













下一代消息隊列Pulsar到底是什么?
本文轉載自微信公眾號「咖啡拿鐵」,作者咖啡拿鐵 。轉載本文請聯系咖啡拿鐵公眾號。
背景
之前琢磨了很久一直想寫一篇pulsar相關的文章,但是一直知識儲備不夠,對于很多細節(jié)還是不了解,于是查了很多資料,總算是可以湊出一篇文章了。
Pulsar是一個由yahoo公司于2016年開源的消息中間件,2018年成為Apache的頂級項目。在我之前的文章中寫過很多其他消息中間件的文章,比如kafka,rocketmq等等。
在開源的業(yè)界已經有這么多消息隊列中間件了,pulsar作為一個新勢力到底有什么優(yōu)點呢?pulsar自從出身就不斷的再和其他的消息隊列(kafka,rocketmq等等)做比較,但是Pulsar的設計思想和大多數的消息隊列中間件都不同,具備了高吞吐,低延遲,計算存儲分離,多租戶,異地復制等功能,所以pulsar也被譽為下一代消息隊列中間件,接下來我會一一對其進行詳細的解析。
pulsar架構原理
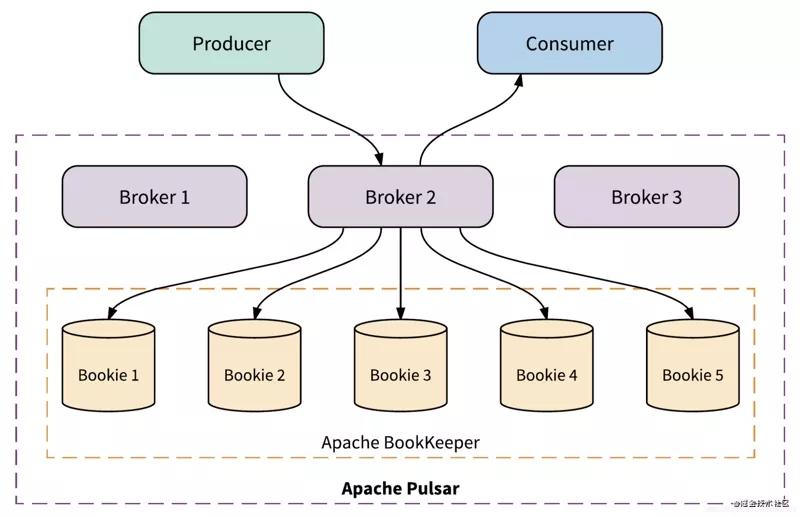
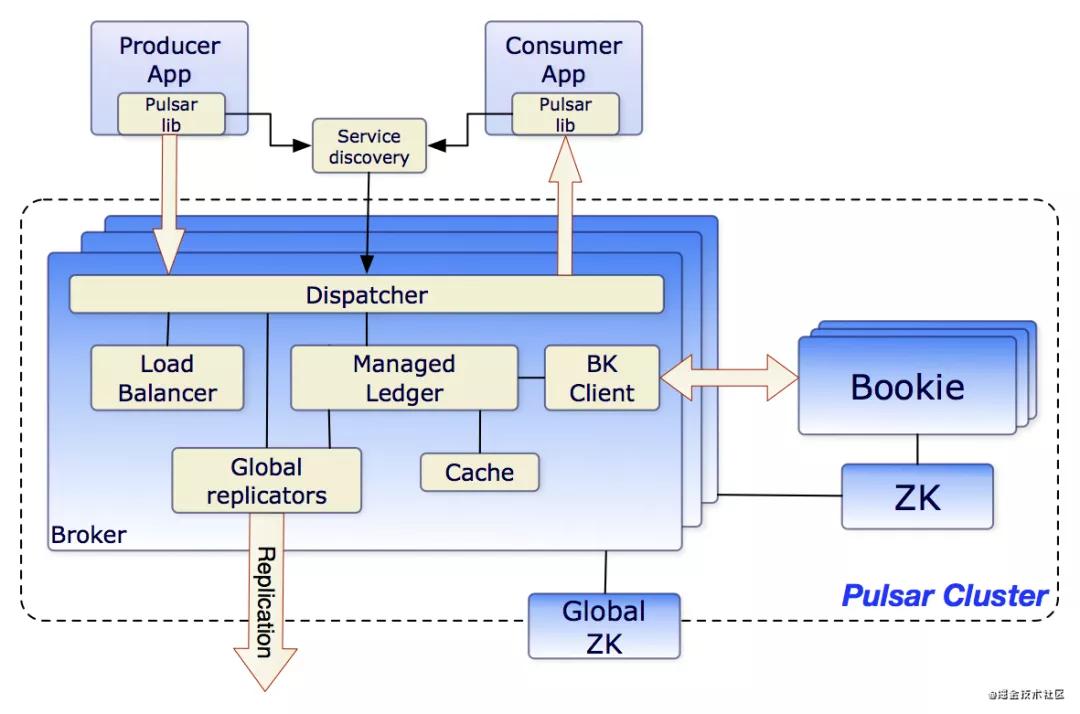
整體的架構和其他的消息隊列中間件差別不是太大,相信大家也看到了很多熟悉的名詞,接下來會給大家一一解釋這些名詞的含義。
名詞解釋
- Producer:消息生產者,將消息發(fā)送到broker。
- Consumer:消息消費者,從Broker讀取消息到客戶端,進行消費處理。
- Broker: 可以看作是pulsar的server,Producer和Consumer都看作是client.消息處理的節(jié)點,pulsar的Broker和其他消息中間件的都不一樣,他是無狀態(tài)的沒有存儲,所以可以無限制的擴展,這個后面也會詳解講到。
- Bookie: 負責所有消息的持久化,這里采用的是Apache Bookeeper。
- ZK: 和kafka一樣pulsar也是使用zk保存一些元數據,比如配置管理,topic分配,租戶等等。
- Service Discovery:可以理解為Pulsar中的nginx,只用一個url就可以和整個broker進行打交道,當然也可以使用自己的服務發(fā)現。客戶端發(fā)出的讀取,更新或刪除主題的初始請求將發(fā)送給可能不是處理該主題的 broker 。如果這個 broker 不能處理該主題的請求,broker 將會把該請求重定向到可以處理主題請求的 broker。
不論是kafka,rocketmq還是我們的pulsar其實作為消息隊列中間件最為重要的大概就是分為三個部分:
