













思維鏈提出者Jason Wei:關于大模型的六個直覺
還記得 Jason Wei 嗎?這位思維鏈的提出者還曾共同領導了指令調優的早期工作,并和 Yi Tay、Jeff Dean 等人合著了關于大模型涌現能力的論文。目前他正在 OpenAI 參與 ChatGPT 的開發工作。機器之心曾經報道過他為年輕 AI 研究者提供的一些建議。

近日,他以客座講師的身份為斯坦福的 CS 330 深度多任務學習與元學習課程講了一堂課,分享了他對大型語言模型的一些直觀認識。目前斯坦福尚未公布其演講視頻,但他本人已經在自己的博客上總結了其中的主要內容。
當今的 AI 領域有一個仍待解答的問題:大型語言模型的表現為何如此之好?對此,Jason Wei 談到了六個直覺認識。這些直覺認識中許多都是通過人工檢查數據得到的,Jason Wei 表示這是一種非常有幫助的實踐措施,值得推薦。
語言模型的預訓練目標就只是預測文本語料的下一個詞,而它們卻從中學到了許多東西,著實讓人驚訝。它們從下一個詞預測任務中學到了什么呢?下面有一些例子。
直覺 1:基于大規模自監督數據的下一個詞預測是大規模多任務學習
盡管下一個詞預測是非常簡單的任務,但當數據集規模很大時,就會迫使模型學會很多任務。比如下面的傳統 NLP 任務就可以通過預測語料文本的下一個詞來學習。
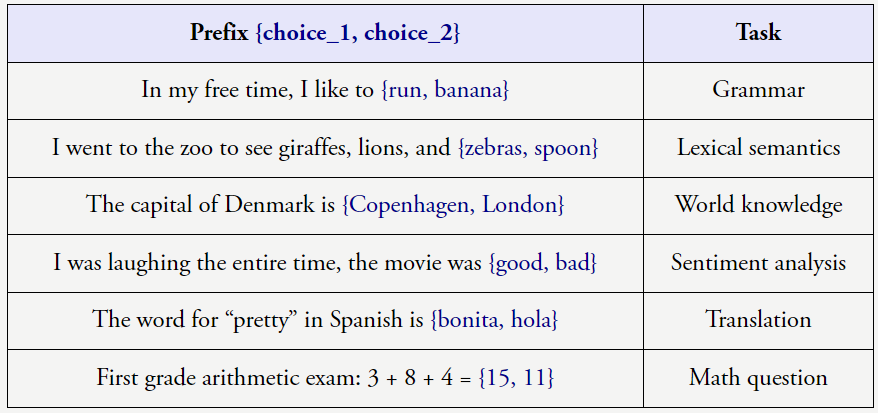
上述任務很明確,但有點理想化。在現實情況中,預測下一個詞還會涉及到很多的「古怪」任務。以下列句子為例:
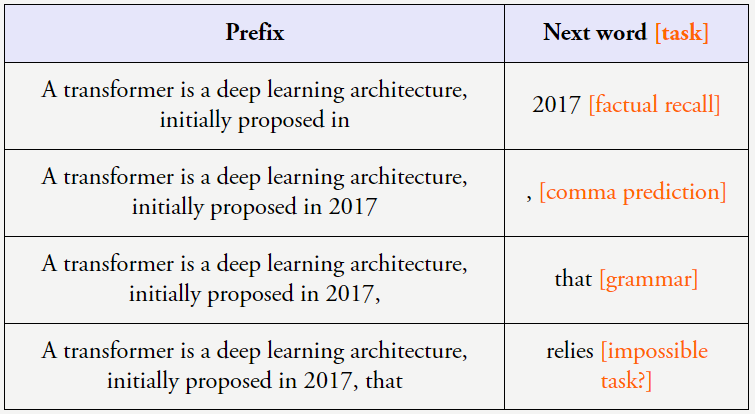
當以這樣的方式看待這些數據時,很明顯下一個詞預測會促使模型學到很多有關語言的東西,而不只是句法和語義,還包括標點符號預測、事實預測、甚至是推理。這些例子能夠佐證這一觀點:簡單目標加上復雜數據可以帶來高度智能的行為(如果你認同語言模型是智能的)。
直覺 2:學習輸入 - 輸出關系的任務可以被視為下一個詞預測任務,這也被稱為上下文學習
