如何用 Python 預測房價走勢?
該分享源于Udacity機器學習進階中的一個mini作業項目,用于入門非常合適,刨除了繁瑣的部分,保留了最關鍵、基本的步驟,能夠對機器學習基本流程有一個最清晰的認識。

項目描述
利用馬薩諸塞州波士頓郊區的房屋信息數據訓練和測試一個模型,并對模型的性能和預測能力進行測試;
項目分析
數據集字段解釋:
- RM: 住宅平均房間數量;
- LSTAT: 區域中被認為是低收入階層的比率;
- PTRATIO: 鎮上學生與教師數量比例;
- MEDV: 房屋的中值價格(目標特征,即我們要預測的值);
其實現在回過頭來看,前三個特征應該都是挖掘后的組合特征,比如RM,通常在原始數據中會分為多個特征:一樓房間、二樓房間、廚房、臥室個數、地下室房間等等,這里應該是為了教學簡單化了;
MEDV為我們要預測的值,屬于回歸問題,另外數據集不大(不到500個數據點),小數據集上的回歸問題,現在的我初步考慮會用SVM,稍后讓我們看看當時的選擇;
Show Time
Step 1 導入數據
注意點:
- 如果數據在多個csv中(比如很多銷售項目中,銷售數據和店鋪數據是分開兩個csv的,類似數據庫的兩張表),這里一般要連接起來;
- 訓練數據和測試數據連接起來,這是為了后續的數據處理的一致,否則訓練模型時會有問題(比如用訓練數據訓練的模型,預測測試數據時報錯維度不一致);
- 觀察下數據量,數據量對于后續選擇算法、可視化方法等有比較大的影響,所以一般會看一下;
- pandas內存優化,這一點項目中目前沒有,但是我最近的項目有用到,簡單說一下,通過對特征字段的數據類型向下轉換(比如int64轉為int8)降低對內存的使用,這里很重要,數據量大時很容易撐爆個人電腦的內存存儲;
上代碼:
- # 載入波士頓房屋的數據集
- data = pd.read_csv('housing.csv')
- prices = data['MEDV']
- features = data.drop('MEDV', axis =1)
- # 完成
- print"Boston housing dataset has {} data points with {} variables each.".format(*data.shape)
Step 2 分析數據
加載數據后,不要直接就急匆匆的上各種處理手段,加各種模型,先慢一點,對數據進行一個初步的了解,了解其各個特征的統計值、分布情況、與目標特征的關系,最好進行可視化,這樣會看到很多意料之外的東西;
基礎統計運算
統計運算用于了解某個特征的整體取值情況,它的最大最小值,平均值中位數,百分位數等等,這些都是最簡單的對一個字段進行了解的手段;
上代碼:
- #目標:計算價值的最小值
- minimum_price = np.min(prices)# prices.min
- #目標:計算價值的最大值
- maximum_price = np.max(prices)# prices.max
- #目標:計算價值的平均值
- mean_price = np.mean(prices)# prices.mean
- #目標:計算價值的中值
- median_price = np.median(prices)# prices.median
- #目標:計算價值的標準差
- std_price = np.std(prices)# prices.std
特征觀察
這里主要考慮各個特征與目標之間的關系,比如是正相關還是負相關,通常都是通過對業務的了解而來的,這里就延伸出一個點,機器學習項目通常來說,對業務越了解,越容易得到好的效果,因為所謂的特征工程其實就是理解業務、深挖業務的過程;
比如這個問題中的三個特征:
- RM:房間個數明顯應該是與房價正相關的;
- LSTAT:低收入比例一定程度上表示著這個社區的級別,因此應該是負相關;
- PTRATIO:學生/教師比例越高,說明教育資源越緊缺,也應該是負相關;
