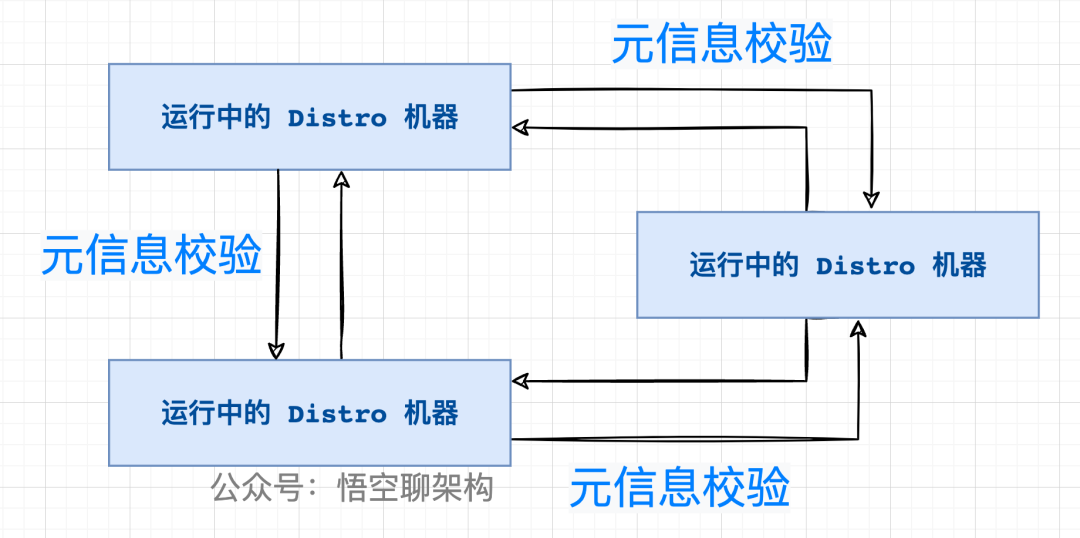
Nacos 各個節點會有一個心跳任務,定期向其他機器發送一次數據檢驗請求,在校驗的過程中,當某個節點發現其他機器上的數據的元信息和本地數據的元信息不一致,則會發起一次全量拉取請求,將數據補齊。
請求 URL:
http://其他 Nacos 節點的 IP:port/nacos/v1/ns/distro/checksum?source =
本機的IP地址:本機的端口號
參數:DistroData,內部包裝的是一個Map<服務名稱,服務下實例的驗證字符串 checksum>
3.3 關于版本迭代的說明
在版本 v2 中,定期校驗數據已經不用了,采用的是健康檢查機制,來和其他節點來保持數據的同步,由于涉及的內容還挺多,放到下一講來專門講解 Nacos 的健康檢查機制:
客戶端與 Nacos 節點的健康檢查機制。
集群模式下的健康檢查機制。
四、新節點同步機制,如何保持數據一致性
4.1 原理
新加入的 Distro 節點會進行全量數據拉取,輪詢所有的 Distro 節點,向其他節點發送請求拉取全量數據。
在全量拉取操作完成之后,每臺機器上都維護了當前的所有注冊上來的非持久化實例數據。
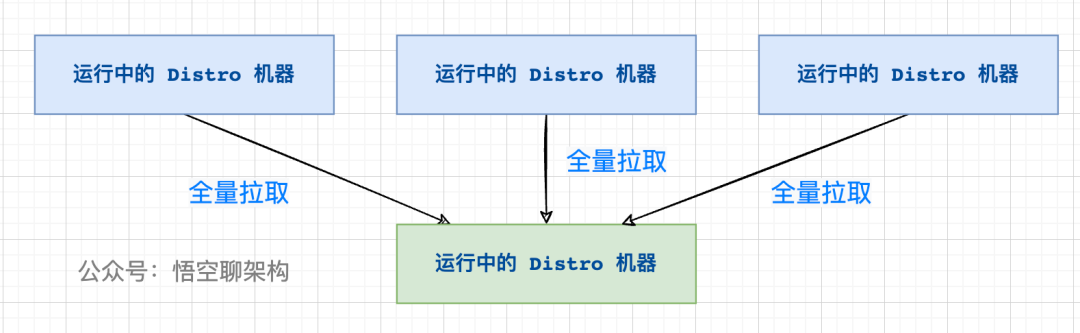
4.2 源碼分析
DistroProtocol 類的構造方法會啟動一個同步任務,從其他 Nacos 節點全量拉取非持久化實例數據。
/nacos/core/distributed/distro/DistroProtocol.java
startDistroTask();
startLoadTask();
/nacos/core/distributed/distro/task/load/DistroLoadDataTask.java
run();
load();
loadAllDataSnapshotFromRemote();
五、本地讀機制
5.1 原理
每個 Nacos 節點雖然只負責屬于自己的客戶端,但是每個節點都是包含有所有的客戶端信息的,所以當客戶端想要查詢注冊信息時,可以直接從請求的 Nacos 的節點拿到全量數據。
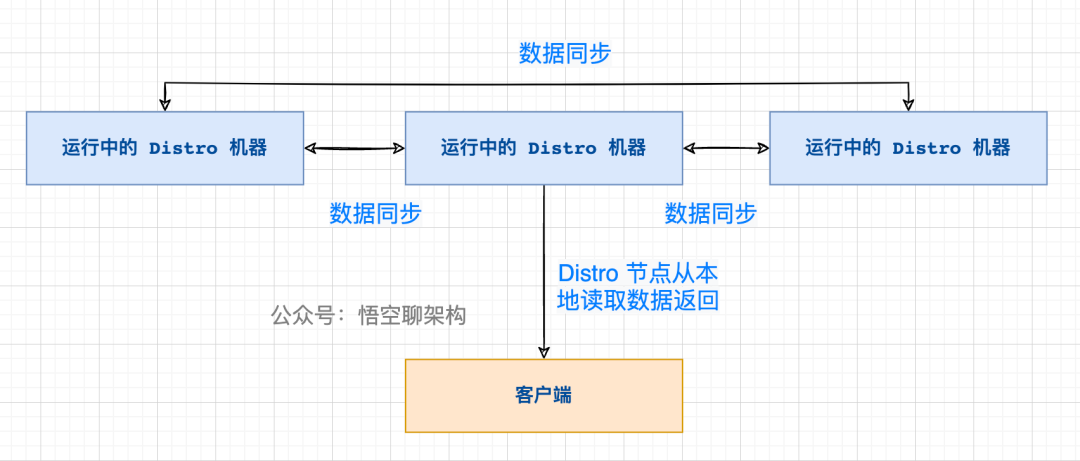
讀操作的原理
這樣設計的好處是保證了高可用(AP),分為兩個方面:
- ① 讀操作都能進行及時的響應,不需要到其他節點拿數據。
- ② 當腦裂發生時,Nacos 的節點也能正常返回數據,即使數據可能不一致,當網絡恢復時,通過健康檢查機制或數據檢驗也能達到數據一致性。
六、總結
本篇通過原理圖 + 源碼的方式講解了 Distro 協議的原理,其中又分為幾個機制,而這幾個機制共同保證了 Nacos 的 AP。
不足之處,本篇未針對源碼的設計進行深入剖析,只是把主線捋出來了。如文中有問題,歡迎探討~
參考資料:
Nacos 官網
https://blog.csdn.net/qq_24768941/article/details/122420711
https://www.cnblogs.com/lukama/p/14984858.html