- Producer是如何生產消息,發(fā)送到對應的Broker
- Broker是如何處理消息,將高效的持久化以及查詢
- Consumer是如何進行消費消息
而我們后面也會圍繞著這三個部分進行展開講解。
Producer生產消息
先簡單看一下如何用代碼進行消息發(fā)送:
- PulsarClient client = PulsarClient.create("pulsar://pulsar.us-west.example.com:6650");
- Producer producer = client.createProducer(
- "persistent://sample/standalone/ns1/my-topic");
- // Publish 10 messages to the topic
- for (int i = 0; i < 10; i++) {
- producer.send("my-message".getBytes());
- }
- Step1: 首先使用我們的url創(chuàng)建一個client這個url是我們service discovery的地址,如果我們使用單機模式可以進行直連
- Step2:我們傳入了一個類似url的參數,我們只需要傳遞這個就能指定我們到底在哪個topic或者namespace下面創(chuàng)建的:
| 組成 | 含義 |
|---|---|
| persistent/non-persistent | Pulsar 提供持久化、非持久化兩種主題,如果選擇的是非持久化主題的話,所有消息都在內存中保存,如果broker重啟,消息將會全部丟失。如果選擇的是持久化主題,所有消息都會持久化到磁盤,重啟broker,消息也可以正常消費。 |
| tenant | 顧名思義就是租戶,pulsar最開始在雅虎內部是作為全公司使用的中間件使用的,需要給topic指定一些層級,租戶就是其中一層,比如這個可以是一個大的部門,例如電商中臺租戶。 |
| namespace | 命名空間,可以看作是第二層的層級,比如電商中臺下的訂單業(yè)務組 |
| topic | 消息隊列名字 |
- Step3: 調用send方法發(fā)送消息,這里也提供了sendAsync方法支持異步發(fā)送。
上面三個步驟中,步驟1,2屬于我們準備階段,用于構建客戶端,構建Producer,我們真的核心邏輯在send中,那這里我先提幾個小問題,大家可以先想想在其他消息隊列中是怎么做的,然后再對比pulsar的看一下:
- 我們調用了send之后是會立即發(fā)送嗎?