過去幾十年,機器學習領域的重點就是學習 < 輸入,輸出 > 對的關系。由于下一個詞預測非常普適,因此我們可以輕松地把機器學習視為下一個詞預測。我們把這稱為上下文學習(也稱少樣本學習或少樣本提示工程)。這一領域的先驅研究是 GPT-3 論文,其中提出在自然語言指令后面加上 < 輸入,輸出 > 對。如下左圖所示。
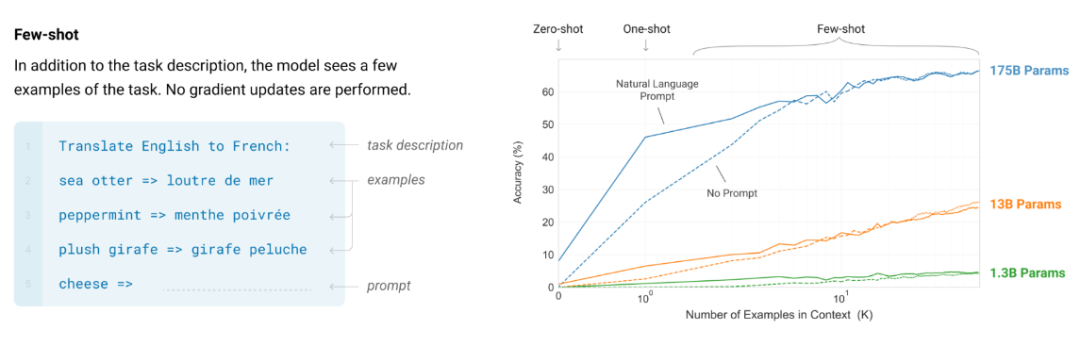
而在上圖右側,則可以看到增加上下文中的示例數量可以提升 GPT-3 論文中任務的性能。這意味著,為模型提供 < 輸入,輸出 > 示例是有好處的。
上下文學習是使用大型語言模型的一種標準形式,而且很方便,因為 < 輸入,輸出 > 對就是過去幾十年人們執行機器學習的方式。但是,我們為什么應當繼續采用 < 輸入,輸出 > 對呢?我們還沒有第一性原理的原因。當我們與人類交流時,我們也會向他們提供指示和解釋,并以互動方式教導他們。
直覺 3:token 可能有非常不同的信息密度,所以請給模型思考的時間
不同 token 的信息量也不同,這是一個基本事實。
一些 token 很容易預測下一個,基本沒多少信息。舉個例子,如果有句子「I’m Jason Wei, a researcher at OpenAI working on large language 」,不難預測下一個詞是「models」。這個 token 的預測是如此得容易,就算是省略它,這句話也不會丟失什么信息。
另一些 token 則極難預測;它們的信息量很大。比如句子「Jason Wei’s favorite color is 」就基本不可能預測正確。因為這個 token 包含大量新信息。
某些 token 也可能很難以計算。比如,在句子「Question:What is the square of ((8-2×3+4)^3/8?(A) 1,483,492; (B) 1,395,394; (C) 1,771,561; Answer: (」中,預測下一個 token 就需要不少工作(計算數學式)。
可以想象一下,如果你是 ChatGPT,你必須一看到 prompt 就馬上開始打字回復,那就很難答對這個問題。
對此的解決方案是為語言模型提供更多計算,讓其執行推理,然后再給出最終答案。這可以通過一個簡單技巧來實現,即思維鏈提示工程,其可以通過提供少樣本「思維鏈」示例來鼓勵模型執行推理,如下圖藍色高亮部分。

