GPT-3今年首次升級,吳恩達、Keras之父等大佬紛紛叫好
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
2021年一開始,OpenAI在GPT-3方向上的又一重要突破,讓吳恩達等大佬激動了。
之前給GPT-3一段話,就能寫出一段小說。
現在它成功跨界——可以按照文字描述、生成對應圖片!

簡直就是“甲方克星、乙方福音”,提需求愛描述的甲方老板,現在直接嗶嗶就能立竿見影得到效果圖。
比如你輸入“OpenAI公司門面”,它就能給出設計圖:

這個新的AI,叫做DALL·E(Dali + Wall-E)。
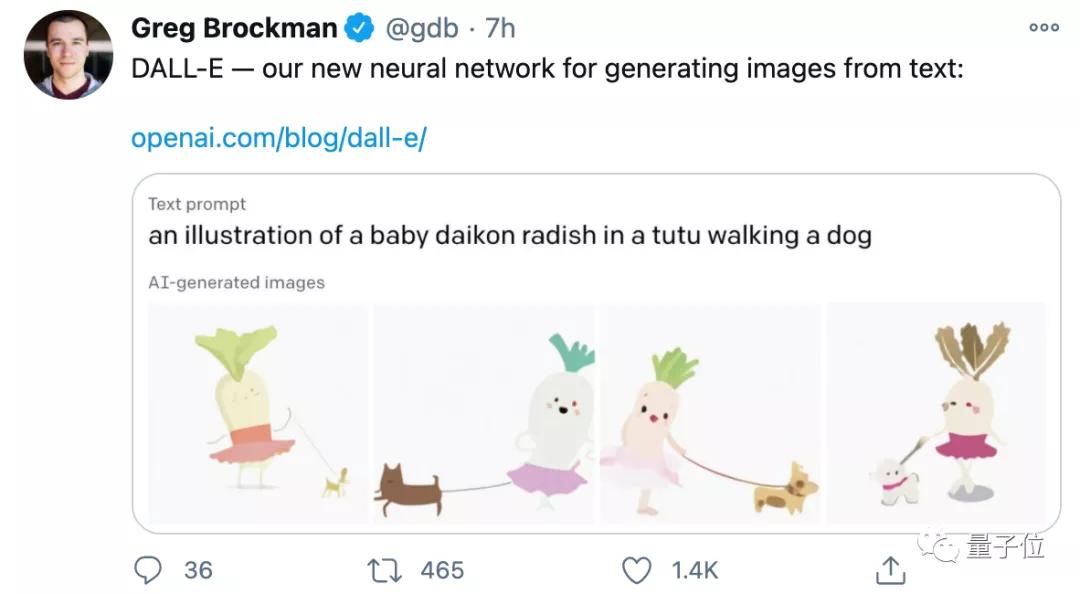
除了生成現實中的圖片外,DALL·E還能按要求設計出“一顆白菜穿著芭蕾舞裙在遛狗”,妥妥的漫畫風。

