基于Kafka+Flink平臺化設計,實時數倉還能這樣建
本文由網易云音樂實時計算平臺研發工程師岳猛分享,主要從以下四個部分將為大家介紹 Flink + Kafka 在網易云音樂的應用實戰:
背景
- Flink + Kafka 平臺化設計
- Kafka 在實時數倉中的應用
- 問題 & 改進
一、背景介紹
1、流平臺通用框架
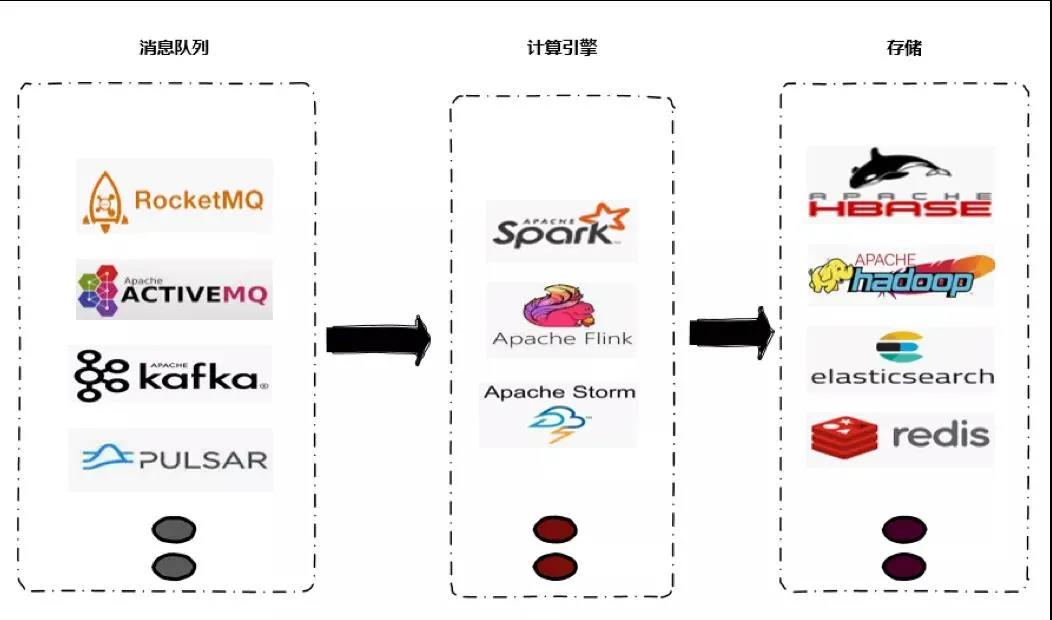
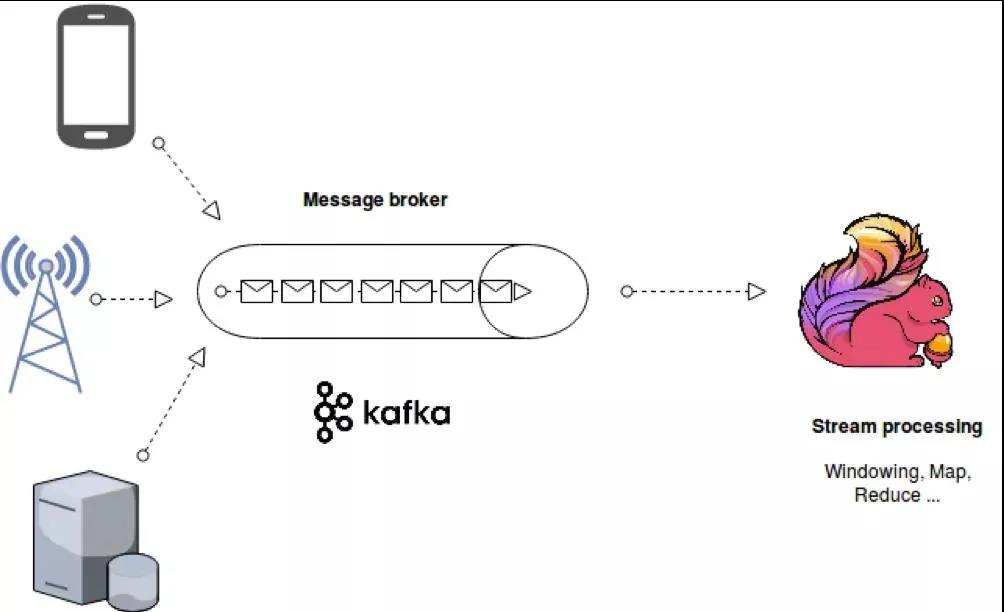
目前流平臺通用的架構一般來說包括消息隊列、計算引擎和存儲三部分,通用架構如下圖所示。客戶端或者 web 的 log 日志會被采集到消息隊列;計算引擎實時計算消息隊列的數據;實時計算結果以 Append 或者 Update 的形式存放到實時存儲系統中去。
目前,我們常用的消息隊列是 Kafka,計算引擎一開始我們采用的是 Spark Streaming,隨著 Flink 在流計算引擎的優勢越來越明顯,我們最終確定了 Flink 作為我們統一的實時計算引擎。
2、為什么選 Kafka?
Kafka 是一個比較早的消息隊列,但是它是一個非常穩定的消息隊列,有著眾多的用戶群體,網易也是其中之一。我們考慮 Kafka 作為我們消息中間件的主要原因如下:
- 高吞吐,低延遲:每秒幾十萬 QPS 且毫秒級延遲;
- 高并發:支持數千客戶端同時讀寫;
- 容錯性,可高性:支持數據備份,允許節點丟失;
- 可擴展性:支持熱擴展,不會影響當前線上業務。
3、為什么選擇 Flink?
