













李飛飛領銜!16位跨學科大牛談AI的下個十年干貨
紐約大學心理學和神經科學教授Gary Marcus和深度學習先驅和2018年圖靈獎得主Yoshua Bengio在線上進行了一場“神仙打架”,邀請了包括李飛飛在內16位全球知名的AI學者、生物科學家和法律界專家,討論近一年內AI各領域的進展突破,以及下一個十年如何將人工智能提升到下一個階段。
此次圓桌論壇圍繞著“如何用跨學科方法推動AI前進(Moving AI Forward: An Interdisciplinary Approach)”的主題,下分三個模塊:架構與挑戰(Architecture and Challenges)、神經科學與心理學帶來的洞見(Insights from Neuroscience and psychology)、構建可信任的AI(Towards AI we can trust),共持續了三個多小時。
演講主題匯總:https://montrealartificialintelligence.com/aidebate2/readings.pdf
辯論視頻:https://montrealartificialintelligence.com/aidebate2/
一、李飛飛:與環境交互是下一顆AI“北極星”
作為首位發言嘉賓,斯坦福大學教授李飛飛提到了AI領域的“北極星”,即未來學科的發展方向。在過去五十年中,AI領域有一顆很重要的“北極星”就是物體識別,這也是人類認知能力中很重要的部分。物體識別的進步也帶來了如ImageNet等AI基準測試水平的巨大突破。
李飛飛援引了1963年一項基于動物的“與環境交互產生行為刺激”的研究,提出培養下一代AI與環境交互是未來很重要的研究方向。
她也提到互動是智力很重要的組成部分,就像嬰兒通過與外界的互動認識世界一樣,下一代AI也應該具備通過與外界交互發展自身智能的能力,而這一代AI的實體也不僅限于物理機器人,智能體(Agent,可以自主活動的軟件或者小型硬件)也可以。

二、Luís Lamb:架起符號AI和神經網絡的“橋梁”
巴西南里約熱內盧聯邦大學計算機科學教授Luís Lamb延續他上周在NeurIPS AI會議上的話題,談到了“神經符號AI(neurosymbolic AI)”。
神經符號AI即將上世紀70年代AI學界流行的符號主義與目前主流的神經網絡算法融合。
簡單言之,符號AI可以對物體進行分類及定義,存在自己的知識庫中,但如果需要回答更復雜的問題則需要構建足夠龐大的知識庫,因為符號AI只能回答知識庫中已有的分類。
神經符號AI具體的實現辦法,是利用深度神經網絡構建符號AI所需要的知識庫,然后使用符號AI對任務進行推理。
Lamb提到連接符號AI和神經網絡的通用方法是未來很重要的研究方向,Marcus在《代數思維(The Algebraic Mind)》提到的在神經網絡中控制符號AI的方法也非常有借鑒意義。

三、Rich Sutton:強化學習或是AI的第一個計算理論
DeepMind科學家Rich Sutton認為AI需要一種公認的智能計算理論。
他引用了神經科學家David Marr三個處理級別的概念:計算理論、表征和算法以及硬件設備,提出當前AI屆中并沒有計算理論,梯度下降等可以被稱為AI的方法,但遠稱不上理論。
在發言的最后,Sutton總結道,強化學習或許會是智能的第一個計算理論,預測編碼和貝葉斯推斷也可能可以被稱為AI的計算理論。