從“五邊形鬧鐘”到“牛油果形狀的座椅”,只要你的想象力夠豐富,DALL·E全都能畫出來。


技術上更厲害的是,OpenAI透露這個AI是基于GPT-3而構建,僅使用了120億個參數樣本,相當于GPT-3參數量的十四分之一。
于是效果一出,吳恩達、Keras之父等紛紛轉發、點贊。堪稱2021年第一個令人興奮的AI技術突破。
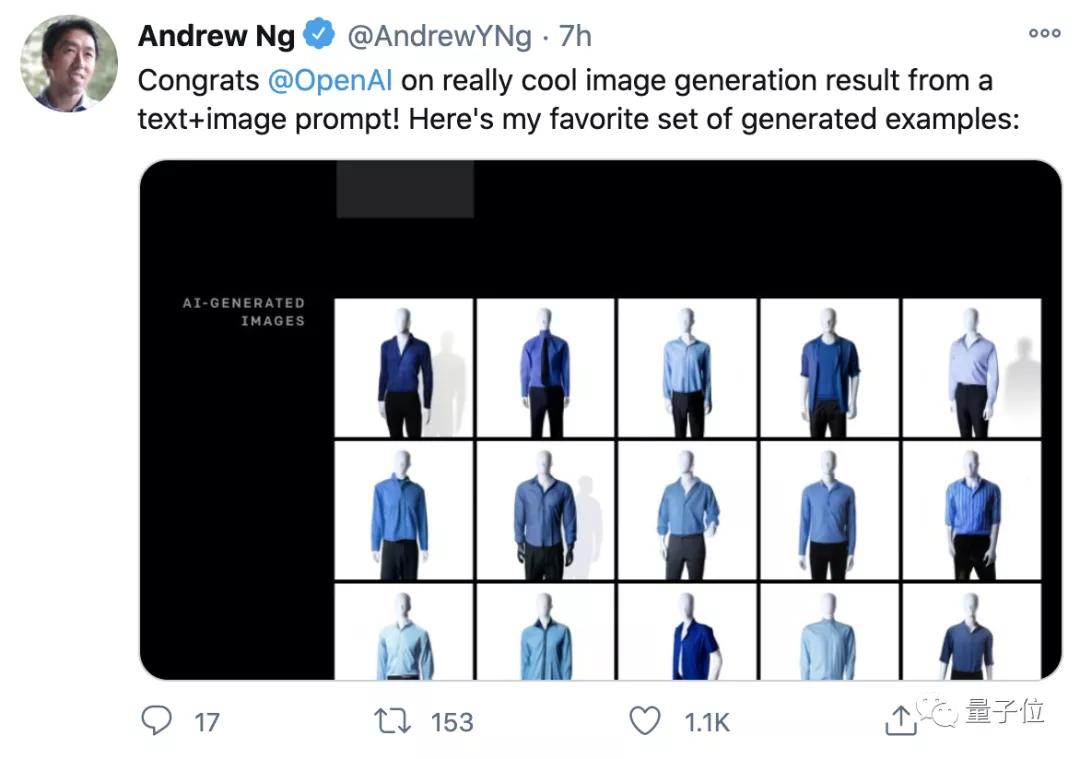
看吳恩達老師pick的這個demo效果,以后是想直接描述生成自己想要的藍工裝?
“圖像版”GPT-3,還自帶排名
生成這些優秀作品的,是一個名為DALL·E的結構。
DALL·E的名字,來源于大藝術家達利(Dalí)和皮克斯動畫《機器人總動員》中的主角“瓦力”(WALL·E)。
本質上,它就是一個被重新訓練過的“120億參數版”GPT-3,能根據一段文字描述,生成對應的圖像。
為了讓DALL·E能“識字畫圖”,研究者們用包含各種“文本-圖像”組合的數據集,來訓練DALL·E。
這其中,DALL·E以單數據流的形式,一次性接收1280個字符(token),其中256個字符分配給文字,其余的1024個則分配給圖像。

DALL·E將對這些輸入信息進行建模,利用自注意力層的注意力遮罩,確保每一個輸入的圖像字符,都與所有輸入的文字字符關聯。
然后DALL·E將根據文本,通過最大似然估計,逐個字符生成圖像。它不僅能從文字中,生成一整幅草圖,還能重新生成圖像中的任何一塊矩形區域。

這就完了?
當然沒有,我們最終看到的作品,其實只是DALL·E創作的一部分,即“優秀作品選”。
也就是說,還需要一個網絡CLIP,來對它生成的這些作品進行排名、打分。
越是CLIP看得懂、匹配度最高的作品,分數就會越高,排名也會越靠前。
這種結構,有點像是利用生成對抗文本,以合成圖像的GAN。不過,相比于利用GAN擴大圖像分辨率、匹配圖像-文本特征等方法,CLIP則選擇了直接對輸出進行排名。
據研究人員表示,CLIP網絡的最大意義在于,它緩解了深度學習在視覺任務中,最大的兩個問題。
首先,它降低了深度學習需要的數據標注量。相比于手動在ImageNet上,用文字描述1400萬張圖像,CLIP直接從網上已有的“文字描述圖像”數據中進行學習。

