













模型聽人講幾句就能學(xué)得更好?斯坦福提出用語言解釋輔助學(xué)習(xí)
語言是人與人之間最自然的溝通方式,能幫助我們傳遞很多重要的信息。斯坦福大學(xué)人工智能實驗室(SAIL)近日發(fā)表博客,介紹了其兩篇 ACL 2020 論文。這兩項研究立足于近段時間 BERT 等神經(jīng)語言模型的突破性成果,指出了一個頗具潛力的新方向:使用語言解釋來輔助學(xué)習(xí) NLP 乃至計算機(jī)視覺領(lǐng)域的任務(wù)。
想象一下:如果你是一位機(jī)器學(xué)習(xí)從業(yè)者并想要解決某個分類問題,比如將彩色方塊群分類為 1 或 0。你通常會這樣做:收集一個包含大量樣本的數(shù)據(jù)集,標(biāo)注數(shù)據(jù),然后訓(xùn)練一個分類器。

但人類的學(xué)習(xí)方式卻并非如此。對于這個世界,人類有一種非常強(qiáng)大且直觀的信息溝通機(jī)制:語言!

只需一個短語「at least 2 red squares(至少兩個紅方塊)」,我們就能歸納上面的整個數(shù)據(jù)集,而且效率要高得多。
語言是人類學(xué)習(xí)的一大關(guān)鍵媒介:我們使用語言來傳遞關(guān)于這個世界的信念、教育他人以及描述難以直接體驗的事物。因此,對監(jiān)督式機(jī)器學(xué)習(xí)模型而言,語言理應(yīng)是一種簡單且有效的方法。但是,過去基于語言的學(xué)習(xí)方法都難以擴(kuò)展到現(xiàn)代深度學(xué)習(xí)系統(tǒng)致力于解決的一般任務(wù),而這些領(lǐng)域使用的語言形式往往很自由。
今年斯坦福大學(xué) AI 實驗室(SAIL)的兩篇 ACL 2020 論文在這一研究方向上取得了一些進(jìn)展:針對自然語言處理(NLP)和計算機(jī)視覺領(lǐng)域的多種高難度任務(wù),他們首先用語言解釋這些任務(wù),然后使用深度神經(jīng)網(wǎng)絡(luò)模型來學(xué)習(xí)這些語言解釋,進(jìn)而幫助解決這些任務(wù)。