Apache Flink 是近年來越來越流行的一款開源大數據流式計算引擎,它同時支持了批處理和流處理,考慮 Flink 作為我們流式計算引擎的主要因素是:
- 高吞吐,低延遲,高性能;
- 高度靈活的流式窗口;
- 狀態計算的 Exactly-once 語義;
- 輕量級的容錯機制;
- 支持 EventTime 及亂序事件;
- 流批統一引擎。
4、Kafka + Flink 流計算體系
基于 Kafka 和 Flink 的在消息中間件以及流式計算方面的耀眼表現,于是產生了圍繞 Kafka 及 Flink 為基礎的流計算平臺體系,如下圖所示:基于 APP、web 等方式將實時產生的日志采集到 Kafka,然后交由 Flink 來進行常見的 ETL,全局聚合以及Window 聚合等實時計算。
5、網易云音樂使用 Kafka 的現狀
目前我們有 10+個 Kafka 集群,各個集群的主要任務不同,有些作為業務集群,有些作為鏡像集群,有些作為計算集群等。當前 Kafka 集群的總節點數達到 200+,單 Kafka 峰值 QPS 400W+。目前,網易云音樂基于 Kafka+Flink 的實時任務達到了 500+。
二、Flink+Kafka 平臺化設計
基于以上情況,我們想要對 Kafka+Flink 做一個平臺化的開發,減少用戶的開發成本和運維成本。實際上在 2018 年的時候我們就開始基于 Flink 做一個實時計算平臺,Kafka 在其中發揮著重要作用,今年,為了讓用戶更加方便、更加容易的去使用 Flink 和 Kafka,我們進行了重構。
