Java壓縮20M文件從30秒到1秒的優化過程
有一個需求需要將前端傳過來的10張照片,然后后端進行處理以后壓縮成一個壓縮包通過網絡流傳輸出去。之前沒有接觸過用Java壓縮文件的,所以就直接上網找了一個例子改了一下用了,改完以后也能使用,但是隨著前端所傳圖片的大小越來越大的時候,耗費的時間也在急劇增加,最后測了一下壓縮20M的文件竟然需要30秒的時間。壓縮文件的代碼如下。
- public static void zipFileNoBuffer() {
- File zipFile = new File(ZIP_FILE);
- try (ZipOutputStream zipOut = new ZipOutputStream(new FileOutputStream(zipFile))) {
- //開始時間
- long beginTime = System.currentTimeMillis();
- for (int i = 0; i < 10; i++) {
- try (InputStream input = new FileInputStream(JPG_FILE)) {
- zipOut.putNextEntry(new ZipEntry(FILE_NAME + i));
- int temp = 0;
- while ((temp = input.read()) != -1) {
- zipOut.write(temp);
- }
- }
- }
- printInfo(beginTime);
- } catch (Exception e) {
- e.printStackTrace();
- }
這里找了一張2M大小的圖片,并且循環十次進行測試。打印的結果如下,時間大概是30秒。
- fileSize:20M
- consum time:29599
第一次優化過程-從30秒到2秒
進行優化首先想到的是利用緩沖區 BufferInputStream。在 FileInputStream中 read()方法每次只讀取一個字節。源碼中也有說明。
- /**
- * Reads a byte of data from this input stream. This method blocks
- * if no input is yet available.
- *
- * @return the next byte of data, or <code>-1</code> if the end of the
- * file is reached.
- * @exception IOException if an I/O error occurs.
- */
- public native int read() throws IOException;
這是一個調用本地方法與原生操作系統進行交互,從磁盤中讀取數據。每讀取一個字節的數據就調用一次本地方法與操作系統交互,是非常耗時的。例如我們現在有30000個字節的數據,如果使用 FileInputStream那么就需要調用30000次的本地方法來獲取這些數據,而如果使用緩沖區的話(這里假設初始的緩沖區大小足夠放下30000字節的數據)那么只需要調用一次就行。因為緩沖區在第一次調用 read()方法的時候會直接從磁盤中將數據直接讀取到內存中。隨后再一個字節一個字節的慢慢返回。
BufferedInputStream內部封裝了一個byte數組用于存放數據,默認大小是8192
優化過后的代碼如下
- public static void zipFileBuffer() {
- File zipFile = new File(ZIP_FILE);
- try (ZipOutputStream zipOut = new ZipOutputStream(new FileOutputStream(zipFile));
- BufferedOutputStream bufferedOutputStream = new BufferedOutputStream(zipOut)) {
- //開始時間
- long beginTime = System.currentTimeMillis();