- 如果是多partition,怎么找到我應該發(fā)送到哪個Broker呢?
發(fā)送模式
我們上面說了send分為async和sync兩種模式,但實際上在pulsar內部sync模式也是采用的async模式,在sync模式下模擬回調阻塞,達到同步的效果,這個在kafka中也是采用的這個模式,但是在rocketmq中,所有的send都是真正的同步,都會直接請求到broker。
基于這個模式,在pulsar和kafka中都支持批量發(fā)送,在rocketmq中是直接發(fā)送,批量發(fā)送有什么好處呢?當我們發(fā)送的TPS特別高的時候,如果每次發(fā)送都直接和broker直連,可能會做很多的重復工作,比如壓縮,鑒權,創(chuàng)建鏈接等等。比如我們發(fā)送1000條消息,那么可能會做1000次這個重復的工作,如果是批量發(fā)送的話這1000條消息合并成一次請求,相對來說壓縮,鑒權這些工作就只需要做一次。
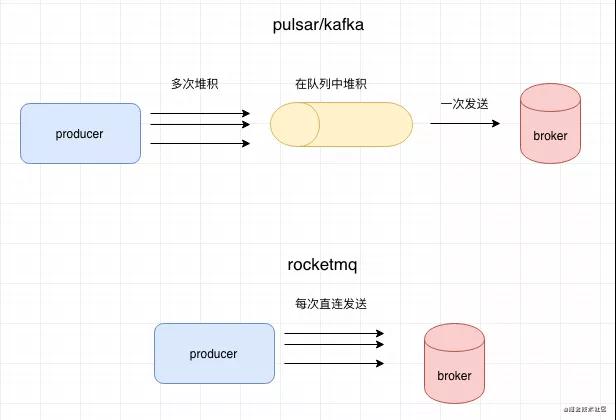
有同學可能會問,批量發(fā)送會不會導致發(fā)送的時間會有一定的延誤?這個其實不需要擔心,在pulsar中默認定時每隔1ms發(fā)送一次batch,或者當batchsize默認到了1000都會進行發(fā)送,這個發(fā)送的頻率都還是很快的。
發(fā)送負載均衡
在消息隊列中通常會將topic進行水平擴展,在pulsar和kafka中叫做partition,在rocketmq中叫做queue,本質上都是分區(qū),我們可以將不同分區(qū)落在不同的broker上,達到我們水平擴展的效果。
在我們發(fā)送的時候可以自己制定選擇partition的策略,也可以使用它默認輪訓partition策略。當我們選擇了partition之后,我們怎么確定哪一個partition對應哪一個broker呢?