ExpBERT: Representation Engineering with Natural Language Explanations
Shaping Visual Representations with Language for Few-shot Classification
難在哪里?
對人類而言,語言是一種教授他人的直觀媒介,但為何使用語言來執(zhí)行機(jī)器學(xué)習(xí)會這么難?
主要的難題也是最基本的問題:在其它輸入的語境中理解語言解釋。光是構(gòu)建能夠理解豐富和模糊語言的模型就已經(jīng)很難了,而構(gòu)建能將語言與周圍世界關(guān)聯(lián)起來的模型還要更難。舉個例子,給定解釋「at least 2 red squares(至少兩個紅方塊)」,模型不僅要理解什么是「red(紅)」和「squares(方塊)」,還要理解它們?nèi)绾沃复溯斎氲奶囟ú糠郑ㄍǔ:軓?fù)雜)。
過去一些研究依靠語義解析器來將自然語言陳述(比如 at least 2 red squares)轉(zhuǎn)換為形式化的邏輯表征(比如 Count(Square AND Red) > 2))。如果我們可以輕松地通過執(zhí)行這些邏輯公式來檢查解釋是否適用于輸入,則可以將解釋用作特征來訓(xùn)練模型。但是,語義解析器僅對簡單的領(lǐng)域有效,因為簡單我們才能人工設(shè)計可能見到語言解釋的邏輯語法。它們難以處理更豐富和更模糊的語言,也難以擴(kuò)展用于更復(fù)雜的輸入,比如圖像。
幸運(yùn)的是,BERT 等現(xiàn)代深度神經(jīng)語言模型已經(jīng)顯現(xiàn)出解決多項語言理解任務(wù)的潛力。因此,SAIL 在這兩篇論文中提出使用神經(jīng)語言模型來緩解這些基本問題。這些神經(jīng)語言模型或以確定相關(guān)領(lǐng)域內(nèi)語言解釋為目標(biāo),或使用了可以解讀語言解釋的通用型「知識」來進(jìn)行預(yù)訓(xùn)練。下面將詳細(xì)地介紹這些神經(jīng)語言模型,看它們?nèi)绾文茉诟惶魬?zhàn)性的任務(wù)設(shè)置中學(xué)習(xí)更豐富且更多樣化的語言。