此外,CLIP還能“身兼多職”,在各種數據集上的表現都很好(包括沒見過的數據集)。但此前的大部分視覺神經網絡,只能在訓練的數據集上有不錯的表現。
例如,CLIP與ResNet101相比,在各項數據集上都有不錯的檢測精度,然而ResNet101在除了ImageNet以外的檢測精度上,表現都不太好。
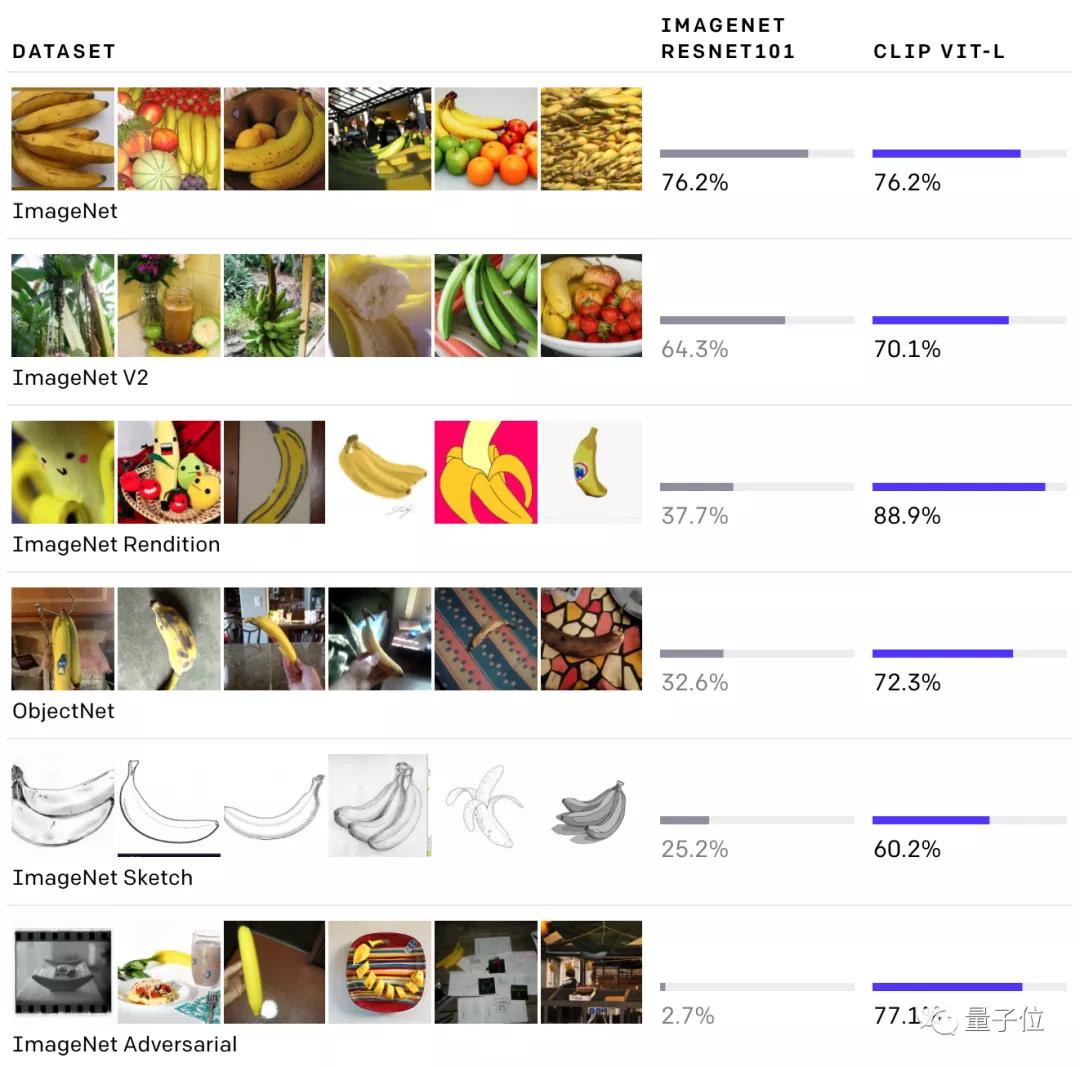
具體來說,CLIP用到了零樣本學習(zero-shot learning)、自然語言理解和多模態學習等技術,來完成圖像的理解。
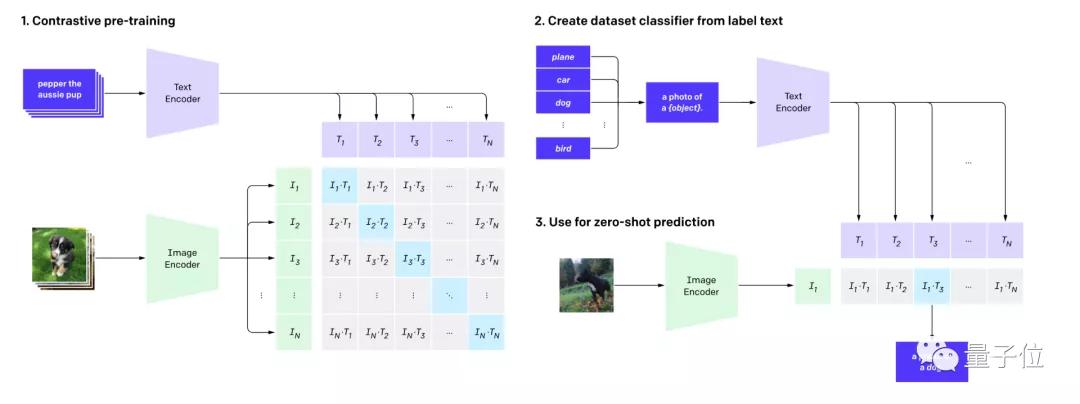