四、Judea Pearl:模型要“明白”因果關系
圖靈獎獲得者、貝葉斯網絡之父、暢銷書《為什么(Why)》的作者Judea Pearl探討了如何讓模型理解因果關系。
Pearl認為如果我們想讓模型知道“目前是什么情況”、“如果發生了這個情況要怎么辦”以及“只有這一種情況嗎”,那么深度理解是最好的辦法。
模型的深度理解是建立在深度學習基礎上的,Pearl說,自己新開發的、可以表征模型“心理狀態”的計算模型就是基于對模型因果關系的深度學習。
五、Robert Ness:概率編程輔助因果推理
機器學習專家Robert Ness演講的主題是“因果推理與(深度)概率規劃(causal reasoning with (deep) probabilistic programming)”。
Ness說,概率編程能夠幫助我們在面對不確定性時做出決策,這很大程度地規避了因果推理中過于依賴先驗事實的缺點,也可以解決一部分Pearl所提到的“只有這一種情況嗎”的問題。
Ness以新冠病毒傳播模型為例,概率編程可以利用自身“不確定性”,基于先前的傳染病數據進行流行病學建模,為“抗疫”貢獻自己的力量。

六、Ken Stanley:計算機的進化之路
中佛羅里達大學(the University of Central Florida)計算機科學教授Ken Stanley探討了進化與創造性,計算機能解決很多問題,但人類也能做到很多計算機做不到的事情,那就是開放性的創新。
“在過去數千年,從鉆木取火到太空空間站,我們懷抱著一個開放的心態,在舊事物上發展出新事物。”Stanley認為,但計算機的進化路徑卻是“現象型(phenomenal)”的,不同的階段會出現不同的應用需求和新方法,我們需要去理解這些現象,才能持續計算機的“進化之路”。
Stanley也承認目前看來,計算機或者說AI的“進化”并不那么完美,像AI仿制一些藝術畫作,或許看起來像模像樣,但其實不算真正的藝術,還會對那些藝術初學者造成打擊。
Stanley認為,這時候就需要我們去正確看待AI,它是幫助我們的工具,真正的目的是幫助人類進步,它的進化與人類的進步是相輔相成的。

七、Yejin Choi:AI語言模型還需要有大突破
華盛頓大學計算機科學系副教授Yejin Choi通過著名的視覺幻覺“隧道中的怪物”,談到大腦是如何基于視覺情景理解圖像內容。
隨即,Choi也指出語言理解是未來AI應用很重要的一部分,人類大部分信息和推理都是依靠語言獲取和傳播的,未來AI的語言能力也應該像人類一樣,能夠即時基于當前信息進行推理。她認為這將成為未來AI發展的關鍵和根本性挑戰之一,但目前如GPT-4/5/6等未來新的語言模型都遠遠不足以達到這個目標。

八、Barbara Tversky:生命在于運動
在以上七位科學家討論完關于AI算法的未來預期后,本次圓桌論壇還邀請了五位生物、神經科學領域的專家,討論生物和AI“跨界”合作。
斯坦福大學心理學名譽教授Barbara Tversky認為,所有的生物都必須在空間中運動,運動停止,生命也就終結了。Tversky還談到了人們如何做手勢以及能夠影響人類思維變化的運動。
她說:“學習、思考、溝通、合作以及競爭,都依賴于行動以及少量話語。”
Tversky也同樣擔心當AI模仿人的行為去學習的時候,是否也會“繼承”人類的一些錯誤。如何讓AI有創造力地不斷進化更新,同時規避人類行為中負面的部分,Tversky表示很感興趣。

