記一次線上Java程序故障驚心動魄兩小時
周日早上醒來,明媚的陽光從臥室的窗戶直射進來,久違的好天氣。穿好衣服我開始籌劃今天去哪里轉轉。一周忙碌的工作幾乎沒有時間陪家人,今天該好好陪陪家人了。
當我起來收拾好一切準備出發的時候,我瞄了一眼手機,發現手機的郵箱里有一份報警郵件,報警郵件顯示線上最近10分鐘流量有異常,而且是多個渠道。有突然有一種不祥的預感:線上kafka出問題了。我讓媳婦和孩子下樓在車里等我,我趕緊打開了電腦,查看線上系統。果然不出意外,kafka已經積壓了幾千萬的數據。因為我們的業務分為實時數據和離線數據,實時數據是FileBeat負責收集日志發到Kafka,然后我們這個業務系統消費Kafka統計數據,實時數據對于當前流量分析、預算控制、熔斷有非常重要的作用,如果實時數據異常,其它業務系統都會受到一定的影響。
定位到報警郵件是由于kafka消息積壓而導致實時數據異常觸發的,我立馬連上了我們消費Kafka的業務系統(data-collect)。這是一個運行時間很長了的Java服務,它的作用就是實時消費kafka數據,然后經過一定的業務邏輯處理,將最終結果更新到mongodb中。進到服務器以后,我發現這個服務已經處于假死狀態,最后一條日志顯示系統發生了OOM,也就是服務器內存爆了。
關于data-collect這個Java服務的核心邏輯我在這里詳細說明一下。這個系統的代碼是很早的一位同事寫的,因為早期我們的數據體量還不是很大,所以,他采用了一種簡單的處理方式。先消費數據,處理完成以后放到一個Map中,然后,啟動了一個每10s執行一次的定時任務,定時任務讀取Map數據更新到mongo中,然后清空Map(ConcurrentMap)。這樣做的優點是將消費Kafka的操作和入庫操作分開了,可以防止因為入庫時間太長而導致消費速度變慢,但是,這種做法有一個致命的缺點:內存不可控。如果定時任務因為Mongo操作時間太長而沒有及時清空Map,Map中會積累大量的數據,最終耗盡內存,系統發生OOM。這時候如果系統自啟了,也會丟失大量的數據。
其實,這個問題我很早有意識到,但是系統一直運行良好,沒有出現任何問題,我們認為在現有數據體量下它是安全的。而碰巧的是,就在前一天我們升級了Mongo的配置,mongo機器進行了一個主從切換。同時,有一些大表清理和TTL索引重建的工作還在mongo后臺運行。這就導致了我們操作mongo耗時的增加。進而導致了我們一直認為安全的系統出現了這個問題。