例如,描述一只斑馬,可以用“馬的輪廓+虎的皮毛+熊貓的黑白”。這樣,網絡就能從沒見過的數據中,找出“斑馬”的圖像。
最后,CLIP將文本和圖像理解結合起來,預測哪些圖像,與數據集中的哪些文本能完成最好的配對。
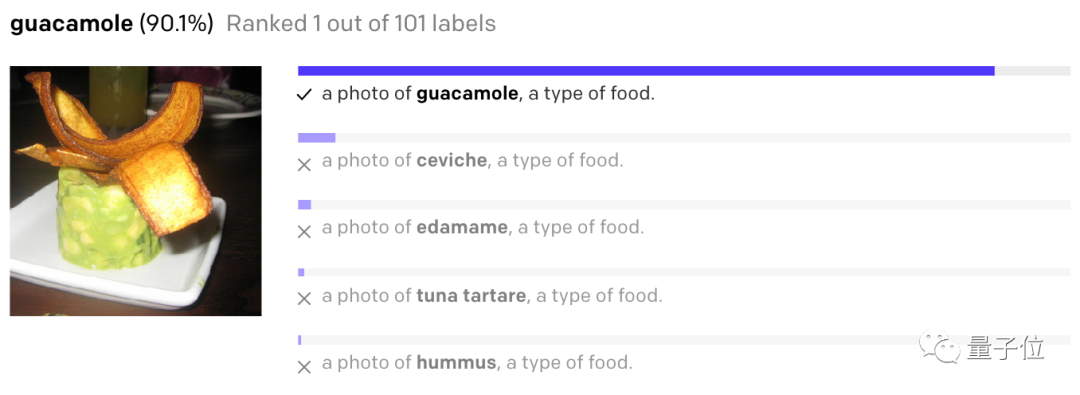
此次生成的Demo圖像,正是從512個樣本中,用CLIP選出的前32個樣本。研究人員強調,整個過程他們全程沒有參與。
有哪些初步效果?
此次上線的Demo,大致分成這幾類效果。
控制變量,修改物體的屬性(數量、顏色)。

