













這就是OpenAI神秘的Q*?斯坦福:語言模型就是Q函數
還記得去年 11 月底爆出來的 Q* 項目嗎?這是傳說中 OpenAI 正在秘密開展、或將帶來顛覆性變革的 AI 項目。如果你想回憶一下,可參看機器之心當時的報道《全網大討論:引爆 OpenAI 全員亂斗的 Q * 到底是什么?》簡而言之,Q* 很可能是 Q 強化學習和 A* 搜索這兩種 AI 方法的結合。
近日,斯坦福大學一個團隊的一項新研究似乎為這一研究方向的潛力提供了佐證,其聲稱現在已經取得非凡成就的「語言模型不是一個獎勵函數,而是一個 Q 函數!」由此發散思維猜想一下,也許 OpenAI 秘密的 Q* 項目或許真的是造就 AGI 的正確方向(或之一)。

- 論文標題:From r to Q?: Your Language Model is Secretly a Q-Function
- 論文地址:https://arxiv.org/pdf/2404.12358.pdf
在對齊大型語言模型(LLM)與人類意圖方面,最常用的方法必然是根據人類反饋的強化學習(RLHF)。通過學習基于人類標注的比較的獎勵函數,RLHF 能夠捕獲實踐中難以描述的復雜目標。研究者們也在不斷探索使用強化學習技術來開發訓練和采樣模型的新算法。尤其是直接對齊方案(比如直接偏好優化,即 DPO)憑借其簡潔性收獲了不少擁躉。
直接對齊方法的操作不是學習獎勵函數然后使用強化學習,而是在上下文多臂賭博機設置(bandit setting)中使用獎勵函數與策略之間的關系來同時優化這兩者。類似的思想已經被用在了視覺 - 語言模型和圖像生成模型中。
盡管有人說這樣的直接對齊方法與使用 PPO 等策略梯度算法的經典 RLHF 方法一樣,但它們之間還是存在根本性差異。
舉個例子,經典 RLHF 方法是使用終點狀態下的稀疏獎勵來優化 token 層面的價值函數。另一方面,DPO 則僅在上下文多臂賭博機設置中執行操作,其是將整個響應當成單條臂處理。這是因為,雖然事實上 token 是一次性只生成一個,但研究強化學習的人都知道,密集型獎勵是有益的。
盡管直接對齊算法頗引人注意,但目前人們還不清楚它們能否像經典強化學習算法那樣用于序列。
為了搞清楚這一點,斯坦福這個團隊近日開展了一項研究:在大型語言模型中 token 層面的 MDP 設置中,使用二元偏好反饋的常見形式推導了 DPO。
他們的研究表明,DPO 訓練會隱含地學習到一個 token 層面的獎勵函數,其中語言模型 logit 定義最優 Q 函數或預期的總未來獎勵。然后,他們進一步表明 DPO 有能力在 token MDP 內靈活地建模任意可能的密集獎勵函數。
這是什么意思呢?
簡單來說,該團隊表明可以將 LLM 表示成 Q 函數并且研究表明 DPO 可以將其與隱式的人類獎勵對齊(根據貝爾曼方程),即在軌跡上的 DPO 損失。
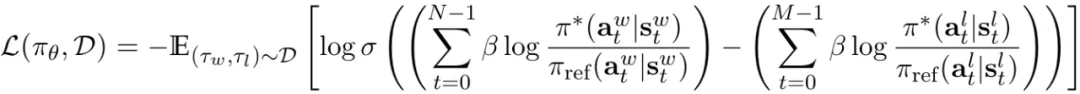
并且他們證明這種表示可以擬合任何在軌跡上的反饋獎勵,包括稀疏信號(如智能體應用)。
實驗
他們也進行了實驗,論證了三個可能對 AI 社區有用的實用見解。
第一,他們的研究表明盡管 DPO 是作為上下文多臂賭博機而派生出來的,但 DPO 模型的隱含獎勵可在每個 token 層面上進行解釋。
在實驗中,他們以定性方式評估了 DPO 訓練的模型是否能夠根據軌跡反饋學習 credit assignment。有一個代表性示例是商討工作就職的場景,圖 1 給出了兩個答案。