這項技術可用于提升在人類也需要些時間來處理的復雜推理任務上的性能。對于比上面的算術問題更復雜的問題,它可以幫助語言模型將 prompt 首先分解成子問題,然后再按順序解決這些子問題(從最少到最多提示工程)。
這種范式非常強大,因為我們希望 AI 最終能解決人類面臨的最困難的問題(例如貧困、氣候變化等),而推理能力是解決此類問題的基本組成部分。
上面的下一詞預測任務之所以有效,關鍵原因是規模,這就意味著要在更多數據上訓練更大的神經網絡。很顯然,訓練前沿語言模型需要花費很多資金,而我們之所以還這么做,是因為我們有信心使用更大的神經網絡和更多數據就能得到更好的模型(即增大模型和數據規模時性能不會飽和)。
直覺 4:預計增大語言模型規模(模型大小和數據)會改善損失
規模擴展可以提升模型性能這一現象被稱為 scaling laws,即擴展律;如下左圖所示,隨著計算量增長,測試損失也會平穩地下降。
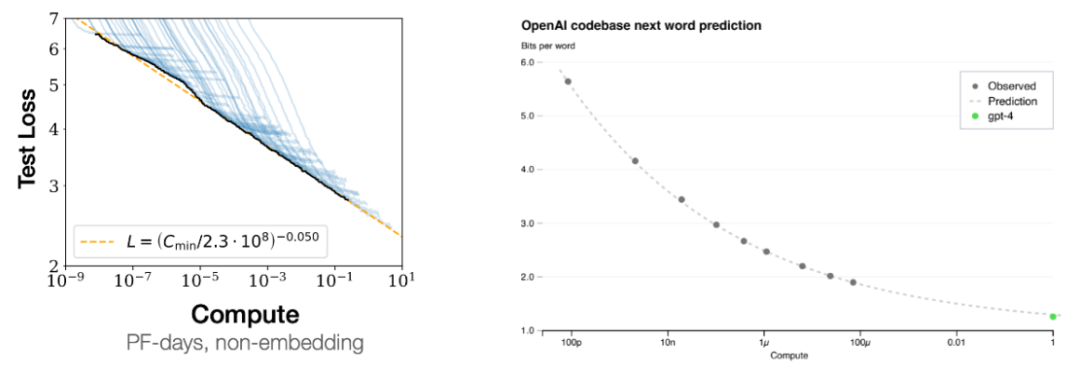
右圖則是另一個證據:通過跟蹤較小模型的損失曲線,你可以使用少一萬倍的計算量來預測 GPT-4 的損失。
擴展規模為何有用還有待解答,但這里有兩個尚待證明的原因。一是小語言模型的參數無法記憶那么多的知識,而大模型可以記憶大量有關世界的事實信息。第二個猜測是小語言模型能力有限,可能只能學習數據中的一階相關性。而大型語言模型則可以學習數據中的復雜啟發式知識。
直覺 5:盡管總體損失會平穩地擴展,但單個下游任務的擴展情況則可能發生突變
我們來看看當損失降低時究竟會發生什么。我們可以將總體損失看作是在所學習的大量任務上的加權平均。
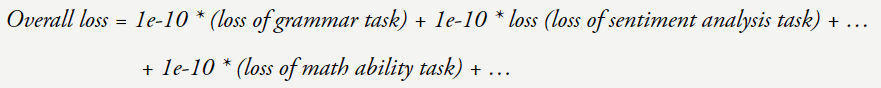
現在假設你的損失從 4 降到了 3。那么你的任務都會變好嗎?可能不會。也許損失 = 4 的模型的語法就已經完美了,因此已經飽和了,但當損失 = 3 時模型的數學能力提升了很多。
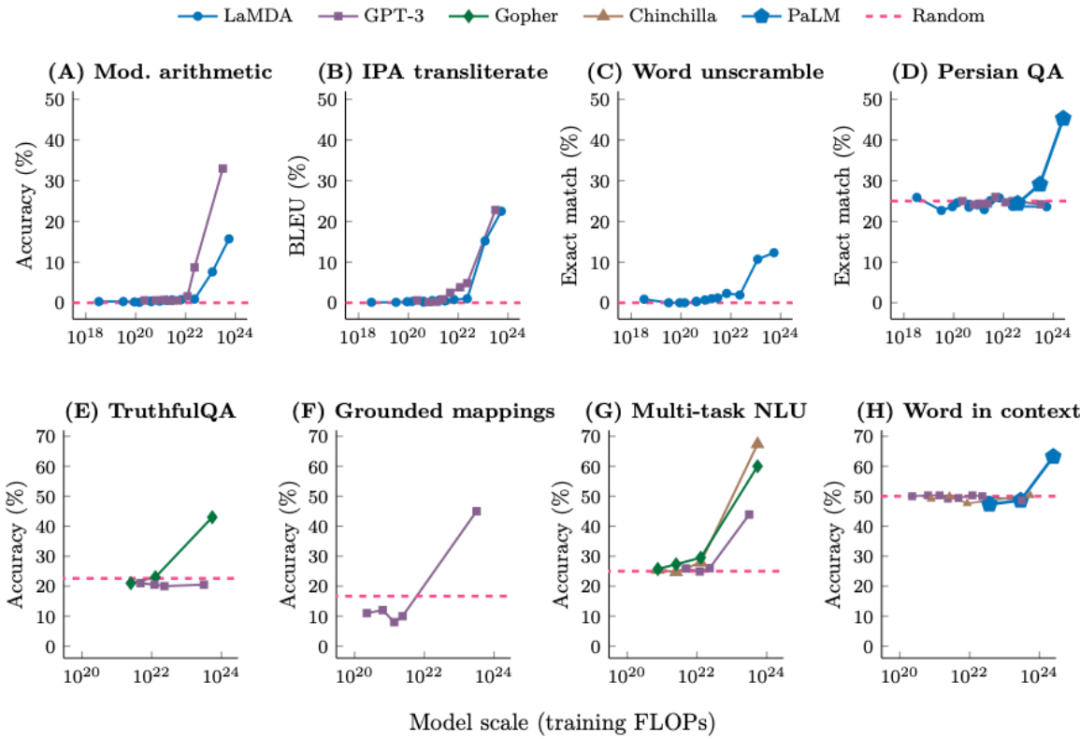
研究表明,如果觀察模型在 200 個下游任務上的性能,你會看到盡管某些任務會平穩地提升,但其它一些任務完全不會提升,還有一些任務則會突然提升。下圖給出了 8 個這類任務的例子,其中模型較小時性能是隨機的,而一旦模型規模到達一定閾值,性能就會顯著超越隨機。
