驚了! MySQL 熱冷數(shù)據(jù)分離設(shè)計還能這樣!
數(shù)據(jù)庫發(fā)展簡介
數(shù)據(jù)量的增長其實一直是隨著互聯(lián)網(wǎng)的發(fā)展呈現(xiàn)爆發(fā)式增長的,因為各種各樣的數(shù)據(jù)都在不斷的被原樣或者是經(jīng)過少量的更改和增補后拷貝到互聯(lián)網(wǎng)的各個角落。為了適應(yīng)互聯(lián)網(wǎng)數(shù)據(jù)的海量增長,在后端和架構(gòu)意義上而言,數(shù)據(jù)庫的發(fā)展也大致經(jīng)歷了「單庫單表 -> 主從讀寫分離 -> 分表分庫 -> NoSQL -> NewSQL」這樣的過程。
一開始,我們把數(shù)據(jù)都堆在一個數(shù)據(jù)表里;后來為了提高性能、增加數(shù)據(jù)擴(kuò)展的能力,采用了「主從讀寫分離」和「分表分庫」的方式,前者只需要在主從實例之間做數(shù)據(jù)同步而不會對既有業(yè)務(wù)有較大的影響,后者則需要用一套切合業(yè)務(wù)邏輯的方式合理的制定分表分庫的策略;再后來出現(xiàn)的 NoSQL,打破了傳統(tǒng)關(guān)系型數(shù)據(jù)庫固有的一些限制,它們有不同的類型,有的是為了解決高性能讀寫的需求,有的則是為了解決海量數(shù)據(jù)存儲的需求,還有的需要數(shù)據(jù)結(jié)構(gòu)本身具備可擴(kuò)展性;
NoSQL 的不同類型在不同的側(cè)重點解決了不同的問題,而如今出現(xiàn)的 NewSQL 則傾向于把數(shù)據(jù)庫看作是一個黑匣子服務(wù),你還是可以遵照傳統(tǒng)的數(shù)據(jù)庫協(xié)議的使用方式(比如傳統(tǒng) MySQL 的使用方式)來使用它,但數(shù)據(jù)存儲服務(wù)本身既可以同時具備較高的讀寫性能又可以輕易的實現(xiàn)橫向擴(kuò)展。NewSQL 并不是一個全新的東西,我們可以把它看作是之前積累的數(shù)據(jù)庫技術(shù)結(jié)合分布式技術(shù)的集大成解決方案,它使得使用數(shù)據(jù)服務(wù)的人幾乎不需要再考慮性能和擴(kuò)展問題,而盡量在數(shù)據(jù)服務(wù)內(nèi)部實現(xiàn)高可用、高性能、可擴(kuò)展。
「熱數(shù)據(jù)」和「冷數(shù)據(jù)」
在簡單了解了數(shù)據(jù)庫發(fā)展歷程之后,再介紹一下我們目前在數(shù)據(jù)存儲上遇到的問題和一些業(yè)務(wù)背景。
作為氣象大數(shù)據(jù)服務(wù)商,隨著我們積累的數(shù)據(jù)量和數(shù)據(jù)種類越來越多,我們發(fā)現(xiàn)我們已經(jīng)迫切需要一個在全局層面統(tǒng)一的數(shù)據(jù)路徑規(guī)劃和規(guī)范。很多時候,我們從數(shù)據(jù)源獲取到的數(shù)據(jù),既需要馬上分發(fā)給線上用戶,也需要被內(nèi)部項目使用,如果只是簡單的按需實現(xiàn),那數(shù)據(jù)流轉(zhuǎn)會非常混亂。基于這種考慮,我們引入了「熱數(shù)據(jù)」(「在線數(shù)據(jù)」)和「冷數(shù)據(jù)」(「離線數(shù)據(jù)」)的概念:
「熱數(shù)據(jù)」指的是需要即時對用戶進(jìn)行分發(fā)的數(shù)據(jù),即從數(shù)據(jù)源抓取之后經(jīng)過數(shù)據(jù)清洗,需要即時存儲到可以快速分發(fā)的存儲介質(zhì)(如 Redis)供 API 或直接面向用戶的系統(tǒng)使用。「熱數(shù)據(jù)」線需要重點保障服務(wù)質(zhì)量和穩(wěn)定性,為了保證數(shù)據(jù)的時效性,在數(shù)據(jù)處理上也是優(yōu)先級高的數(shù)據(jù)。「熱數(shù)據(jù)」可能是臨時或短期存儲的,后來的數(shù)據(jù)可能會覆蓋已有的數(shù)據(jù)。
「冷數(shù)據(jù)」指的是不需要即時分發(fā)給用戶的數(shù)據(jù),這些數(shù)據(jù)甚至可能永遠(yuǎn)都不會原樣分發(fā)給用戶的,但它們需要經(jīng)過長期的積累,使我們可以從中得出基于此的更高 level 的分析。「冷數(shù)據(jù)」典型的使用場景是供內(nèi)部數(shù)據(jù)評估系統(tǒng)做數(shù)據(jù)準(zhǔn)確度的評估分析,同時也可以給算法團(tuán)隊建模使用。設(shè)立這個數(shù)據(jù)線的原則是不影響「熱數(shù)據(jù)」的服務(wù)質(zhì)量,尤其是時效性和穩(wěn)定性,同時也滿足一些非線上項目的數(shù)據(jù)使用需求。