ExpBERT:使用自然語言解釋來設(shè)計和創(chuàng)建表征

論文地址:https://arxiv.org/abs/2005.01932
第一篇論文研究了如何使用語言解釋來構(gòu)建文本分類器。首先來看一個關(guān)系提取任務(wù):模型需要根據(jù)一小段文本識別其中提到的兩個人是否已經(jīng)結(jié)婚。盡管當(dāng)前最佳的 NLP 模型有可能僅基于數(shù)據(jù)來解決這一任務(wù),但人類還能通過語言描述來暗示兩人是否已經(jīng)結(jié)婚,比如度蜜月的人通常是已婚的。這樣的語言解釋能用于訓(xùn)練更好的分類器嗎?

對于語言任務(wù),我們可以提取輸入 x 的特征(比如是否出現(xiàn)了特定詞)來訓(xùn)練模型,而解釋還能提供額外的特征。仍以上述任務(wù)為例,我們知道「蜜月(honeymoon)」是相關(guān)的語言描述,如果我們能創(chuàng)建一個蜜月特征,并使其在段落描述到兩人將要度蜜月時激活,則這個信號應(yīng)該可用于訓(xùn)練更好的模型。
但創(chuàng)建這樣的特征需要某種解釋解讀機(jī)制(explanation interpretation mechanism),這樣模型才能知道對輸入的解釋是否為真。語義解析器就是這樣一種工具:給定「A 和 B 正在度蜜月」,我們可以將這個解釋解析成一種邏輯形式,即當(dāng)分析一個輸入時,如果在提到 A 和 B 時還提到了「蜜月」,則返回 1。但如果解釋更模糊呢?比如「A 和 B 很恩愛」。我們?nèi)绾谓馕鏊?/p>
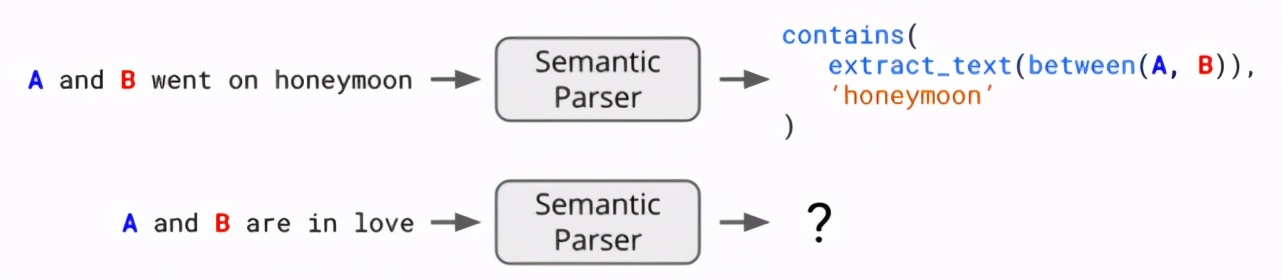
盡管語義解析在領(lǐng)域較小時高效且準(zhǔn)確,但擴(kuò)展性能很差,因為它只能解讀遵循固定語法規(guī)則集和預(yù)定義函數(shù)(比如 contains 和 extract_text)的解釋。為了解決這些問題,SAIL 的研究者看中了神經(jīng)語言模型 BERT 的軟推理能力。BERT 在文本蘊(yùn)涵任務(wù)上尤其高效,即確定一個句子是否暗含另一個句子或與另一個句子有矛盾。比如「她吃了披薩」暗含「她吃了食物」。