基于 Flink 1.0 版本我們做了一個 Magina 版本的重構,在 API 層次我們提供了 Magina SQL 和 Magina SDK 貫穿 DataStream 和 SQL 操作;然后通過自定義 Magina SQL Parser 會把這些 SQL 轉換成 Logical Plan,在將 LogicalPlan 轉化為物理執行代碼,在這過程中會去通過 catalog 連接元數據管理中心去獲取一些元數據的信息。我們在 Kafka 的使用過程中,會將 Kafka 元數據信息登記到元數據中心,對實時數據的訪問都是以流表的形式。在 Magina 中我們對 Kafka 的使用主要做了三部分的工作:
- 集群 catalog 化;
- Topic 流表化;
- Message Schema 化。
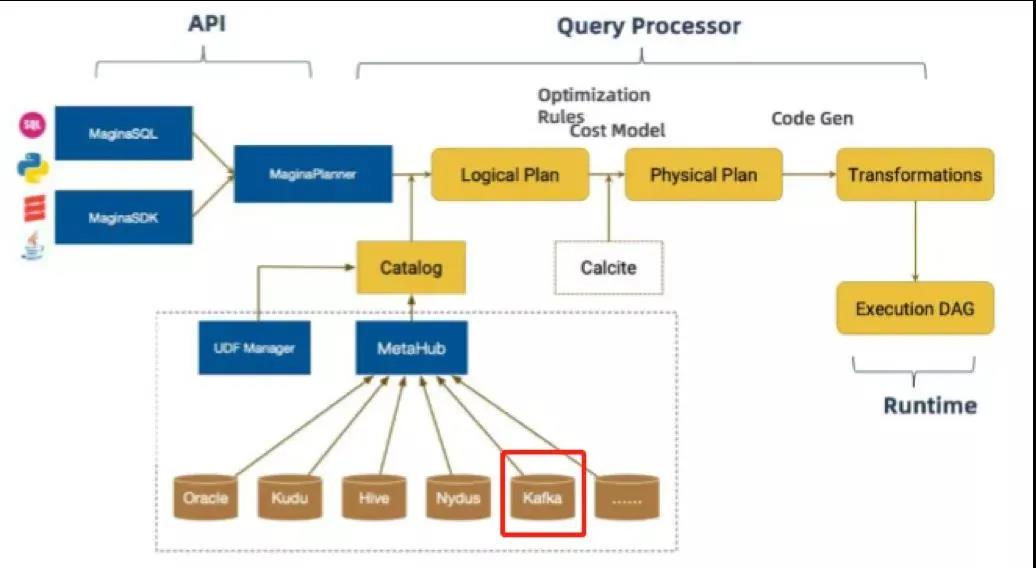
用戶可以在元數據管理中心登記不同的表信息或者 catalog 信息等,也可以在 DB 中創建和維護 Kafka 的表,用戶在使用的過程只需要根據個人需求使用相應的表即可。下圖是對 Kafka 流表的主要引用邏輯。
三、Kafka 在實時數倉中的應用
1、在解決問題中發展
Kafka 在實時數倉使用的過程中,我們遇到了不同的問題,中間也嘗試了不同的解決辦法。
在平臺初期, 最開始用于實時計算的只有兩個集群,且有一個采集集群,單 Topic 數據量非常大;不同的實時任務都會消費同一個大數據量的 Topic,Kafka 集群 IO 壓力異常大;
因此,在使用的過程發現 Kafka 的壓力異常大,經常出現延遲、I/O 飆升。
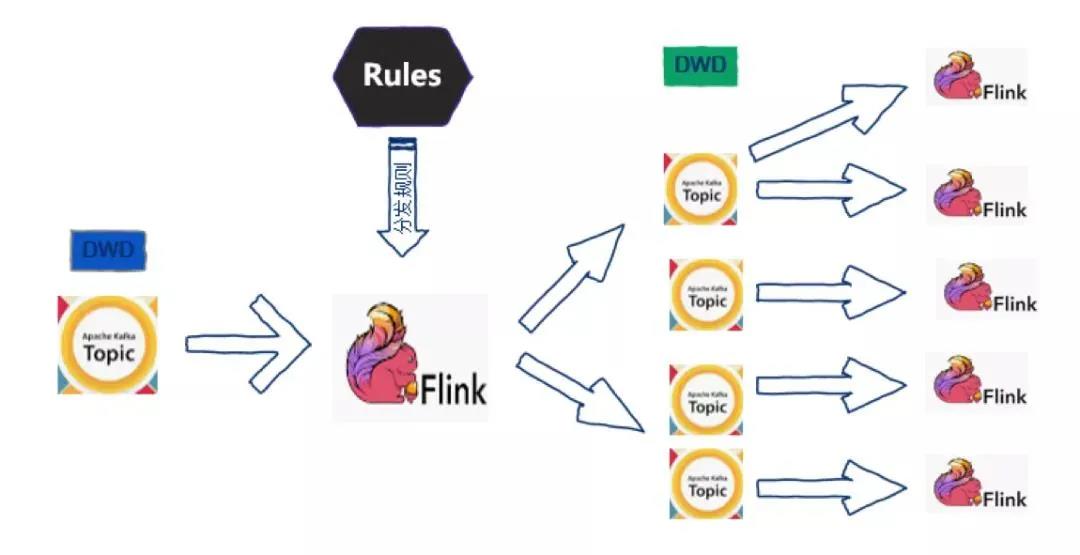