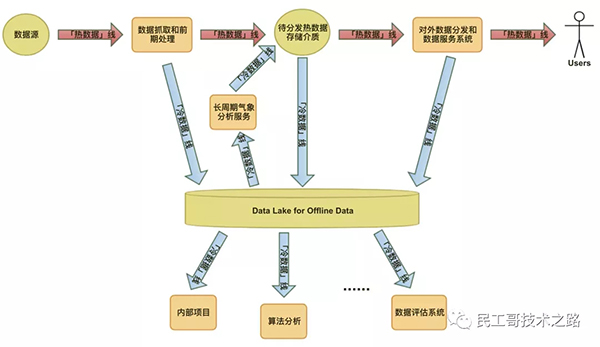
這其實也不是什么新鮮的概念,很多做數(shù)據(jù)服務(wù)的公司都有類似的設(shè)計,我們只是根據(jù)我們的業(yè)務(wù)特點借用了這樣的概念,不過它們的含義可能與你在其他地方看到的類似概念的含義有所不同。
結(jié)合我們具體的業(yè)務(wù)場景來說,「熱數(shù)據(jù)」線其實已經(jīng)一直在有效運轉(zhuǎn)了,即我們從數(shù)據(jù)源獲取到數(shù)據(jù)然后盡快存儲到高性能存儲介質(zhì)中,再通過HTTP協(xié)議分發(fā)出去,這些數(shù)據(jù)都是即時更新的最新的數(shù)據(jù)。而其中有一些類型的數(shù)據(jù),我們還需要在可視化項目中查看歷史變化情況,并能進(jìn)行簡單的聚合和計算,這意味著數(shù)據(jù)需要積累一段時間,那我們也需要一些可以持久化存儲的介質(zhì)。
拿天氣實況來舉例,我們在采集完數(shù)據(jù)之后,隨即就存儲最新的一份數(shù)據(jù)到Redis,而出于數(shù)據(jù)積累的角度考慮,我們同時也把新數(shù)據(jù)寫入MySQL。這是之前我們的做法,然而隨著數(shù)據(jù)量的極速擴(kuò)大,問題很快就會出在MySQL上。對于「億」級別行數(shù)往上的MySQL單表,操作會變得越來越困難,而大范圍的抽數(shù)或者插入數(shù)據(jù)的操作都可能使得整個MySQL無法提供服務(wù),這對于線上業(yè)務(wù)而言是不可接受的。
離線數(shù)據(jù)中心的實現(xiàn)
在提出了「冷數(shù)據(jù)」的概念之后,我們意識到那些久遠(yuǎn)的歷史數(shù)據(jù)其實需要存放到「冷數(shù)據(jù)」的數(shù)據(jù)中心池子里,而線上MySQL只需要保留最近一段時間的數(shù)據(jù)即可。另外,為了不改變現(xiàn)有項目使用數(shù)據(jù)的方式,降低數(shù)據(jù)庫使用者的門檻,不管是對于線上數(shù)據(jù)庫還是「離線數(shù)據(jù)」的數(shù)據(jù)中心,我們都需要兼容MySQL單表的使用協(xié)議。
很快我們就開始考慮NewSQL的方案,TiDB很自然地進(jìn)入了我們的視野,這是一個既可以兼容現(xiàn)有數(shù)據(jù)使用方式,又可以實現(xiàn)數(shù)據(jù)橫向擴(kuò)展的完美方案,但無奈搭建一個最小版本的TiDB 數(shù)據(jù)集群的成本,相比于目前我們把它作為一個「離線數(shù)據(jù)」存儲中心的角色而言,還是有一些偏高,而我們的存量服務(wù)也基本都是基于阿里云的,所以最終我們選擇了阿里云推出不久的云數(shù)據(jù)庫PolarDB。其間我們還研究了很多其他數(shù)據(jù)庫方案,比如DRDS、OceanBase、Google Cloud Spanner、Amazon Aurora等。
數(shù)據(jù)同步和數(shù)據(jù)過期
有了離線數(shù)據(jù)存儲中心之后,我們開始考慮如何把「熱數(shù)據(jù)」轉(zhuǎn)化為「冷數(shù)據(jù)」,同時也使得線上數(shù)據(jù)庫可以自動過期超出時間窗口的歷史數(shù)據(jù)。另外,由于內(nèi)部可視化項目也希望看到實時的實況數(shù)據(jù),所以離線數(shù)據(jù)最好也能很快獲得最新的實況數(shù)據(jù)。
既然是兩個 MySQL(集群)之間的實時數(shù)據(jù)轉(zhuǎn)移,很自然的就想到了我們可以做類似主從節(jié)點之間通過 binlog 的數(shù)據(jù)同步機(jī)制,這個同步可以做到秒級延遲,在實時性上是完全可以接受的。不過這不能是簡單的數(shù)據(jù)同步,因為離線數(shù)據(jù)是不能同步線上數(shù)據(jù)的過期操作的。更具體的,我們可以概括成:MySQL 從節(jié)點同步主節(jié)點所有數(shù)據(jù)增添和數(shù)據(jù)修改的操作,而對于數(shù)據(jù)的刪除操作不做同步。