SAIL 提出的 ExpBERT 模型使用了針對文本蘊(yùn)涵任務(wù)訓(xùn)練的 BERT 模型,但研究者為其設(shè)定的訓(xùn)練目標(biāo)是識別任務(wù)段落里是否蘊(yùn)涵一個解釋。BERT 在這一過程中輸出的特征可替代上述語義解析器提供的指示特征。

BERT 的這種軟推理能力能否提升語義解析效果?在上面的婚姻識別任務(wù)中,研究者發(fā)現(xiàn)相較于僅使用輸入特征(無解釋)訓(xùn)練得到的分類器,ExpBERT 能帶來顯著提升。其中重要的一點(diǎn)是:使用語義解析器來解析解釋的作用不大,因為一般性的解釋(恩愛)難以轉(zhuǎn)換為邏輯形式。
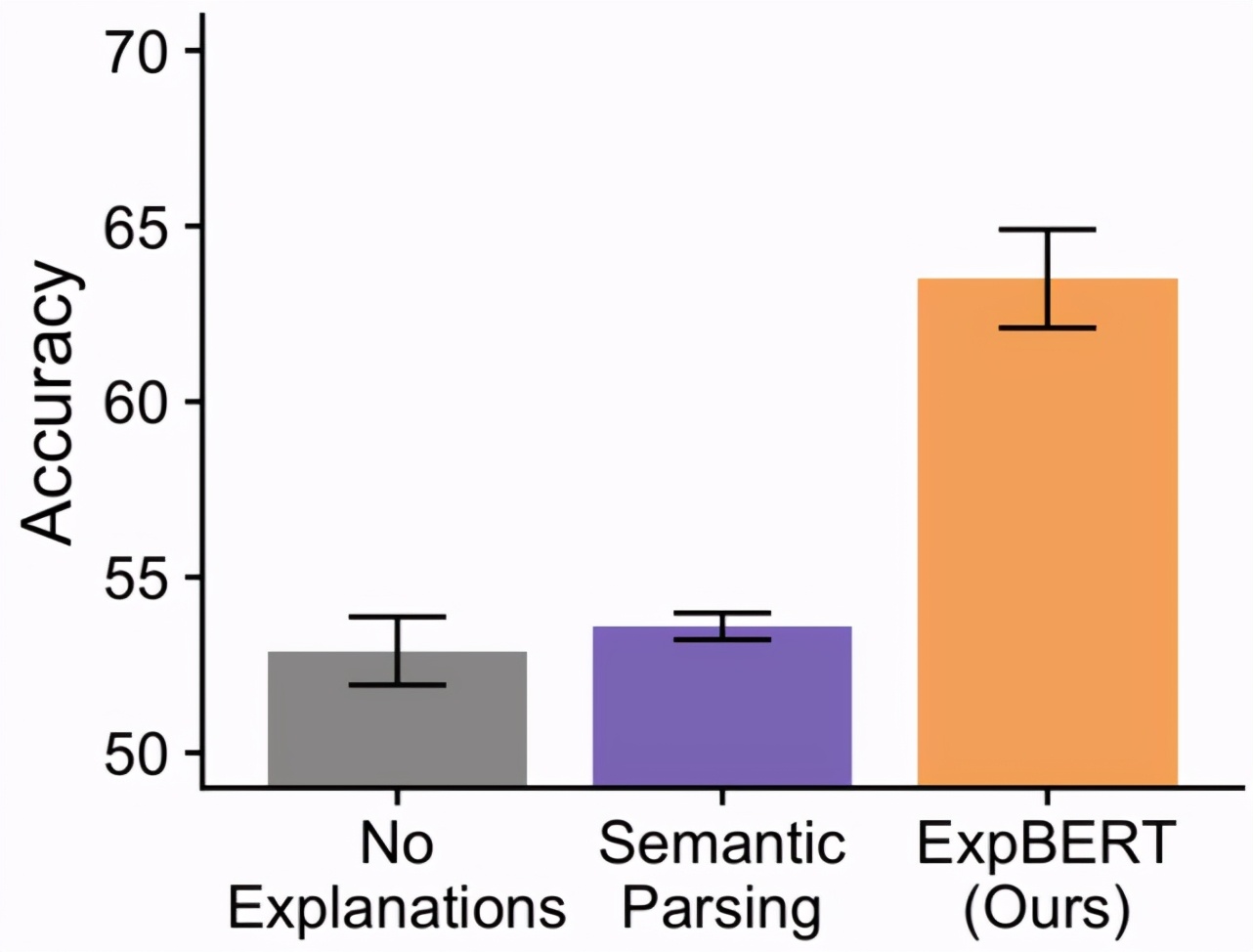
論文還比較了更多基準(zhǔn)方法,探索了更大的關(guān)系提取任務(wù)(如 TACRED),執(zhí)行了控制變量研究,研究了使用解釋相比于添加數(shù)據(jù)的高效性。此處不再贅述。
使用語言為少次分類任務(wù)塑造視覺表征

論文地址:https://arxiv.org/abs/1911.02683
上文描述的研究使用自然語言解釋來幫助解決單個任務(wù),比如識別婚姻狀況。但是,認(rèn)知科學(xué)領(lǐng)域的研究表明:語言還能讓我們獲取正確的特征和抽象概念,進(jìn)而幫助我們解決未來的任務(wù)。例如,能說明 A 和 B 已婚的語言解釋還能說明其它一些對人類關(guān)系而言非常重要的概念:孩子、女兒、蜜月等等。知道這些額外概念不僅有助于識別已婚夫婦,還有助于幫助識別其它關(guān)系,比如兄弟姐妹、父母等。
在機(jī)器學(xué)習(xí)中,我們可能會問:如果我們最終希望解決的新任務(wù)沒有提供語言說明,語言如何為高難度且未指明的領(lǐng)域提供恰當(dāng)?shù)奶卣鳎縎AIL 的第二篇論文便探索了這一任務(wù)設(shè)置,這個任務(wù)的難度更大:語言能否提升跨模態(tài)(這里是視覺)的表征學(xué)習(xí)?
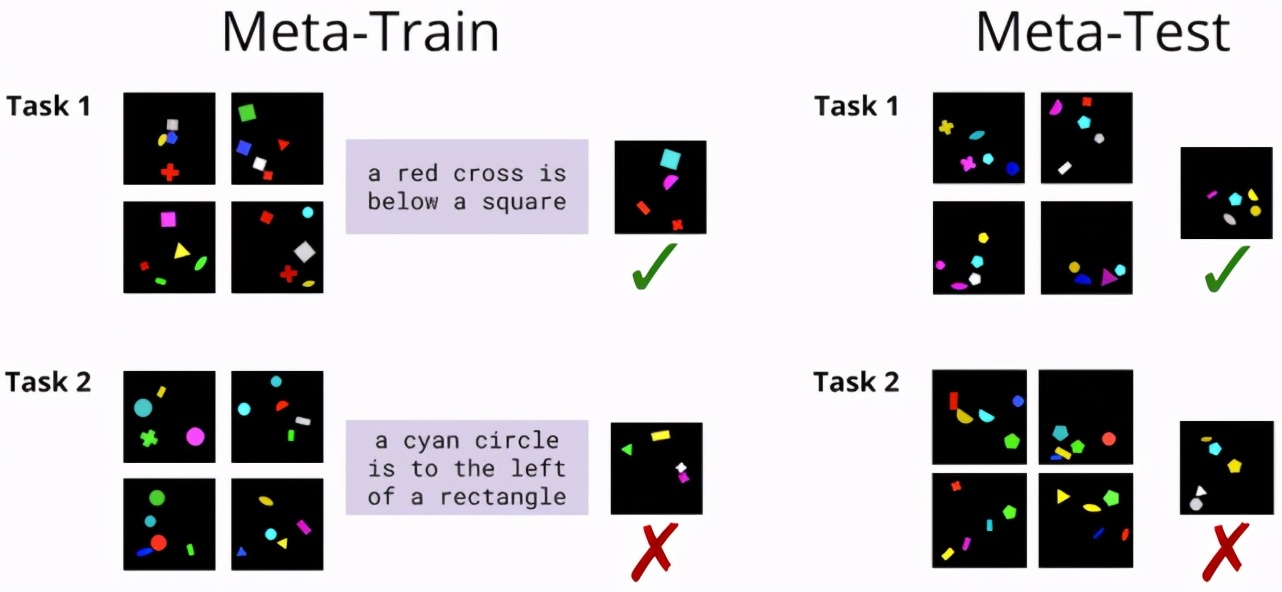