- for (int i = 0; i < 10; i++) {
- try (BufferedInputStream bufferedInputStream = new BufferedInputStream(new FileInputStream(JPG_FILE))) {
- zipOut.putNextEntry(new ZipEntry(FILE_NAME + i));
- int temp = 0;
- while ((temp = bufferedInputStream.read()) != -1) {
- bufferedOutputStream.write(temp);
- }
- }
- }
- printInfo(beginTime);
- } catch (Exception e) {
- e.printStackTrace();
- }
- }
輸出
- ------Buffer
- fileSize:20M
- consum time:1808
可以看到相比較于第一次使用 FileInputStream效率已經提升了許多了
第二次優化過程-從2秒到1秒
使用緩沖區 buffer的話已經是滿足了我的需求了,但是秉著學以致用的想法,就想著用NIO中知識進行優化一下。
使用Channel
為什么要用 Channel呢?因為在NIO中新出了 Channel和 ByteBuffer。正是因為它們的結構更加符合操作系統執行I/O的方式,所以其速度相比較于傳統IO而言速度有了顯著的提高。Channel就像一個包含著煤礦的礦藏,而 ByteBuffer則是派送到礦藏的卡車。也就是說我們與數據的交互都是與 ByteBuffer的交互。
在NIO中能夠產生 FileChannel的有三個類。分別是 FileInputStream、 FileOutputStream、以及既能讀又能寫的 RandomAccessFile。
源碼如下
- public static void zipFileChannel() {
- //開始時間
- long beginTime = System.currentTimeMillis();
- File zipFile = new File(ZIP_FILE);
- try (ZipOutputStream zipOut = new ZipOutputStream(new FileOutputStream(zipFile));
- WritableByteChannel writableByteChannel = Channels.newChannel(zipOut)) {
- for (int i = 0; i < 10; i++) {
- try (FileChannel fileChannel = new FileInputStream(JPG_FILE).getChannel()) {
- zipOut.putNextEntry(new ZipEntry(i + SUFFIX_FILE));
- fileChannel.transferTo(0, FILE_SIZE, writableByteChannel);
- }
- }
- printInfo(beginTime);
- } catch (Exception e) {
- e.printStackTrace();
- }
- }
我們可以看到這里并沒有使用 ByteBuffer進行數據傳輸,而是使用了 transferTo的方法。這個方法是將兩個通道進行直連。
- This method is potentially much more efficient than a simple loop
- * that reads from this channel and writes to the target channel. Many
- * operating systems can transfer bytes directly from the filesystem cache
- * to the target channel without actually copying them.