可以先看看下面這個圖:
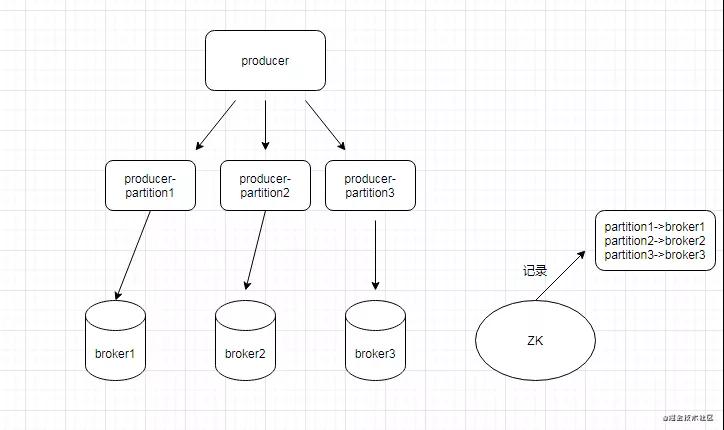
- Step1: 我們所有的信息分區(qū)映射信息在zk和broker的緩存中都有進行存儲。
- Step2: 我們通過查詢broker,可以獲取到分區(qū)和broker的關系,并且定時更新。
- Step3: 在pulsar中每個分區(qū)在發(fā)送端的時候都被抽象成為一個單獨的Producer,這個和kafka,rocketmq都不一樣,在kafka里面大概就是選擇了partition之后然后再去找partition對應的broker地址,然后進行發(fā)送。pulsar將每一個partition都封裝成Producer,在代碼實現上就不需要去關注他具體對應的是哪個broker,所有的邏輯都在producer這個代碼里面,整體來說比較干凈。

壓縮消息
消息壓縮是優(yōu)化信息傳輸的手段之一,我們通常看見一些大型文件都會是以一個壓縮包的形式提供下載,在我們消息隊列中我們也可以用這種思想,我們將一個batch的消息,比如有1000條可能有1M的傳輸大小,但是經過壓縮之后可能就只會有幾十kb,增加了我們和broker的傳輸效率,但是與之同時我們的cpu也帶來了損耗。Pulsar客戶端支持多種壓縮類型,如 lz4、zlib、zstd、snappy 等。
- client.newProducer()
- .topic(“test-topic”)
- .compressionType(CompressionType.LZ4)
- .create();
Broker
接下來我們來說說第二個比較重要的部分Broker,在Broker的設計中pulsar和其他所有的消息隊列差別比較大,而正是因為這個差別也成為了他的特點。
計算和存儲分離
首先我們來說說他最大的特點:計算和存儲分離。我們在開始的說過Pulsar是下一代消息隊列,就非常得益于他這個架構設計,無論是kafka還是RocketMQ,所有的計算和存儲都放在同一個機器上,這個模式有幾個弊端:
- 擴展困難:當我們需要擴展的集群的時候,我們通常是因為cpu或者磁盤其中一個原因影響,但是我們卻要申請一個可能cpu和磁盤配置都很好的機器,造成了資源浪費。并且kafka這種進行擴展,還需要進行遷移數據,過程十分繁雜。
- 負載不均衡:當某些partion數據特別多的時候,會導致broker負載不均衡,如下面圖,如果某個partition數據特別多,那么就會導致某個broker(輪船)承載過多的數據,但是另外的broker可能又比較空閑

pulsar計算分離架構能夠非常好的解決這個問題:
- 對于計算:也就是我們的broker,提供消息隊列的讀寫,不存儲任何數據,無狀態(tài)對于我們擴展非常友好,只要你機器足夠,就能隨便上。擴容Broker往往適用于增加Consumer的吞吐,當我們有一些大流量的業(yè)務或者活動,比如電商大促,可以提前進行broker的擴容。
- 對于存儲:也就是我們的bookie,只提供消息隊列的存儲,如果對消息量有要求的,我們可以擴容bookie,并且我們不需要遷移數據,擴容十分方便。
消息存儲
名詞解析:
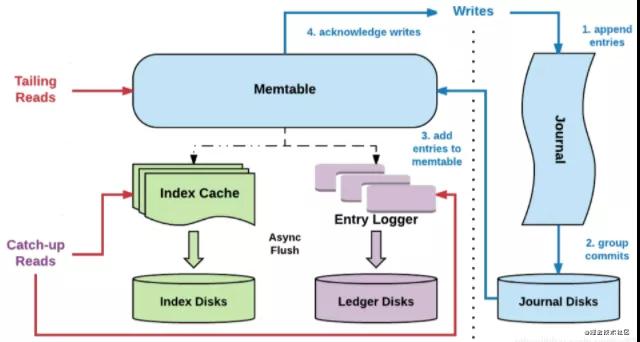
上圖是bookie的讀寫架構圖,里面有一些名詞需要先介紹一下:
- Entry,Entry是存儲到bookkeeper中的一條記錄,其中包含Entry ID,記錄實體等。
- Ledger,可以認為ledger是用來存儲Entry的,多個Entry序列組成一個ledger。
- Journal,其實就是bookkeeper的WAL(write ahead log),用于存bookkeeper的事務日志,journal文件有一個最大大小,達到這個大小后會新起一個journal文件。
- Entry log,存儲Entry的文件,ledger是一個邏輯上的概念,entry會先按ledger聚合,然后寫入entry log文件中。同樣,entry log會有一個最大值,達到最大值后會新起一個新的entry log文件
- Index file,ledger的索引文件,ledger中的entry被寫入到了entry log文件中,索引文件用于entry log文件中每一個ledger做索引,記錄每個ledger在entry log中的存儲位置以及數據在entry log文件中的長度。
- MetaData Storage,元數據存儲,是用于存儲bookie相關的元數據,比如bookie上有哪些ledger,bookkeeper目前使用的是zk存儲,所以在部署bookkeeper前,要先有zk集群。
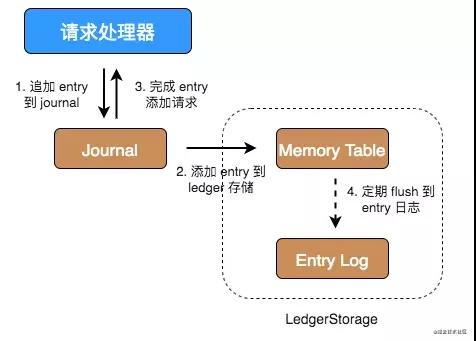
整體架構上的寫流程:
- Step1: broker發(fā)起寫請求,首先對Journal磁盤寫入WAL,熟悉mysql的朋友知道redolog,journal和redolog作用一樣都是用于恢復沒有持久化的數據。
- Step2: 然后再將數據寫入index和ledger,這里為了保持性能不會直接寫盤,而是寫pagecache,然后異步刷盤。
- Step3: 對寫入進行ack。
讀流程為:
- Step1: 先讀取index,當然也是先讀取cache,再走disk。
- Step2: 獲取到index之后,根據index去entry logger中去對應的數據
如何高效讀寫?