具體來說,該研究重點(diǎn)關(guān)注的是少次視覺推理任務(wù),比如下面這個來自 ShapeWorld 數(shù)據(jù)集的例子:

針對一個視覺概念給定一個小型訓(xùn)練樣本集,任務(wù)目標(biāo)是確定留出集的測試圖像是否表達(dá)了同樣的概念。現(xiàn)在,如果假設(shè)能在訓(xùn)練時間獲得相關(guān)視覺概念的語言解釋,又會如何呢?我們能否使用它們來學(xué)習(xí)一個更好的模型,即便在測試時沒有語言可用?
SAIL 的研究者將該任務(wù)放到了一個元學(xué)習(xí)任務(wù)框架中:他們沒有在單個任務(wù)上訓(xùn)練和測試模型,而是選擇了在一組任務(wù)上訓(xùn)練模型,其中每個任務(wù)都有一個小型訓(xùn)練集和配套的語言描述(元訓(xùn)練集 / meta-train set)。然后,他們在一組未見過任務(wù)組成的元測試集(meta-test set)上測試模型的泛化能力,并且該測試集沒有可用的語言描述。
首先,如果沒有語言描述,我們會如何解決這一任務(wù)?一種典型的方法是原型網(wǎng)絡(luò)(Prototype Network),其策略是學(xué)習(xí)某個能對訓(xùn)練圖像執(zhí)行嵌入、求平均并將其與測試圖像的嵌入進(jìn)行對比的模型 f_θ(在這里是一個深度卷積神經(jīng)網(wǎng)絡(luò)):

在此基礎(chǔ)上,為了使用語言,SAIL 提出一種名為語言塑造型學(xué)習(xí)(Language Shaped Learning/LSL)的方法:如果能在訓(xùn)練時使用語言解釋,則可以促使模型學(xué)習(xí)不僅對分類有用的表征,而且該表征還能用于預(yù)測語言解釋。SAIL 采用的具體方案是引入一個輔助訓(xùn)練目標(biāo)(即與最終的目標(biāo)任務(wù)無關(guān)),同時訓(xùn)練一個循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)解碼器來預(yù)測對輸入圖像表征的語言解釋。有一點(diǎn)至關(guān)重要,即這個解碼器的訓(xùn)練過程取決于圖像模型 f_θ 的參數(shù),因此該過程應(yīng)該能促使 f_θ 更好地編碼語言中顯現(xiàn)的特征和抽象。