這是源碼上的描述文字,大概意思就是使用 transferTo的效率比循環一個 Channel讀取出來然后再循環寫入另一個 Channel好。操作系統能夠直接傳輸字節從文件系統緩存到目標的 Channel中,而不需要實際的 copy階段。
copy階段就是從內核空間轉到用戶空間的一個過程
可以看到速度相比較使用緩沖區已經有了一些的提高。
- ------Channel
- fileSize:20M
- consum time:1416
內核空間和用戶空間
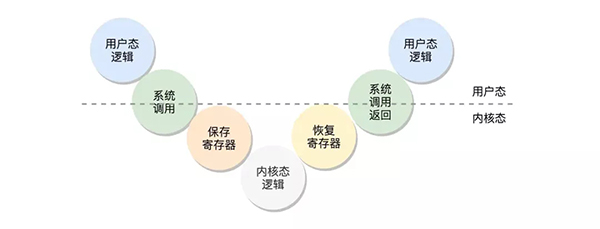
那么為什么從內核空間轉向用戶空間這段過程會慢呢?首先我們需了解的是什么是內核空間和用戶空間。在常用的操作系統中為了保護系統中的核心資源,于是將系統設計為四個區域,越往里權限越大,所以Ring0被稱之為內核空間,用來訪問一些關鍵性的資源。Ring3被稱之為用戶空間。
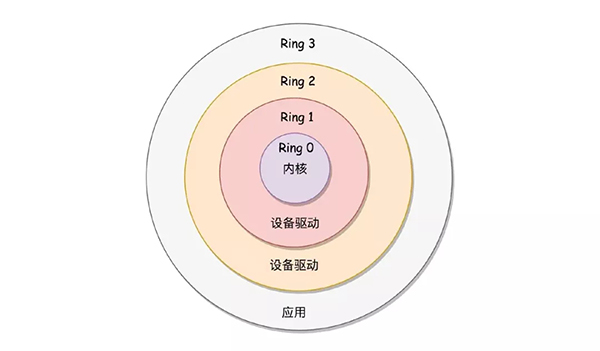
用戶態、內核態:線程處于內核空間稱之為內核態,線程處于用戶空間屬于用戶態
那么我們如果此時應用程序(應用程序是都屬于用戶態的)需要訪問核心資源怎么辦呢?那就需要調用內核中所暴露出的接口用以調用,稱之為系統調用。例如此時我們應用程序需要訪問磁盤上的文件。此時應用程序就會調用系統調用的接口 open方法,然后內核去訪問磁盤中的文件,將文件內容返回給應用程序。大致的流程如下
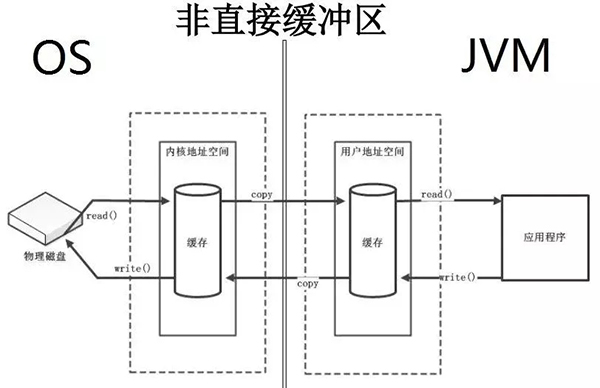
直接緩沖區和非直接緩沖區
既然我們要讀取一個磁盤的文件,要廢這么大的周折。有沒有什么簡單的方法能夠使我們的應用直接操作磁盤文件,不需要內核進行中轉呢?有,那就是建立直接緩沖區了。
非直接緩沖區:非直接緩沖區就是我們上面所講內核態作為中間人,每次都需要內核在中間作為中轉。
直接緩沖區:直接緩沖區不需要內核空間作為中轉copy數據,而是直接在物理內存申請一塊空間,這塊空間映射到內核地址空間和用戶地址空間,應用程序與磁盤之間數據的存取通過這塊直接申請的物理內存進行交互。
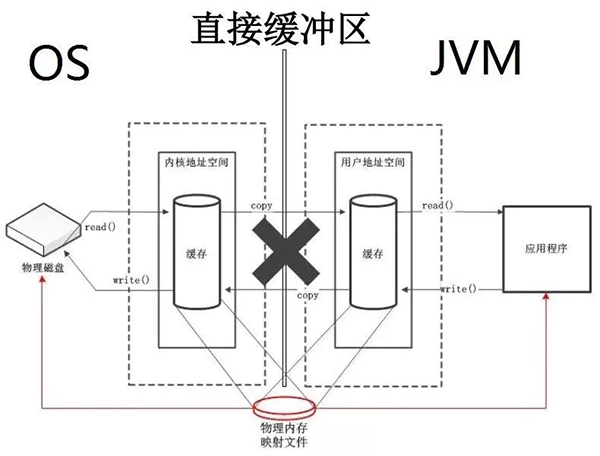
既然直接緩沖區那么快,我們為什么不都用直接緩沖區呢?其實直接緩沖區有以下的缺點。直接緩沖區的缺點:
1、不安全
2、消耗更多,因為它不是在JVM中直接開辟空間。這部分內存的回收只能依賴于垃圾回收機制,垃圾什么時候回收不受我們控制。
3、數據寫入物理內存緩沖區中,程序就喪失了對這些數據的管理,即什么時候這些數據被最終寫入從磁盤只能由操作系統來決定,應用程序無法再干涉。
綜上所述,所以我們使用 transferTo方法就是直接開辟了一段直接緩沖區。所以性能相比而言提高了許多
使用內存映射文件
NIO中新出的另一個特性就是內存映射文件,內存映射文件為什么速度快呢?其實原因和上面所講的一樣,也是在內存中開辟了一段直接緩沖區。與數據直接作交互。源碼如下
- //Version 4 使用Map映射文件
- public static void zipFileMap() {
- //開始時間
- long beginTime = System.currentTimeMillis();
- File zipFile = new File(ZIP_FILE);
- try (ZipOutputStream zipOut = new ZipOutputStream(new FileOutputStream(zipFile));
- WritableByteChannel writableByteChannel = Channels.newChannel(zipOut)) {
- for (int i = 0; i < 10; i++) {
- zipOut.putNextEntry(new ZipEntry(i + SUFFIX_FILE));
- //內存中的映射文件
- MappedByteBuffer mappedByteBuffer = new RandomAccessFile(JPG_FILE_PATH, "r").getChannel()
- .map(FileChannel.MapMode.READ_ONLY, 0, FILE_SIZE);