在調(diào)研之后,我們發(fā)現(xiàn)TiDB提供的同步工具Syncer可以實現(xiàn)這一點,我們只需要在配置注明過濾掉DELETE的DML語句即可,示例如下:
- [[skip-dmls]]
- db-name = "weather_data"
- tbl-name = "weather_now_history"
- type = "delete"
而數(shù)據(jù)過期方案則可以直接借助MySQL本身的EVENT和PROCEDURE機(jī)制完成。首先我們可以創(chuàng)建一個刪除數(shù)據(jù)的PROCEDURE:
- CREATE DEFINER=`weather`@`%` PROCEDURE `weather_data`.`del_old_data`(IN `date_inter` int)
- BEGIN
- delete from weather_data.weather_now_history where datetime < date_sub(curdate(), interval date_inter day);
- END
這個PROCEDURE功能是刪除weather_now_history表中date_inter天之前的數(shù)據(jù)。然后我們再創(chuàng)建一個EVENT:
- CREATE EVENT del_old_data
- ON SCHEDULE EVERY 1 DAY
- STARTS '2018-12-25 10:08:35.000'
- ON COMPLETION PRESERVE
- ENABLE
- DO call del_old_data(30)
這個EVENT則會每天調(diào)用一次名為del_old_data的PROCEDURE,并同時把date_inter 賦值為30。這意味數(shù)據(jù)庫每天會刪一次數(shù)據(jù),使得線上數(shù)據(jù)庫一直只保留最近30天的數(shù)據(jù),而全量的數(shù)據(jù)是在數(shù)據(jù)寫入時就實時同步到了離線數(shù)據(jù)中心,可謂完美。
持續(xù)改進(jìn)
上述的具體業(yè)務(wù)場景更多的還是case by case的解決了「熱數(shù)據(jù)」和「冷數(shù)據(jù)」的分離和轉(zhuǎn)化問題,這意味著方案并不具有普適性,以后我們遇到其他的數(shù)據(jù)庫或者不同的數(shù)據(jù)使用場景可能就不再適用。
另外,很多時候,「熱數(shù)據(jù)」和「冷數(shù)據(jù)」的劃分并不是那么明晰的,對于「冷數(shù)據(jù)」的需求有可能轉(zhuǎn)變?yōu)椤笩釘?shù)據(jù)」需求,我們需要可以靈活切換的機(jī)制,做到數(shù)據(jù)源只抓取一次(「熱數(shù)據(jù)」和「冷數(shù)據(jù)」不要分別抓取),而抓取到的數(shù)據(jù)可以任意自由的流淌到「熱數(shù)據(jù)」或「冷數(shù)據(jù)」線使用,這意味著我們在數(shù)據(jù)抓取和數(shù)據(jù)存儲之間應(yīng)該再做一層隔離。
要實現(xiàn)數(shù)據(jù)抓取和數(shù)據(jù)存儲之間的隔離,我們可以采用「發(fā)布 / 訂閱模式」:簡單說,數(shù)據(jù)抓取服務(wù)在獲取數(shù)據(jù)之后將數(shù)據(jù)發(fā)布到消息隊列,后面的存儲服務(wù)任意訂閱這個消息隊列再做存儲,這樣數(shù)據(jù)源只需要抓取一次,我們可以把它作為熱數(shù)據(jù)使用,也可以作為冷數(shù)據(jù)使用,甚至可以即作為熱數(shù)據(jù)又作為冷數(shù)據(jù)使用,切換起來也十分簡單。這是后續(xù)系統(tǒng)架構(gòu)可以改進(jìn)的一個地方。
另外,離線數(shù)據(jù)中心僅僅使用 PolarDB 對于我們可能產(chǎn)生的數(shù)據(jù)量級而言也是遠(yuǎn)遠(yuǎn)不夠的,我們還需要更低成本的數(shù)據(jù)存儲方案來存儲時間更久遠(yuǎn)、平時幾乎不大會訪問的一些需要被「歸檔」的數(shù)據(jù),這個時候,一些基于列存儲的 NoSQL 數(shù)據(jù)庫可能可以派上用場。
數(shù)據(jù)治理需要一個長期持續(xù)的過程,我們還在結(jié)合自身的業(yè)務(wù)場景不斷的摸索當(dāng)中。