其中左邊是正確的基礎摘要,右邊是經過修改的版本 —— 有更高層的職位和相應更高的工資。他們計算了這兩個答案的每個 token 的 DPO 等價的獎勵。圖 1 中的每個 token 標注的顏色就正比于該獎勵。
可以看到,模型能夠成功識別對應于錯誤陳述的 token,同時其它 token 的值依然相差不大,這表明模型可以執行 credit assignment。
此外,還可以看到在第一個錯誤(250K 工資)的上下文中,模型依然為其余 token 分配了合理的值,并識別出了第二個錯誤(management position)。這也許表明模型具備「縫合(stitching)」能力,即根據離線數據進行組合泛化的能力。該團隊表示,如果事實如此,那么這一發現將有助于強化學習和 RLHF 在 LLM 中的應用。
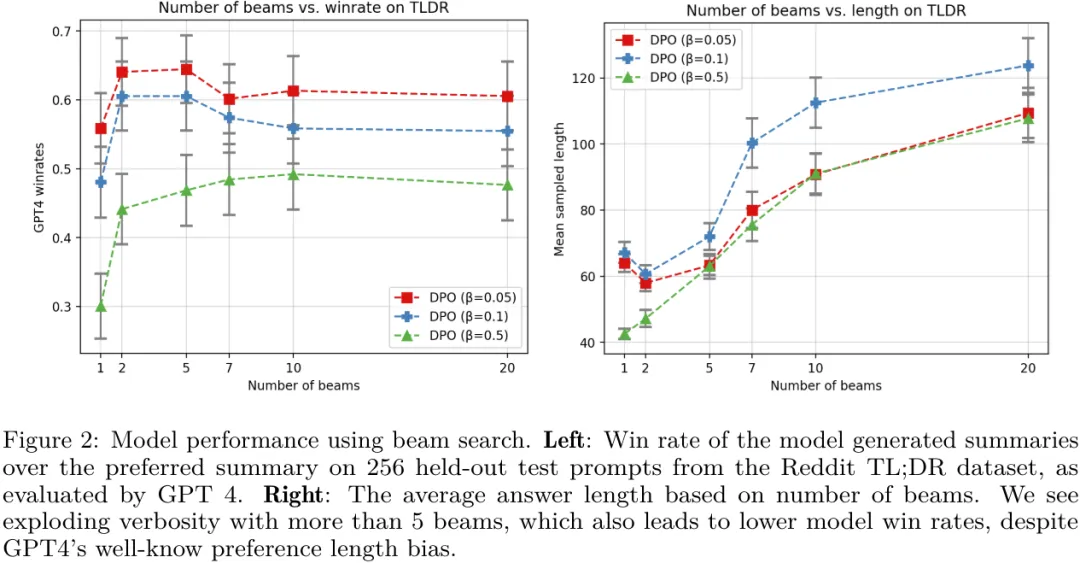
第二,研究表明對 DPO 模型進行似然搜索類似于現在很多研究中在解碼期間搜索獎勵函數。也就是說,他們證明在 token 層面的闡述方式下,經典的基于搜索的算法(比如 MCTS)等價于在 DPO 策略上的基于似然的搜索。他們的實驗表明,一種簡單的波束搜索能為基礎 DPO 策略帶來有意義的提升,見圖 2。
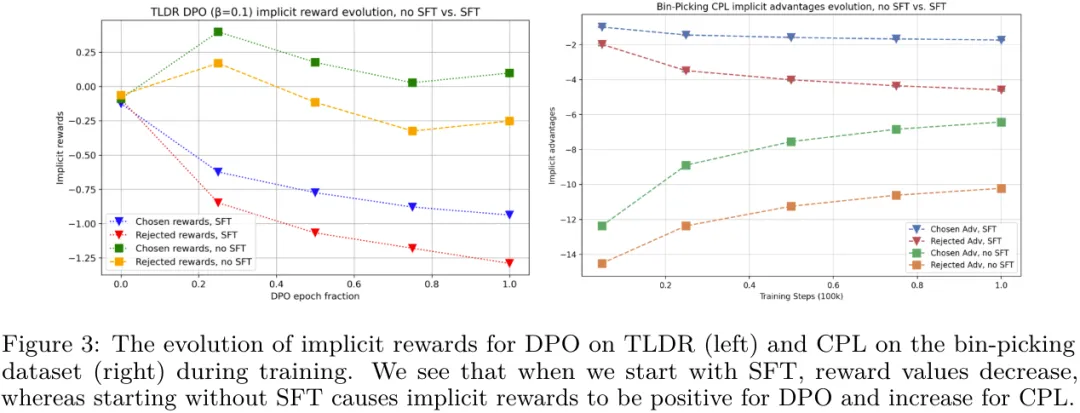
第三,他們確定初始策略和參考分布的選擇對于確定訓練期間隱性獎勵的軌跡非常重要。
從圖 3 可以看出,當在 DPO 之前執行 SFT 時,被選取和被拒絕的響應的隱含獎勵都會下降,但它們的差距會變大。
當然,該團隊最后也表示,這些研究結果還需要更大規模的實驗加以檢驗,他們也給出了一些值得探索的方向,包括使用 DPO 讓 LLM 學會基于反饋學習推理、執行多輪對話、充當智能體、生成圖像和視頻等。





