我們想到把大的 Topic 進行實時分發來解決上面的問題,基于 Flink 1.5 設計了如下圖所示的數據分發的程序,也就是實時數倉的雛形。基于這種將大的 Topic 分發成小的 Topic 的方法,大大減輕了集群的壓力,提升了性能,另外,最初使用的是靜態的分發規則,后期需要添加規則的時候要進行任務的重啟,對業務影響比較大,之后我們考慮了使用動態規則來完成數據分發的任務。
解決了平臺初期遇到的問題之后,在平臺進階過程中 Kafka 又面臨新的問題:
- 雖然進行了集群的擴展,但是任務量也在增加,Kafka 集群壓力仍然不斷上升;
- 集群壓力上升有時候出現 I/O 相關問題,消費任務之間容易相互影響;
- 用戶消費不同的 Topic 過程沒有中間數據的落地,容易造成重復消費;
- 任務遷移 Kafka 困難。
針對以上問題,我們進行了如下圖所示的 Kafka 集群隔離和數據分層處理。其過程簡單來說,將集群分成 DS 集群、日志采集集群、分發集群,數據通過分發服務分發到 Flink 進行處理,然后通過數據清洗進入到 DW 集群,同時在 DW 寫的過程中會同步到鏡像集群,在這個過程中也會利用 Flink 進行實時計算的統計和拼接,并將生成的 ADS 數據寫入在線 ADS 集群和統計 ADS 集群。通過上面的過程,確保了對實時計算要求比較高的任務不會受到統計報表的影響。
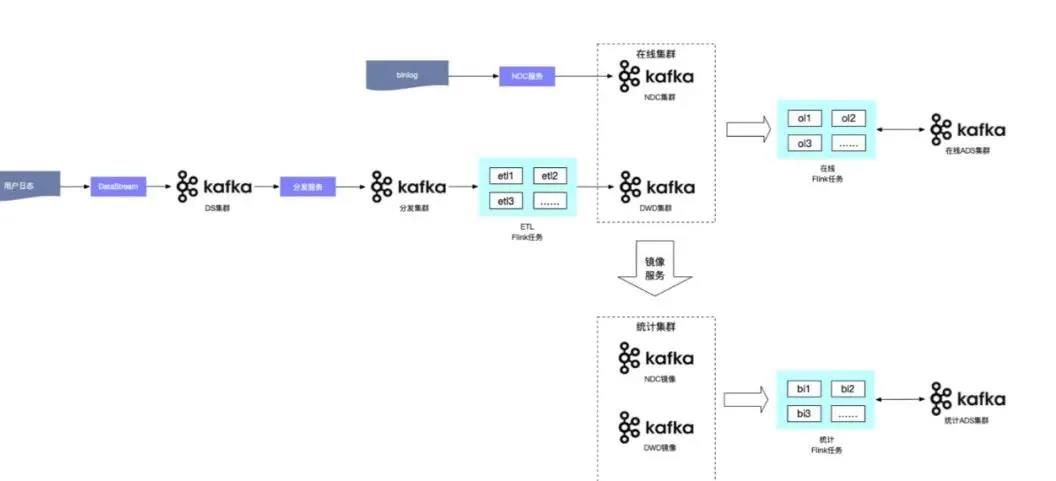
通過上面的過程,確保了對實時計算要求比較高的任務不會受到統計報表的影響。但是我們分發了不同的集群以后就不可避免的面臨新的問題:
- 如何感知 Kafka 集群狀態?