甚至,還可以加上個年代屬性。輸入文字:電話。
那這個電話放在未來呢?竟然會是這個亞子。

同時控制多個對象。比如,戴紅色帽子,黃色手套,藍色襯衫和綠色褲子的企鵝。
說實話,要換成是我,我一個也畫不出來。(手動裂開)

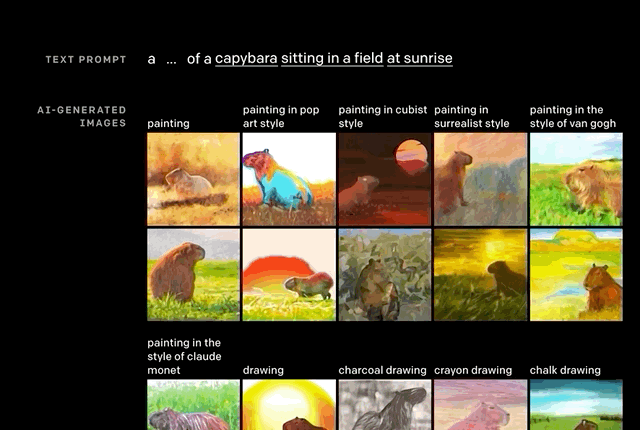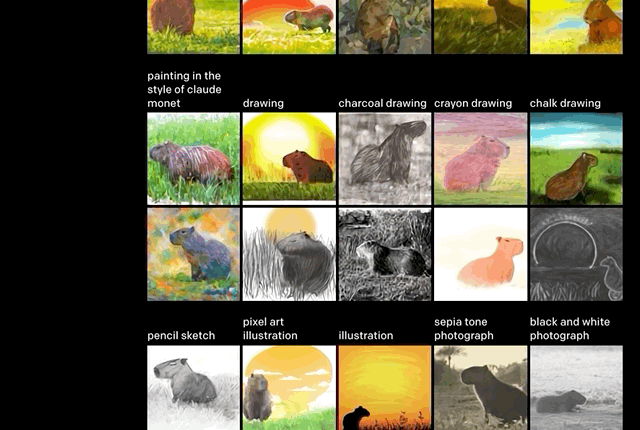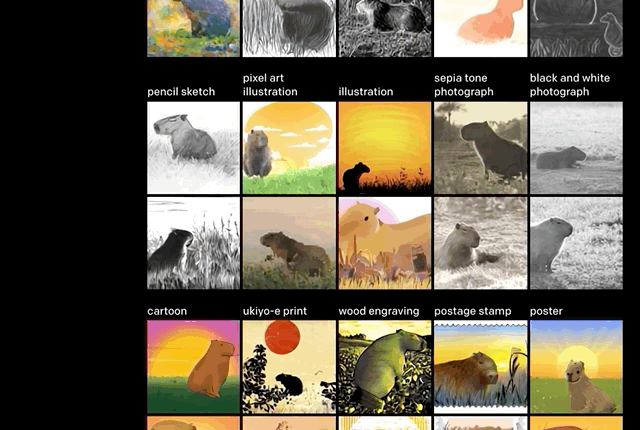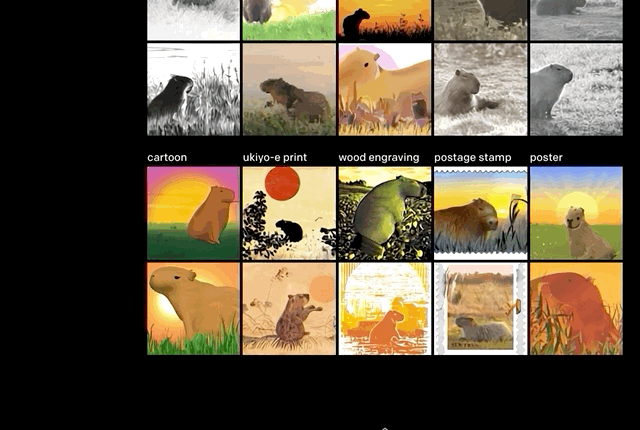
推斷細節。正如上文舉的例子,“沐浴在朝陽中的田間水豚”。
單從文字上看,還有很多細節需要考究:水豚位置,陰影有無,繪畫風格。但這些,似乎都沒有難到DALL·E。
大佬們紛紛給出好評
對于OpenAI這個新鮮出爐的DALL·E,大佬們也紛紛發表了自己的看法。
Keras創始人@François Chollet表示,這看起來非常酷,尤其是“圖像生成”部分。
從原理上來看,應該就是GPT-3在文本合成圖像方向上的擴展版。