從效果上看,可以說這是訓(xùn)練模型在訓(xùn)練期間表征概念時「把想法大聲說出來」。在測試階段,則可以直接拋棄 RNN 解碼器,使用這個「經(jīng)過語言塑造的」圖像嵌入按常規(guī)方式執(zhí)行分類即可。
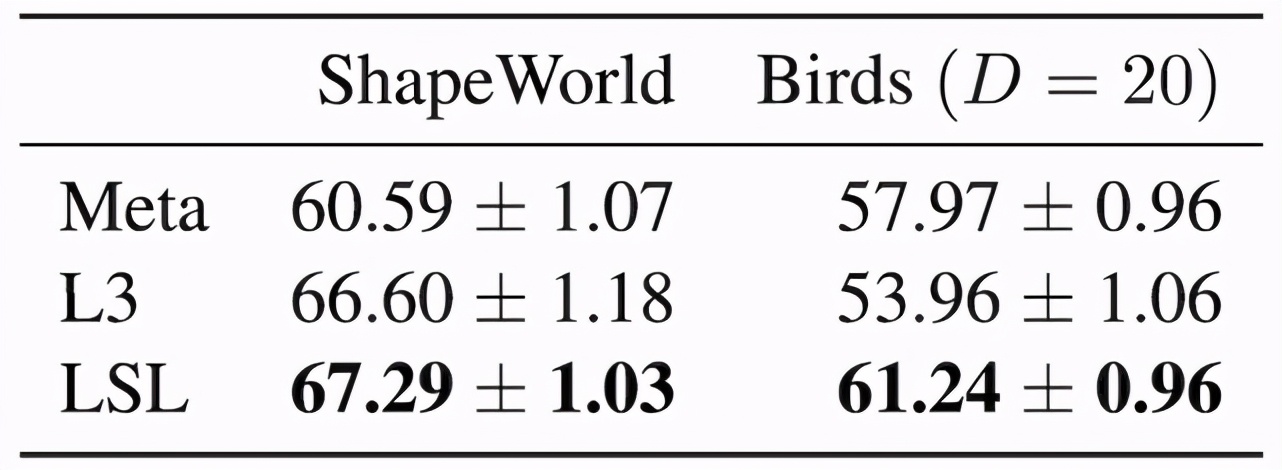
研究者使用真實圖像和人類語言,在上述 ShapeWorld 數(shù)據(jù)集以及更真實的 Birds 數(shù)據(jù)集上進(jìn)行了測試:

在這兩種情況下,相對于無語言解釋的基準(zhǔn)模型(Meta)、使用隱含語言的學(xué)習(xí)(L3)方法,這個輔助訓(xùn)練目標(biāo)實現(xiàn)了性能提升:
此外,該論文還研究了語言的哪些部分最重要(其實差不多都挺重要),以及 LSL 需要多少語言才能取得優(yōu)于無語言模型的表現(xiàn)(其實只需一點(diǎn)點(diǎn))。詳情請參閱原論文。
展望未來
正如 NLP 系統(tǒng)理解和生成語言的能力在日益增長一樣,機(jī)器學(xué)習(xí)系統(tǒng)基于語言學(xué)習(xí)解決其它高難度任務(wù)的潛力也在增長。SAIL 的這兩篇論文表明,在視覺與 NLP 領(lǐng)域的多種不同類型任務(wù)上,通過學(xué)習(xí)語言解釋,深度神經(jīng)語言模型可成功提升泛化能力。
研究者指出,這是訓(xùn)練機(jī)器學(xué)習(xí)模型方面一個激動人心的新途徑,而且強(qiáng)化學(xué)習(xí)等領(lǐng)域已經(jīng)對一些類似的想法進(jìn)行了探索。在他們的設(shè)想中,未來在解決機(jī)器學(xué)習(xí)任務(wù)時,我們無需再收集大量有標(biāo)注數(shù)據(jù)集,而是可以通過人與人之間使用了成千上萬年的互動方式——「語言」來與模型進(jìn)行自然且富有表達(dá)力的交互。
