九、Daniel Kahneman:人類思考范式可被AI借鑒
諾貝爾經濟學獎得主、AI推理問題權威書籍《快思慢想》(Thinking, Fast and Slow)作者Daniel Kahneman認為世界上存在兩種思考范式,一種是直觀的認知,比如依靠生活經驗,我們可以預測到絕大多數可能將會發生的事,另一種是更高級的推理形式,比如我們能從更寬闊的視角,推測那些可能“反常識”的事件。
Kahneman認為這種人類思考范式可以被AI所借鑒,發展出AI模型自己的思維,也能回答Pearl之前提到過的因果推理問題。
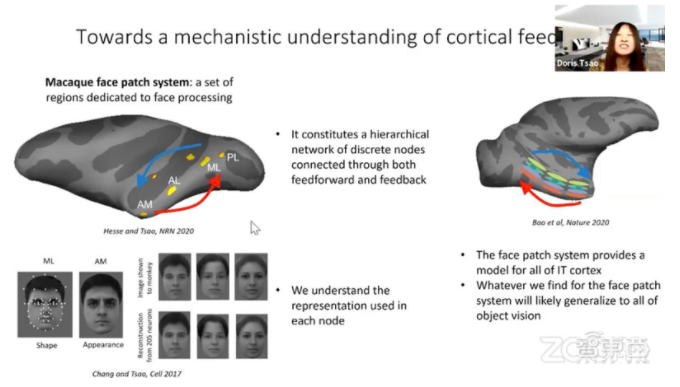
十、Doris Tsao:機器學習與神經科學攜手共進
加州理工學院生物學教授Doris Tsao基于對神經元的研究,認為反饋系統不僅在生物神經傳導中非常重要,在多層神經網絡的反向傳播中也有很大作用。
她說道,反饋或許不僅能讓人們構建出魯棒性更強的視覺系統,也能幫助人類理解為什么會產生幻覺。
Tsao同時也對機器學習與神經科學跨學科合作的未來充滿希望。
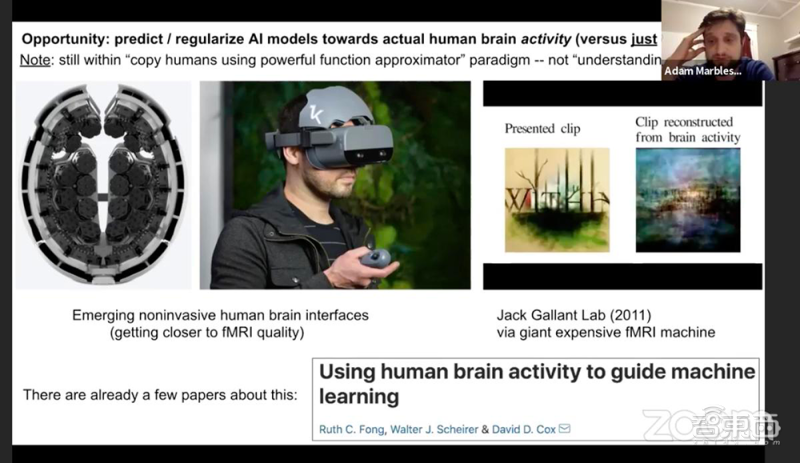
十一、Adam Marblestone:卷積神經網絡對人腦的模范還非常“初級”
前DeepMind教授、加州理工學院神經科學專家Adam Marblestone探討了人類大腦運行規律和神經網絡算法的異同。
在討論中,Marblestone提到目前用功能核磁共振成像技術對人類腦部活動進行分析,研究人類是如何對物體進行分類。他認為目前科學家對大腦的研究還處于非常原始的階段,像卷積神經網絡之類的算法也只是簡單地復制了人類思維過程。
十二、Christof Koch:借鑒人腦發展AI尚不可行
西雅圖艾倫腦科學研究所研究員Christof Koch則提出了不一樣的觀點。他認為科學家了解人腦至少還需要一兩百年的事件,指望借助神經科學來助力人工智能的發展是行不通的,人腦與AI等人造物體的特性完全不同。
Koch的觀點與上述幾位神經學家的觀點發生了激烈的碰撞。
針對Koch和Marblestone關于“細胞的傳導與神經網絡中節點的傳導具有相似性”的反駁,Koch回答,即使是人類細胞自身也大不相同,例如視覺神經元與前額葉皮質神經元就非常不同,而換到神經網絡等人造算法上,情況則更加多樣。
Marblestone則認為Koch的觀點需要更多實癥證明。

十三、Celeste Kidd:AI偏見助長社會中已有的歧視情緒
隨著論壇進入了第三個模塊,四位受邀專家開始討論AI對人類社會倫理道德和生活的影響。
加州大學伯克利分校教授Celeste Kidd的研究課題是人類如何形成認知。Kidd認為,AI系統的偏見強化了使用者的偏見,內容推薦系統會使人們對已有偏見堅信不疑,而亞馬遜和領英的AI招聘系統則會對女性候選者造成負面影響。
Kidd說:“像Timnit Gebru被谷歌解雇這件事一樣,因為AI引起的紛爭可能會成為常態。”