對于這種由量變引起的質變現象,人們稱之為「涌現(emergence)」。更具體而言,如果一個能力在更小的模型中沒有,但更大的模型有,我們就說這個能力是涌現的能力。在這樣的任務中,我們往往可以看到小模型的能力是大致隨機的,而超過一定閾值規模的模型則會顯著超越隨機,如下圖所示。
涌現現象具有三個重要含義:
- 不能簡單地通過外推更小模型的擴展曲線來預測涌現。
- 涌現能力不是語言模型的訓練者明確指定的。
- 由于規模擴展會解鎖涌現能力,因此可以預期進一步擴展還能進一步產生更多能力。
直覺 6:確實是有真正的上下文學習,但只有足夠大的語言模型才行
GPT-3 論文已經告訴我們,增加上下文中的示例數量可以提升性能。盡管我們希望這是因為模型真的從其上下文示例中學習到了 < 輸入,輸出 > 映射關系,但性能的提升還可能會有其它原因,比如示例告訴了模型有關格式或可能標簽的信息。
事實上,論文《Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?》表明,即使為上下文示例使用隨機標簽,GPT-3 的性能也幾乎不會下降。其中認為,性能的提升并非由于學習到了 < 輸入,輸出 > 映射關系,而是由于上下文讓模型了解了格式或可能的標簽。
但是,相比于當今最強大的模型,GPT-3 并非一個「超級」語言模型。如果我們對翻轉標簽(即正表示負,負表示正)采取更極端的設置,那么我們會發現語言模型會更嚴格地遵守翻轉標簽,而小模型則完全不會受到影響。如下圖所示,大型語言模型(PaLM-540B、code-davinci-002 和 text-davinci-002)的能力下降了。
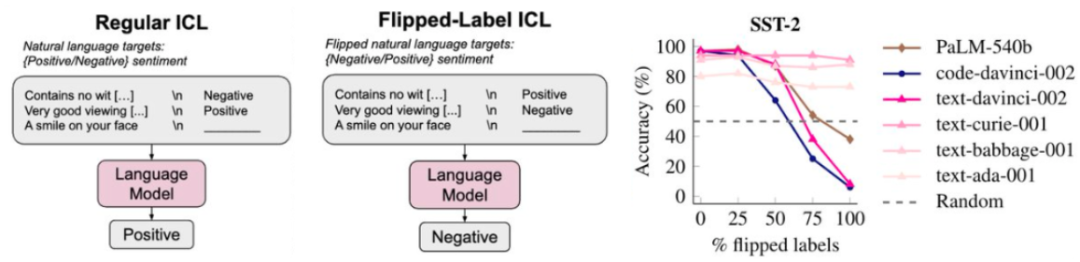
這表明語言模型確實會考慮 < 輸入,輸出 > 映射,但前提是語言模型要足夠大。
在博客最后,Jason Wei 表示,他希望這些直覺是有用的,盡管它們看起來非常基礎。此外,他發現,通過手動查看數據可以學到很多東西,這是他最近很喜歡做的一件事情,推薦大家也嘗試一下。



















