













Pulsar:下一代消息引擎真的這么強嗎?
背景
我們最近在做新業務的技術選型,其中涉及到了對消息中間件的選擇;結合我們的實際情況希望它能滿足以下幾個要求:
- 友好的云原生支持:因為現在的主力語言是 Go,同時在運維上能夠足夠簡單。
- 官方支持多種語言的 SDK:還有一些 Python、Java 相關的代碼需要維護。
- 最好是有一些方便好用的特性,比如:延時消息、死信隊列、多租戶等。
當然還有一些水平擴容、吞吐量、低延遲這些特性就不用多說了,幾乎所有成熟的消息中間件都能滿足這些要求。
基于以上的篩選條件,Pulsar 進入了我們的視野。
作為 Apache 下的頂級項目,以上特性都能很好的支持。
下面我們來它有什么過人之處。
架構
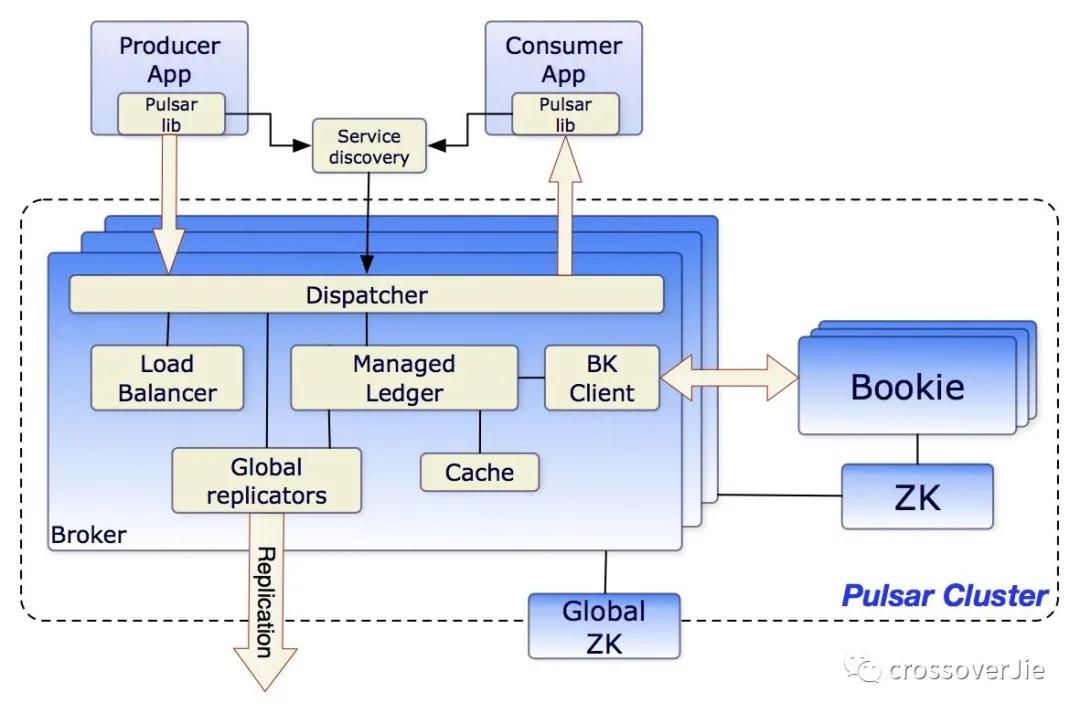
從官方的架構圖中可以看出 Pulsar 主要有以下組件組成:
- Broker 無狀態組件,可以水平擴展,主要用于生產者、消費者連接;與 Kafka 的 broker 類似,但沒有數據存儲功能,因此擴展更加輕松。
- BookKeeper 集群:主要用于數據的持久化存儲。
- Zookeeper 用于存儲 broker 與 BookKeeper 的元數據。
整體一看似乎比 Kafka 所依賴的組件還多,這樣確實會提供系統的復雜性;但同樣的好處也很明顯。
Pulsar 的存儲于計算是分離的,當需要擴容時會非常簡單,直接新增 broker 即可,沒有其他的心智負擔。
當存儲成為瓶頸時也只需要擴容 BookKeeper,不需要人為的做重平衡,BookKeeper 會自動負載。
同樣的操作,Kafka 就要復雜的多了。
特性
多租戶
多租戶也是一個剛需功能,可以在同一個集群中對不同業務、團隊的數據進行隔離。
- persistent://core/order/create-order
以這個 topic 名稱為例,在 core 這個租戶下有一個 order 的 namespace,最終才是 create-order 的 topic 名稱。
在實際使用中租戶一般是按照業務團隊進行劃分,namespace 則是當前團隊下的不同業務;這樣便可以很清晰的對 topic 進行管理。
通常有對比才會有傷害,在沒有多租戶的消息中間件中是如何處理這類問題的呢:
- 干脆不分這么細,所有業務線混著用,當團隊較小時可能問題不大;一旦業務增加,管理起來會非常麻煩。
- 自己在 topic 之前做一層抽象,但其實本質上也是在實現多租戶。
- 各個業務團隊各自維護自己的集群,這樣當然也能解決問題,但運維復雜度自然也就提高了。
以上就很直觀的看出多租戶的重要性了。
Function 函數計算
Pulsar 還支持輕量級的函數計算,例如需要對某些消息進行數據清洗、轉換,然后再發布到另一個 topic 中。
這類需求就可以編寫一個簡單的函數,Pulsar 提供了 SDK 可以方便的對數據進行處理,最后使用官方工具發布到 broker 中。
在這之前這類簡單的需求可能也需要自己處理流處理引擎。
應用
除此之外的上層應用,比如生產者、消費者這類概念與使用大家都差不多。
比如 Pulsar 支持四種消費模式:
- Exclusive:獨占模式,同時只有一個消費者可以啟動并消費數據;通過 SubscriptionName 標明是同一個消費者),適用范圍較小。
- Failover 故障轉移模式:在獨占模式基礎之上可以同時啟動多個 consumer,一旦一個 consumer 掛掉之后其余的可以快速頂上,但也只有一個 consumer 可以消費;部分場景可用。
- Shared 共享模式:可以有 N 個消費者同時運行,消息按照 round-robin 輪詢投遞到每個 consumer 中;當某個 consumer 宕機沒有 ack 時,該消息將會被投遞給其他消費者。這種消費模式可以提高消費能力,但消息無法做到有序。