- writableByteChannel.write(mappedByteBuffer);
- }
- printInfo(beginTime);
- } catch (Exception e) {
- e.printStackTrace();
- }
- }
打印如下
- ---------Map
- fileSize:20M
- consum time:1305
可以看到速度和使用Channel的速度差不多的。
使用Pipe
Java NIO 管道是2個線程之間的單向數據連接。Pipe有一個source通道和一個sink通道。其中source通道用于讀取數據,sink通道用于寫入數據。可以看到源碼中的介紹,大概意思就是寫入線程會阻塞至有讀線程從通道中讀取數據。如果沒有數據可讀,讀線程也會阻塞至寫線程寫入數據。直至通道關閉。
- Whether or not a thread writing bytes to a pipe will block until another
- thread reads those bytes
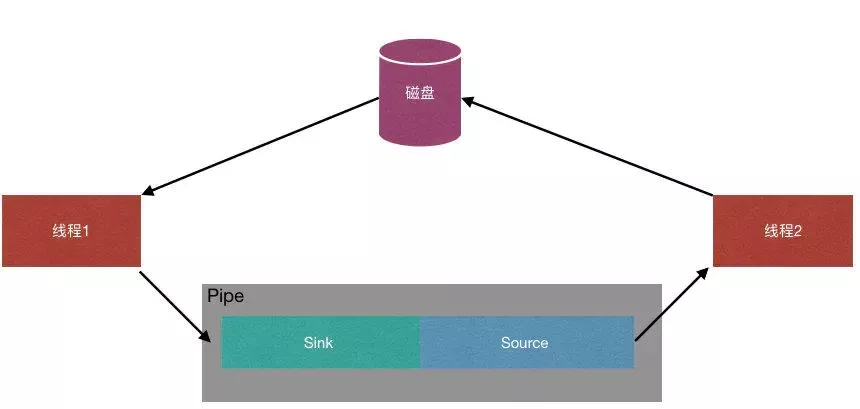
我想要的效果是這樣的。源碼如下
- //Version 5 使用Pip
- public static void zipFilePip() {
- long beginTime = System.currentTimeMillis();
- try(WritableByteChannel out = Channels.newChannel(new FileOutputStream(ZIP_FILE))) {
- Pipe pipe = Pipe.open();
- //異步任務
- CompletableFuture.runAsync(()->runTask(pipe));
- //獲取讀通道
- ReadableByteChannel readableByteChannel = pipe.source();
- ByteBuffer buffer = ByteBuffer.allocate(((int) FILE_SIZE)*10);
- while (readableByteChannel.read(buffer)>= 0) {
- buffer.flip();
- out.write(buffer);
- buffer.clear();
- }
- }catch (Exception e){
- e.printStackTrace();
- }
- printInfo(beginTime);
- }
- //異步任務
- public static void runTask(Pipe pipe) {
- try(ZipOutputStream zos = new ZipOutputStream(Channels.newOutputStream(pipe.sink()));
- WritableByteChannel out = Channels.newChannel(zos)) {
- System.out.println("Begin");
- for (int i = 0; i < 10; i++) {
- zos.putNextEntry(new ZipEntry(i+SUFFIX_FILE));
- FileChannel jpgChannel = new FileInputStream(new File(JPG_FILE_PATH)).getChannel();
- jpgChannel.transferTo(0, FILE_SIZE, out);
- jpgChannel.close();
- }
- }catch (Exception e){
- e.printStackTrace();
- }
- }
總結
生活處處都需要學習,有時候只是一個簡單的優化,可以讓你深入學習到各種不同的知識。所以在學習中要不求甚解,不僅要知道這個知識也要了解為什么要這么做。
知行合一:學習完一個知識要盡量應用一遍。這樣才能記得牢靠。
源碼地址
https://github.com/modouxiansheng/Doraemon