在kafka中當我們的topic變多了之后,由于kafka一個topic一個文件,就會導致我們的磁盤IO從順序寫變成隨機寫。在rocketMq中雖然將多個topic對應一個寫入文件,讓寫入變成了順序寫,但是我們的讀取很容易導致我們的pagecache被各種覆蓋刷新,這對于我們的IO的影響是非常大的。所以pulsar在讀寫兩個方面針對這些問題都做了很多優(yōu)化:
- 寫流程:順序寫 + pagecache。在寫流程中我們的所有的文件都是獨立磁盤,并且同步刷盤的只有Journal,Journal是順序寫一個journal-wal文件,順序寫效率非常高。ledger和index雖然都會存在多個文件,但是我們只會寫入pagecache,異步刷盤,所以隨機寫不會影響我們的性能。
- 讀流程:broker cache + bookie cache,在pulsar中對于追尾讀(tailing read)非常友好基本不會走io,一般情況下我們的consumer是會立即去拿producer發(fā)送的消息的,所以這部分在持久化之后依然在broker中作為cache存在,當然就算broker沒有cache(比如broker是新建的),我們的bookie也會在memtable中有自己的cache,通過多重cache減少讀流程走io。
我們可以發(fā)現在最理想的情況下讀寫的io是完全隔離開來的,所以在Pulsar中能很容易就支持百萬級topic,而在我們的kafka和rocketmq中這個是非常困難的。
無限流式存儲
一個Topic實際上是一個ledgers流(Segment),通過這個設計所以Pulsar他并不是一個單純的消息隊列系統,他也可以代替流式系統,所以他也叫流原生平臺,可以替代flink等系統。
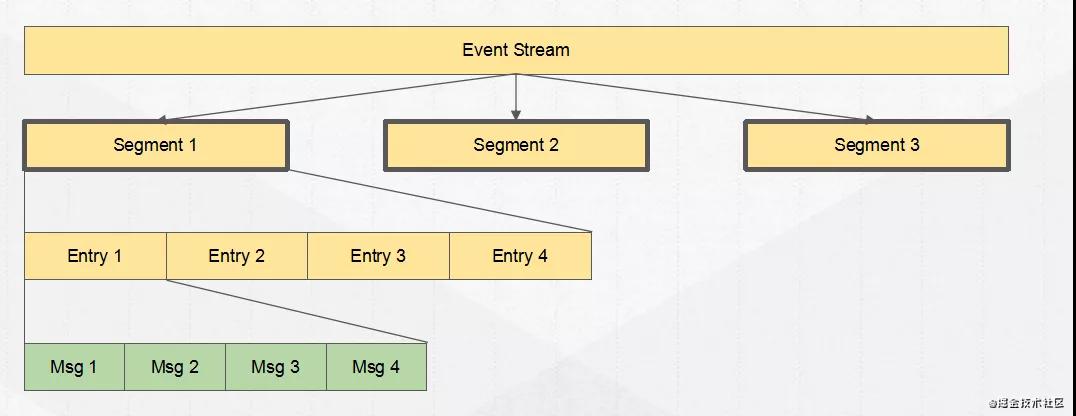
可以看見我們的Event Stream(topic/partition),由多個Segment存儲組成,而每個segment由entry組成,這個可以看作是我們每批發(fā)送的消息通常會看作是一個entry。
Segment可以看作是我們寫入文件的一個基本維度,同一個Segment的數據會寫在同一個文件上面,不同Segment將會是不同文件,而Segment之間的在metadata中進行保存。
分層存儲
在kafka和rocketmq中消息是會有一定的保存時間的,因為磁盤會有空間限制,在pulsar中也提供這個功能,但是如果你想讓自己的消息永久存儲,那么可以使用分級存儲,我們可以將一些比較老的數據,定時的刷新到廉價的存儲中,比如s3,那么我們就可以無限存儲我們的消息隊列了。
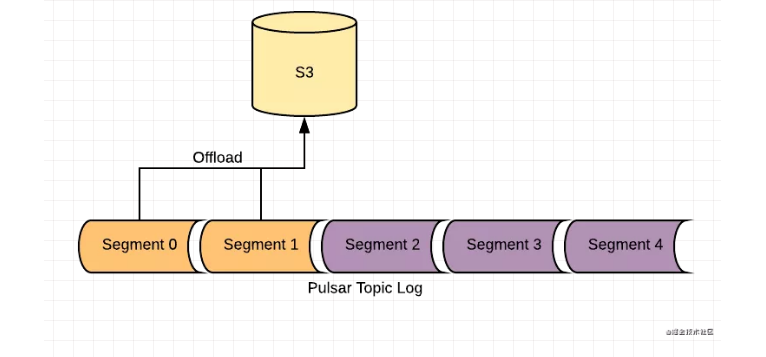
數據復制