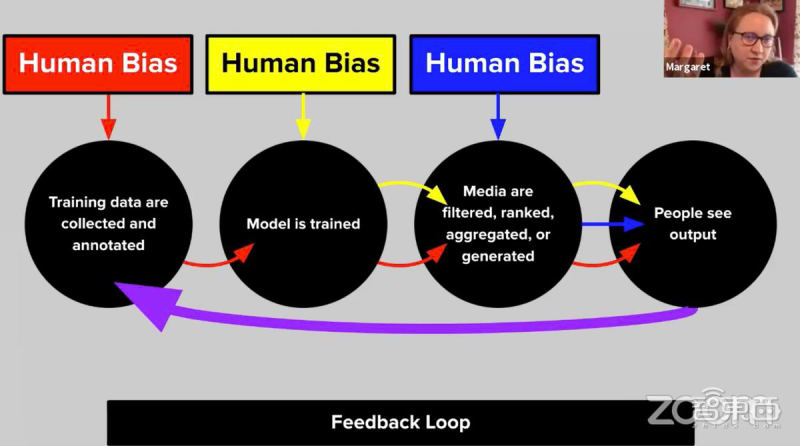
十四、Margaret Mitchell:用技術攻破技術“偏見”
谷歌高級研究科學家Margaret Mitchell認為這些偏見是源于模型本身的創建過程。
通常開發機器學習算法,需要經歷收集數據、訓練模型、評估模型以及使用的過程。但在收集、標記數據的過程中,人類參與必不可少,這就注定了模型會帶有一些來自于開發者的偏見。
Mitchell說:“技術有技術的優勢,但技術本身確實會帶有一定風險。我們試圖解決這些問題,用如洗刷偏見(bias laundering)等方法去減少系統中的偏見。”
十五、Francesca Rossi:如何建立可信任的AI生態系統
承接著Mitchell的話題,IBM的Rossi談到如何創建可信任的AI生態系統。
Rossi說道,一個成熟的AI系統需要涵蓋許多特點,比如準確性、一致性、公平性和可解釋性。如何向人類同伴們,解釋機器是如何工作的非常重要,這也是Mitchell所提到的洗刷偏見的問題。
Rossi認為,這個過程依舊需要大量的研究和試驗,保證模型如何在訓練階段就能很大程度上消除偏見,神經符號AI以及Kahneman所提到的兩種人類思維范式都會是今后的研究方向。
十六、Ryan Calo:AI將會給法律帶來改變
本次論壇最后一個演講嘉賓是華盛頓大學法學教授Ryan Calo。
他認為技術是很難被監管的,我們只有讓法律跟著AI的變化進行相應的規定,而實施的第一步就是評估AI對人類生活在哪些方面產生影響,每個方面又有多大程度的影響,再讓法律靈活地進行調整。
AI也必然會帶來法律的修改,無論是目前公眾關于AI“公平”與否的爭論,還是法律界內部的討論,目的都只有一個,就是保證AI技術成本和收益平均分配,在便利人民生活的同時,防止對個人隱私的侵犯。
結語:讓世界變得更好的AI初心
當三個小時的論壇快結束時,主持人Marcus問了所有嘉賓一個問題:“AI走到哪一個地步你們會滿意,我們構建AI的終極目標是什么?”
盡管每位學者回答的角度和內容都不同,但有三個詞反反復復地出現:有趣、友善和公平,而最后的落腳點也只有一個,用技術讓所有人過上更好的生活。
或許這個過程會有偏差和坎坷:算法會不公、監管會不全……但每位AI研究者依舊懷抱著純粹的初心,在2020末尾的冬夜里,隔著遙遙網線,暢談著AI的下一個十年。

