OpenAI的CTO Greg Brockman在轉發DALL·E后,更是立刻獲得了1.4k的贊。
英偉達的機器學習專家Ming-Yu Liu,也送上了自己的祝福。
他表示,這樣的模型在文本轉圖像的能力上,簡直超乎想象。

當然,也有對這種方法的限制感到困惑的學者。
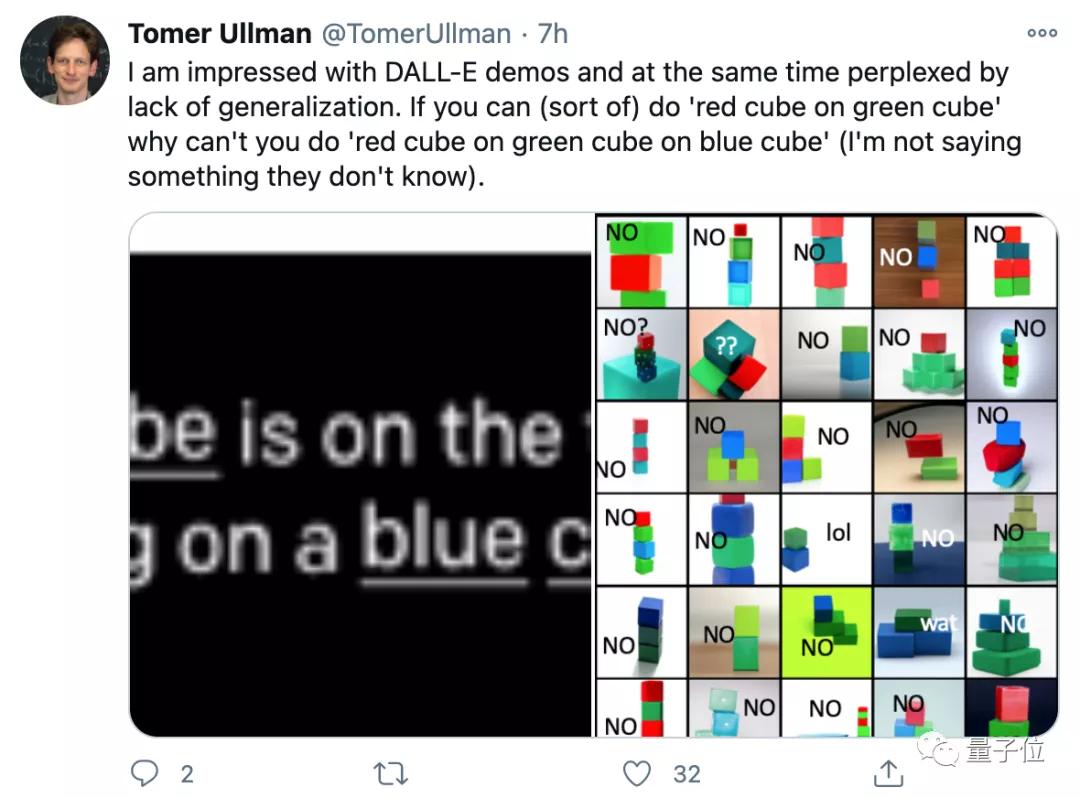
來自哈佛的助理教授Tomer Ullman,在對DALL·E的能力表示驚嘆時,也提出了對于模型泛化能力限制的疑惑。
他認為,如果能生成“綠方塊上的紅方塊”,模型理應也能生成“藍方塊上的綠方塊上的紅方塊”?
希望這樣的模型,能在提升泛化等能力后,真正被用來減輕設計師們的負擔。
當然,如果再開一開腦洞的話,應用前景可能不止于減輕負擔。
如果效果足夠好,還要什么乙方設計師?
以及像動畫、影視等領域,是不是未來劇本一放,AI就能給你出成果了?