- KeyShared 共享模式:基于共享模式;相當于對同一個topic中的消息進行分組,同一分組內的消息只能被同一個消費者有序消費。
第三種共享消費模式應該是使用最多的,當對消息有順序要求時可以使用 KeyShared 模式。
SDK

官方支持的 SDK 非常豐富;我也在官方的 SDK 的基礎之上封裝了一個內部使用的 SDK。
因為我們使用了 dig 這樣的輕量級依賴注入庫,所以使用起來大概是這個樣子:
- SetUpPulsar(lookupURL)
- container := dig.New()
- container.Provide(func() ConsumerConfigInstance {
- return NewConsumer(&pulsar.ConsumerOptions{
- Topic: "persistent://core/order/create-order",
- SubscriptionName: "order-sub",
- Type: pulsar.Shared,
- Name: "consumer01",
- }, ConsumerOrder)
- })
- container.Provide(func() ConsumerConfigInstance {
- return NewConsumer(&pulsar.ConsumerOptions{
- Topic: "persistent://core/order/update-order",
- SubscriptionName: "order-sub",
- Type: pulsar.Shared,
- Name: "consumer02",
- }, ConsumerInvoice)
- })
- container.Invoke(StartConsumer)
其中的兩個 container.Provide() 函數用于注入 consumer 對象。
container.Invoke(StartConsumer) 會從容器中取出所有的 consumer 對象,同時開始消費。
這時以我有限的 Go 開發經驗也在思考一個問題,在 Go 中是否需要依賴注入?
先來看看使用 Dig 這類庫所帶來的好處:
- 對象交由容器管理,很方便的實現單例。
- 當各個對象之前依賴關系復雜時,可以減少許多創建、獲取對象的代碼,依賴關系更清晰。
同樣的壞處也有:
- 跟蹤閱讀代碼時沒有那么直觀,不能一眼看出某個依賴對象是如何創建的。
- 與 Go 所推崇的簡潔之道不符。
對于使用過 Spring 的 Java 開發者來說肯定直呼真香,畢竟還是熟悉的味道;但對于完全沒有接觸過類似需求的 Gopher 來說貌似也不是剛需。
目前市面上各式各樣的 Go 依賴注入庫層出不窮,也不乏許多大廠出品,可見還是很有市場的。
我相信有很多 Gopher 非常反感將 Java 中的一些復雜概念引入到 Go,但我覺得依賴注入本身是不受語言限制,各種語言也都有自己的實現,只是 Java 中的 Spring 不僅僅只是一個依賴注入框架,還有許多復雜功能,讓許多開發者望而生畏。
如果只是依賴注入這個細分需求,實現起來并不復雜,并不會給帶來太多復雜度。如果花時間去看源碼,在理解概念的基礎上很快就能掌握。
回到 SDK 本身來說,Go 的 SDK 現階段要比 Java 版本的功能少(準確來說只有 Java 版的功能最豐富),但核心的都有了,并不影響日常使用。
總結
本文介紹了 Pulsar 的一些基本概念與優點,同時順便討論一下 Go 的依賴注入;如果大家和我們一樣在做技術選型,不妨考慮一下 Pulsar。