上述這三個點,同樣可以通過可視化的方式來驗證,事實上也應該去驗證而不是只靠主觀猜想,有些情況下,主觀感覺與客觀事實是完全相反的,這里要注意;
Step 3 數據劃分
為了驗證模型的好壞,通常的做法是進行cv,即交叉驗證,基本思路是將數據平均劃分N塊,取其中N-1塊訓練,并對另外1塊做預測,并比對預測結果與實際結果,這個過程反復N次直到每一塊都作為驗證數據使用過;
上代碼:
- # 提示:導入train_test_split
- fromsklearn.model_selectionimporttrain_test_split
- X_train, X_test, y_train, y_test = train_test_split(features, prices, test_size=0.2, random_state=RANDOM_STATE)
- printX_train.shape
- printX_test.shape
- printy_train.shape
- printy_test.shape
Step 4 定義評價函數
這里主要是根據問題來定義,比如分類問題用的最多的是準確率(精確率、召回率也有使用,具體看業務場景中更重視什么),回歸問題用RMSE(均方誤差)等等,實際項目中根據業務特點經常會有需要去自定義評價函數的時候,這里就比較靈活;
Step 5 模型調優
通過GridSearch對模型參數進行網格組合搜索最優,注意這里要考慮數據量以及組合后的可能個數,避免運行時間過長哈。
上代碼:
- fromsklearn.model_selectionimportKFold,GridSearchCV
- fromsklearn.treeimportDecisionTreeRegressor
- fromsklearn.metricsimportmake_scorer
- deffit_model(X, y):
- """ 基于輸入數據 [X,y],利于網格搜索找到最優的決策樹模型"""
- cross_validator = KFold
- regressor = DecisionTreeRegressor
- params = {'max_depth':[1,2,3,4,5,6,7,8,9,10]}
- scoring_fnc = make_scorer(performance_metric)
- grid = GridSearchCV(estimator=regressor, param_grid=params, scoring=scoring_fnc, cv=cross_validator)
- # 基于輸入數據 [X,y],進行網格搜索
- grid = grid.fit(X, y)
- # 返回網格搜索后的最優模型
- returngrid.best_estimator_
可以看到當時項目中選擇的是決策樹模型,現在看,樹模型在這種小數據集上其實是比較容易過擬合的,因此可以考慮用SVM代替,你也可以試試哈,我估計是SVM效果比較好;
學習曲線
通過繪制分析學習曲線,可以對模型當前狀態有一個基本了解,如下圖:
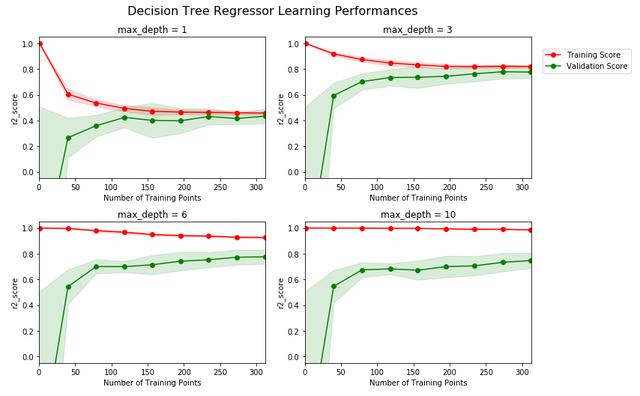
可以看到,超參數max_depth為1和3時,明顯訓練分數過低,這說明此時模型有欠擬合的情況,而當max_depth為6和10時,明顯訓練分數和驗證分析差距過大,說明出現了過擬合,因此我們初步可以猜測,優質參數在3和6之間,即4,5中的一個,其他參數一樣可以通過學習曲線來進行可視化分析,判斷是欠擬合還是過擬合,再分別進行針對處理;
小結
通過以上的幾步,可以非常簡單、清晰的看到一個機器學習項目的全流程,其實再復雜的流程也是這些簡單步驟的一些擴展,而更難的往往是對業務的理解,沒有足夠的理解很難得到好的結果,體現出來就是特征工程部分做的好壞,這里就需要各位小伙伴們奮發圖強了,路漫漫啊。
項目鏈接
- 通篇瀏覽可以通過nbviewer來看;
- 項目源文件、數據集文件可以通過GitHub波士頓項目獲取,歡迎Follow、Fork、Star;