- 如何快速分析 Job 消費異常?
針對上面兩個問題,我們做了一個 Kafka 監控系統,其監控分為如下兩個維度,這樣在出現異常的時候就可以進行具體判斷出現問題的詳細情況:
- 集群概況的監控:可以看到不同集群對應的 Topic 數量以及運行任務數量,以及每個 Topic 消費任務數據量、數據流入量、流入總量和平均每條數據大小;
- 指標監控:可以看到 Flink 任務以及對應的 Topic、GroupID、所屬集群、啟動時間、輸入帶寬、InTPS、OutTPS、消費延遲以及 Lag 情況。
2、Flink + Kafka 在 Lambda 架構下的運用
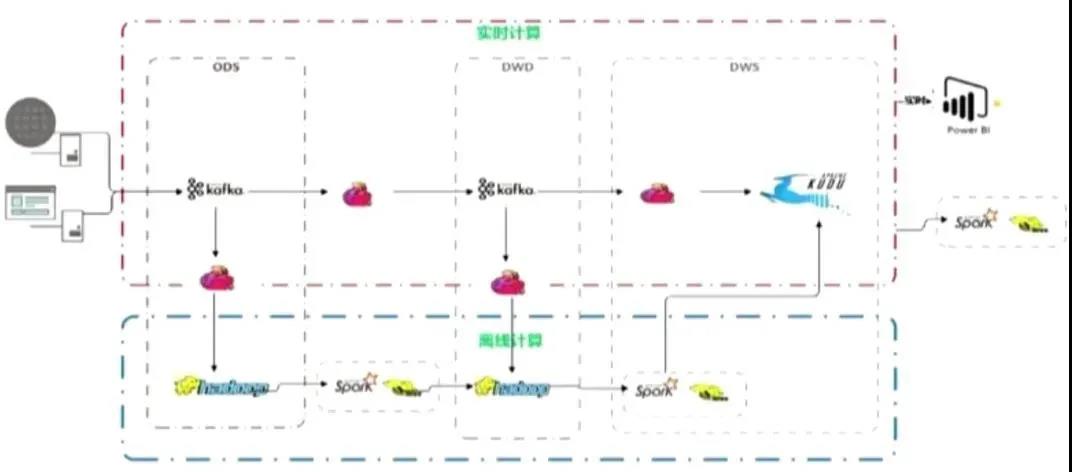
流批統一是目前非常火的概念,很多公司也在考慮這方面的應用,目前常用的架構要么是 Lambda 架構,要么是 Kappa 架構。對于流批統一來講需要考慮的包括存儲統一和計算引擎統一,由于我們當前基建沒有統一的存儲,那么我們只能選擇了 Lamda 架構。
下圖是基于 Flink 和 Kafka 的 Lambda 架構在云音樂的具體實踐,上層是實時計算,下層是離線計算,橫向是按計算引擎來分,縱向是按實時數倉來區分。
四、問題&改進
在具體的應用過程中,我們也遇到了很多問題,最主要的兩個問題是:
- 多 Sink 下 Kafka Source 重復消費問題;
- 同交換機流量激增消費計算延遲問題。
1、多 Sink 下 Kafka Source 重復消費問題
Magina 平臺上支持多 Sink,也就是說在操作的過程中可以將中間的任意結果插入到不同的存儲中。這個過程中就會出現一個問題,比如同一個中間結果,我們把不同的部分插入到不同的存儲中,那么就會有多條 DAG,雖然都是臨時結果,但是也會造成 Kafka Source 的重復消費,對性能和資源造成極大的浪費。
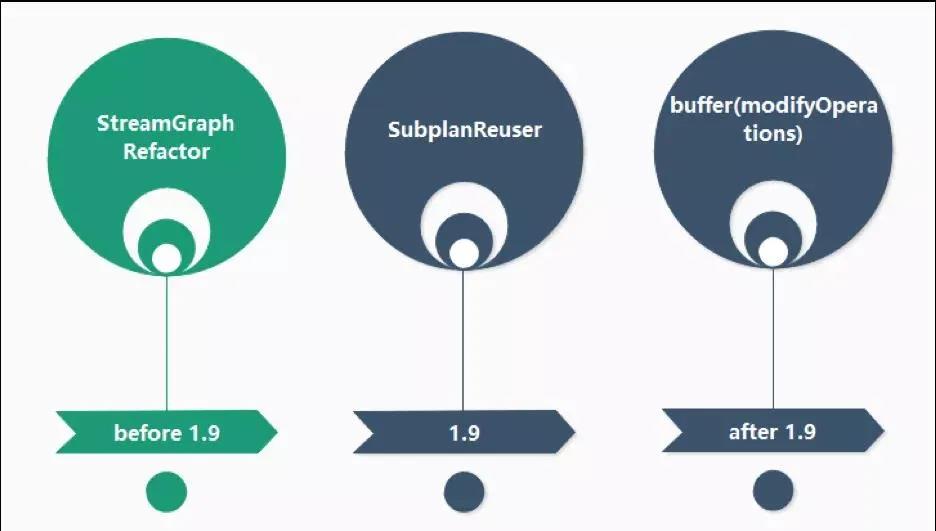
