20個值得學習的Python技巧
本文為大家介紹20個值得記住的 Python 技巧,可以提升您編程技巧, 并為您節省大量時間。在平常編程過程中,以下技巧大多非常有用。
(原譯文不通順的地方,Python開發者 已做修改優化。)
1 字符串反轉
使用切片反轉字符串。
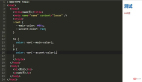
- str1="qwert"
- rev_str1=str1[::-1]
- #輸出
- # trewq
2 使首字母大寫
將字符串轉換為首字母大寫。使用 title()方法完成的。
- str1="this is a book"
- print(str1.title())
- # This Is A Book
3 在字符串中查找唯一元素
下面代碼可用于查找字符串中所有的唯一元素。
- str1="aabbccccdddd"
- setset1=set(str1)
- new_str=''.join(set1)
- print(new_str)
4 重復打印字符串或列表
下面的代碼中,對字符串或列表使用(*)。把字符串或列表復制多次。
- i=4
- str1="abcd"
- list1=[1,2]
- print(str1*i)
- # abcdabcdabcdabcd
- print(list1*i)
- # [1,2,1,2,1,2,1,2]
5 列表推導式
列表推導式為我們提供了一種在其他列表基礎上創建列表的好方法。下面代碼通過將舊列表的每個元素乘以 2 來創建新列表。
- list1=[1,2,3]
- new_list1=[2*i for i in list1]
- # [2,4,6]
6 交換變量
不使用另一個變量,實現變量交換。
- x=1
- y=2
- x,yy=y,x
- print(x) # 2
- print(y) # 1
7 將字符串拆分為子字符串列表
我們使用字符串類中的.split()方法將字符串拆分為子字符串列表,還可以將要分割的分隔符作為參數傳遞。
- str1="This is a book"
- str2="test/ str 2"
- print(str1.split()) # ['This', 'is', 'a', 'book']
- print(str2.split('/')) # ['test', ' str 2']
8 將字符串列表組合成單個字符串
join()將作為參數傳遞的字符串列表組合為單個字符串。這種情況下,我們使用逗號分隔符將它們分開。
- list_str=['This','is','a','book']
- print(','.join(list_str))
- # This,is,a,book
9 檢查回文字符串
我們已經討論過如何反轉字符串,因此回文字符串在 Python 中判斷起來非常簡單。
- str1="qqaabb"
- if str1==str1[::-1]:
- print("回文")
- else:
- print("不是")
- # 不是
10 列表中的元素統計
使用 Python Counter 類。Python 計數器跟蹤容器中每個元素的頻數, Counter()返回一個字典,元素作為鍵,頻數作為值。
另外使用 most_common()函數來獲取列表中的 出現次數最多的元素。
- from collections import Counter
- list1=['a','b','a','c','c','c']
- count=Counter(list1)
- print(count)
- print(count['b'])
- print(count.most_common(1))
11 判斷兩個字符串是否為異序詞
異序詞是通過重新排列不同單詞或短語的字母而形成的單詞或短語。如果兩個字符串的 Counter 對象相等,那么它們就是相同字母異序詞對。
- s1,s2,s3="acbde","abced","abcda"
- c1,c2,c3=Counter(s1),Counter(s2),Counter(s3)
- if c1==c2:
- print('1和2是異序詞')
- if c1==c3:
- print('1和3是異序詞')
12 使用 try-except-else 塊
try / except 是 Python 中的異常處理模塊,添加 else 語句,會在 try 塊中沒有引發異常的情況下運行。
- a,b=1,0
- try:
- print(a/b)
- # b為0的時候觸發異常
- except ZeroDivisionError:
- print("除數為0")
- else:
- print("不存在異常")
- finally:
- print("此段總是會執行")
13 通過枚舉獲取索引 / 值對
可以使用下面的腳本,遍歷列表中的值及其索引。
- list1=['a','b','c','d','e']
- for idx,val in enumerate(list1):
- print('{0}:{1}'.format(idx,val))
- # 0:a
- # 1:b
- # 2:c
- # 3:d
- # 4:e
14 獲取對象的內存使用信息
下面腳本可用于檢查對象的內存使用信息。
- import sys
- num=21
- print(sys.getsizeof(num))
15 合并兩個字典
在 Python 2 中,使用 update()合并兩個字典,Python 3 變得更加簡單。
下面腳本中,兩個字典被合并。在相交的情況下,使用第二個字典中的值。
- dic1={'app':9,'banana':6}
- dic2={'banana':4,'orange':8}
- com_dict={**dic1,**dic2}
- # {'apple':9,'banana':4,'orange':8}
16 計算代碼執行所需的時間
下面代碼使用庫函數來計算執行代碼所需的時間消耗多少毫秒。
- import time
- s_time=time.time()
- a,b=1,2
- c=a+b
- e_time=time.time()
- time_taken_in_micro=(e_time-stime)*(10**6)
- print("程序運行的毫秒:{0} ms".format(time_taken_in_micro))
17 展開列表清單
有時不知道列表的嵌套深度,并且只想把所有元素放在一個普通列表中。可以通下面的方法得到數據:
- from iteration_utilities import deepflatten
- # 如果嵌套列表的深度只有1層
- def flatten(l):
- return [item for sublist in l for item in sublist]
- l=[[1,2,3],[3]]
- print(flatten(l))
- # [1,2,3,3]
- # 如果不知道列表嵌套深度
- l=[[1,2,3],[4,[5],[6,7]],[8,[9,[10]]]]
- print(list(deepflatten(l,depth=3)))
- # [1,2,3,4,5,6,7,8,9,10]
18 從列表中隨機取樣
下面代碼從給定列表中生成了 n 個隨機樣本。
- import random
- list1=['a','b','c','d','e']
- ns=2
- samples=random.sample(list1,ns)
- print(samples)
- # ['a','c']
或者使用secrets庫生成隨機樣本進行, 下面代碼僅適用于 Python 3.x。
- import secrets
- s_rand=secrets.SystemRanom()
- list1=['a','b','c','d','e']
- ns=2
- samples=s_rand.sample(list1,ns)
- print(samples)
- # ['c','d']
19 數字列表化
下面代碼將整數轉換為數字列表。
- nums=123456
- # 使用map
- digit_list=list(map(int,str(nums)))
- print(digit_list)
- # [1,2,3,4,5,6]
- # 使用列表表達式
- digit_list=[int(x) for x in str(nums)]
- print(digit_list)
- # [1,2,3,4,5,6]
20 唯一性檢查
下面的函數檢查列表中的元素是否唯一。
- def unique(l):
- if len(l)==len(set(l)):
- print("所有元素是唯一的")
- else:
- print("存在重復")
- unique([1,2,3,4])
- # 所有元素是唯一的
- unique([1,1,3,4])
- # 存在重復