在pulsar中的數據復制和kafka,rocketmq都有很大的不同,在其他消息隊列中通常是其他副本主動同步,通常這個時間就會變得不可預測,而在pulsar采用了類似qurom協議,給一組可用的bookie池,然后并發(fā)的寫入其中的一部分bookie,只要返回部分成功(通常大于1/2)就好。
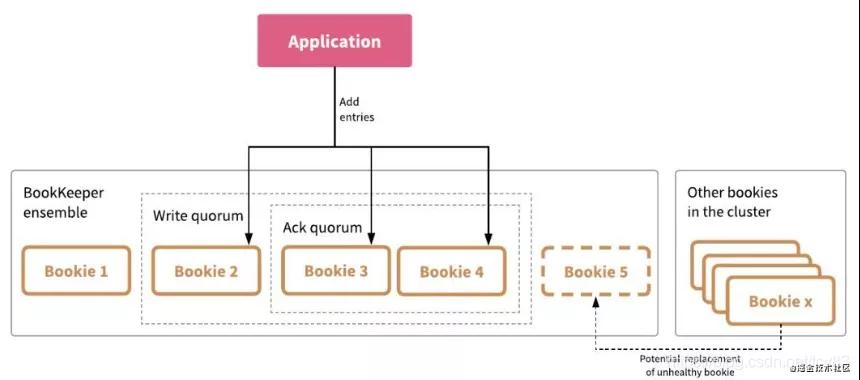
- Ensemble Size(E)決定給定 ledger 可用的 bookie 池大小。
- Write Quorum Size(Qw)指定 Pulsar 向其中寫入 entry 的 bookie 數量。
- Ack Quorum Size(Qa)指定必須 ack 寫入的 bookie 數量。
采用這種并發(fā)寫的方式,會更加高效的進行數據復制,尤其是當數據副本比較多的時候。
Consumer
接下來我們來聊聊pulsar中最后一個比較重要的組成consumer。
訂閱模式
訂閱模式是用來定義我們的消息如何分配給不同的消費者,不同消息隊列中間件都有自己的訂閱模式,一般我們常見的訂閱模式有:
- 集群模式:一條消息只能被一個集群內的消費者所消費。
- 廣播模式:一條消息能被集群內所有的消費者消費。
在pulsar中提供了4種訂閱模式,分別是獨占,災備,共享,鍵共享:
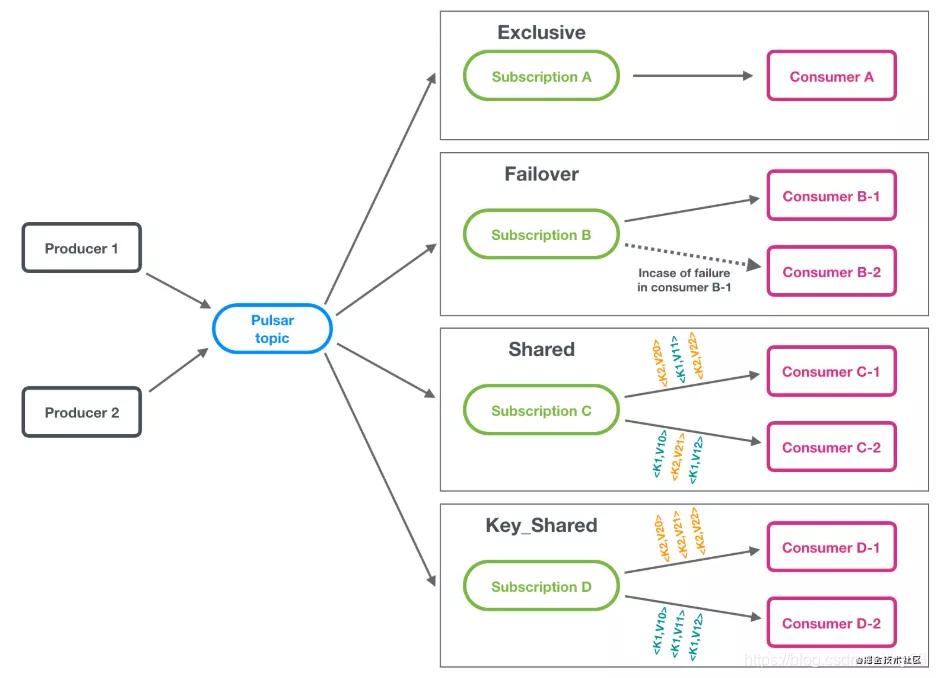
- 獨占:顧名思義只能由一個消費者獨占,如果同一個集群內有第二個消費者去注冊,第二個就會失敗,這個適用于全局有序的消息。
- 災備:加強版獨占,如果獨占的那個掛了,會自動的切換到另外一個好的消費者,但是還是只能由一個獨占。
- 共享模式:這個模式看起來有點像集群模式,一條消息也是只能被一個集群內消費者消費,但是和rocketmq不同的是,rocketmq是以partition維度,同一個Partition的數據都會被發(fā)到一個機器上。在Pulsar中消費不會以partition維度,而是輪訓所有消費者進行消息發(fā)送。這有個什么好處呢?如果你有100臺機器,但是你只有10個partition其實你只有10臺消費者能運轉,但是在pulsar中100臺機器都可以進行消費處理。
- 鍵共享:類似上面說的partition維度去發(fā)送,在rocketmq中同一個key的順序消息都會被發(fā)送到一個partition,但是這里不會有partition維度,而只是按照key的hash去分配到固定的consumer,也解決了消費者能力限制于partition個數問題。
消息獲取模式
不論是在kafka還是在rocketmq中我們都是client定時輪訓我們的broker獲取消息,這種模式叫做長輪訓(Long-Polling)模式。這種模式有一個缺點網絡開銷比較大,我們來計算一下consumer被消費的時延,我們假設broker和consumer之間的一次網絡延時為R,那么我們總共的時間為:
- 當某一條消息A剛到broker的,這個時候long-polling剛好打包完數據返回,broker返回到consumer這個時間為R。
- consumer又再次發(fā)送request請求,這個又為R。
- 將我們的消息A返回給consumer這里又為R。
如果只考慮網絡時延,我們可以看見我們這條消息的消費時延大概是3R,所以我們必須想點什么對其進行一些優(yōu)化,有同學可能馬上就能想到,我們消息來了直接推送給我們的consumer不就對了,這下我們的時延只會有一次R,這個就是我們常見的推模式,但是簡單的推模式是有問題的,如果我們有生產速度遠遠大于消費速度,那么推送的消息肯定會干爆我們的內存,這個就是背壓。那么我們怎么解決背壓呢?我們就可以優(yōu)化推送方式,將其變?yōu)閯討B(tài)推送,我們結合Long-polling,在long-polling請求時將Buffer剩余空間告知給Broker,由Broker負責推送數據。此時Broker知道最多可以推送多少條數據,那么就可以控制推送行為,不至于沖垮Consumer。
舉個例子:
Consumer發(fā)起請求時Buffer剩余容量為100,Broker每次最多返回32條消息,那么Consumer的這次long-polling請求Broker將在執(zhí)行3次push(共push96條消息)之后返回response給Consumer(response包含4條消息)。
如果采用long-polling模型,Consumer每發(fā)送一次請求Broker執(zhí)行一次響應,這個例子需要進行4次long-polling交互(共4個request和4個response,8次網絡操作;Dynamic Push/Pull中是1個request,三次push和一個response,共5次網絡操作)。
所以pulsar就采用了這種消息獲取模式,從consumer層進一步優(yōu)化消息達到時間。我覺得這個設計非常巧妙,很多中間件的這種long-polling模式都可以參考這種思想去做一個改善。
總結
Apache Pulsar很多設計思想都和其他中間件不一樣,但無疑于其更加貼近于未來,大膽預測一下其他的一些消息中間件未來的發(fā)展也都會向其靠攏,目前國內的Pulsar使用者也是越來越多,騰訊云提供了pulsar的云版本TDMQ,當然還有一些其他的知名公司華為,知乎,虎牙等等有都在對其做一個逐步的嘗試,我相信pulsar真的是一個趨勢。最后也讓我想起了最近大江大河大結局的一句話:
所有的變化,都可能伴隨著痛苦和彎路,開放的道路,也不會是闊野坦途,但大江大河,奔涌向前的趨勢,不是任何險灘暗礁,能夠阻擋的。道之所在,雖千萬人吾往矣。