于是我們想,是否可以避免臨時中間結果的多次消費。在 1.9 版本之前,我們進行了 StreamGraph 的重建,將三個 DataSource 的 DAG 進行了合并;在 1.9 版本,Magina 自己也提供了一個查詢和 Source 合并的優化;但是我們發現如果是在同一個 data update 中有對同一個表的多個 Source 的引用,它自己會合并,但是如果不是在同一個 data update 中,是不會立即合并的,于是在 1.9 版本之后中我們對 modifyOperations 做了一個 buffer 來解決這個問題。
2、同交換機流量激增消費計算延遲問題
這個問題是最近才出現的問題,也可能不僅僅是同交換機,同機房的情況也可能。在同一個交換機下我們部署了很多機器,一部分機器部署了 Kafka 集群,還有一部分部署了 Hadoop 集群。在 Hadoop 上面我們可能會進行 Spark、Hive 的離線計算以及 Flink 的實時計算,Flink 也會消費 Kafka 進行實時計算。在運行的過程中我們發現某一個任務會出現整體延遲的情況,排查過后沒有發現其他的異常,除了交換機在某一個時間點的瀏覽激增,進一步排查發現是離線計算的瀏覽激增,又因為同一個交換機的帶寬限制,影響到了 Flink 的實時計算。

為解決這個問題,我們就考慮要避免離線集群和實時集群的相互影響,去做交換機部署或者機器部署的優化,比如離線集群單獨使用一個交換機,Kafka 和 Flink 集群也單獨使用一個交換機,從硬件層面保證兩者之間不會相互影響。
Q&A
Q1:Kafka 在實時數倉中的數據可靠嗎?
A1:這個問題的答案更多取決于對數據準確性的定義,不同的標準可能得到不同的答案。自己首先要定義好數據在什么情況下是可靠的,另外要在處理過程中有一個很好的容錯機制。
Q2:我們在學習的時候如何去學習這些企業中遇到的問題?如何去積累這些問題?
A2:個人認為學習的過程是問題推動,遇到了問題去思考解決它,在解決的過程中去積累經驗和自己的不足之處。
Q3:你們在處理 Kafka 的過程中,異常的數據怎么處理,有檢測機制嗎?
A3:在運行的過程中我們有一個分發的服務,在分發的過程中我們會根據一定的規則來檢測哪些數據是異常的,哪些是正常的,然后將異常的數據單獨分發到一個異常的 Topic 中去做查詢等,后期用戶在使用的過程中可以根據相關指標和關鍵詞到異常的 Topic 中去查看這些數據。