回到data-collect這個系統的設計上。可能有的同學會在這里有個疑問,為什么不直接消費出來就入庫操作呢?這里我們有一個重要的處理邏輯:為了防止頻繁的更新mongo,我們會將消費出來的數據在內存中進行一個合并處理,你可以簡單的理解為一個Map,如果key存在,我們就進行++的操作。最終操作mongo是$inc的操作,不是insert和update的操作。這也是我們需要一個ConcurrentMap的原因。也就是我們大概消費了1000萬條數據,但是最終我們處理完成以后只有10萬條數據,很多key相同的數據我們都進行了合并處理,這樣我們mongo的操作就減少了很多。
data-collect發生了OOM,我只能第一時間重啟,重啟以后,消費正常,系統開始有了數據。但是大概運行了幾分鐘以后,又發生了OOM。原因很簡單:kafka積壓的了大量的消息,消費很快,但是異步如mongo太耗時,所以導致數據全部擠壓在了這個Map內存中。看到這里,我想只能動手改造代碼了。改造的最終要達到的結果是:系統在不發生OOM的前提下,消費積壓在kafka中的數據,完成mongo操作。
改造的思路很簡單,就是干掉定時任務。在消費kafka消息中增加一個邏輯,每當消費消息并且內存進行數據合并完成以后,我們判斷Map的大小,如果Map的大小超過我們設定的限制以后,開始觸發mongo操作。之前的代碼mongo操作是單線程執行,為了提升mongo插入操作,我們開啟20個線程并行執行,所以我們這里需要一個帶阻塞隊列的線程池。改造后的代碼如下:
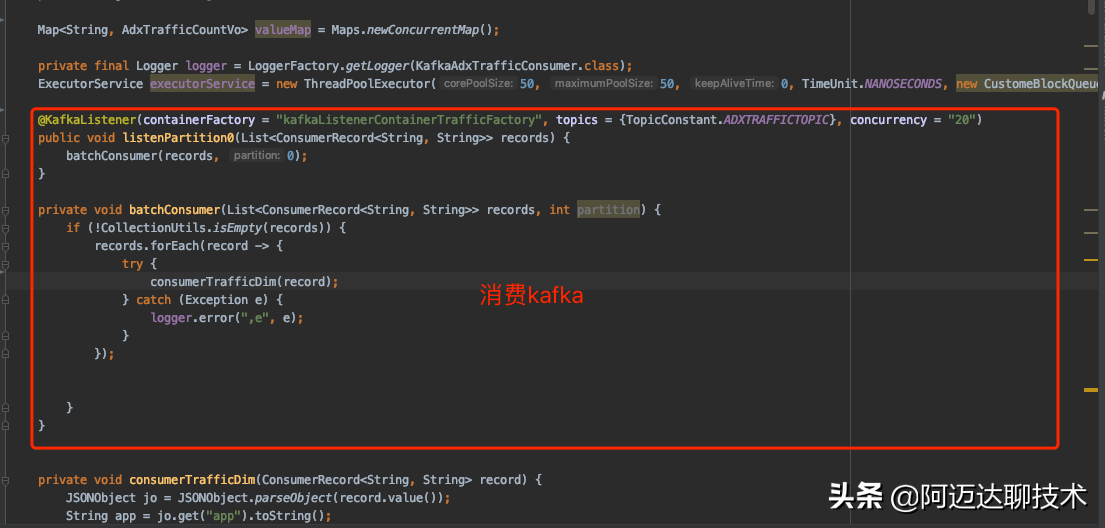
這里是SpringBoot集成Kafka的消費代碼。
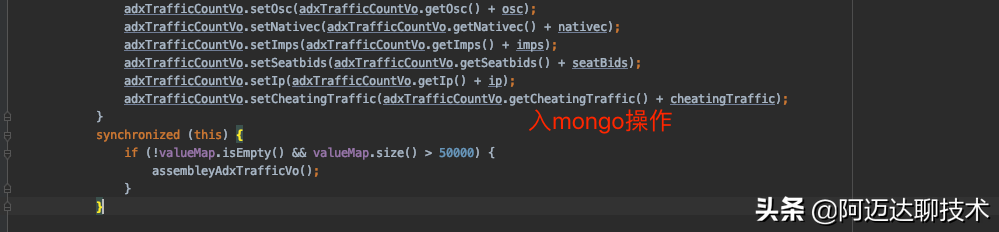
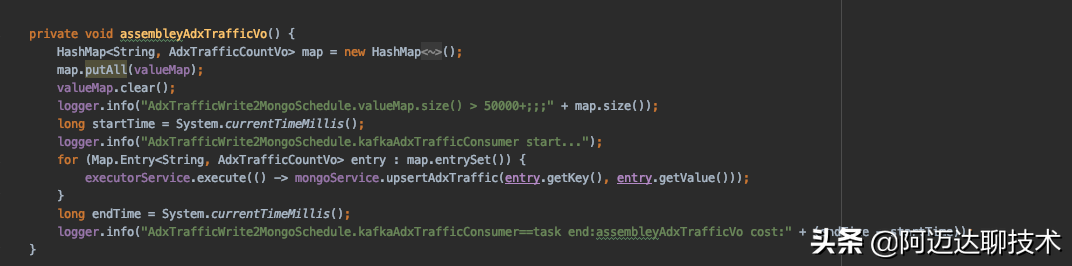
這是內存處理完成以后入mongo的操作。因為我們的topic有20個分區,所以代碼中的listenPartition0是多線程執行的。如果沒有synchronized的同步代碼塊,那assembleyAdxTrafficVo方法就會多線程執行,這就會導致數據重復插入mongo,具體大家可以體會assembleyAdxTrafficVo方法的邏輯。
而插入mongo操作的用了線程池ExecutorService,注意這里我們executorService對象的定義。

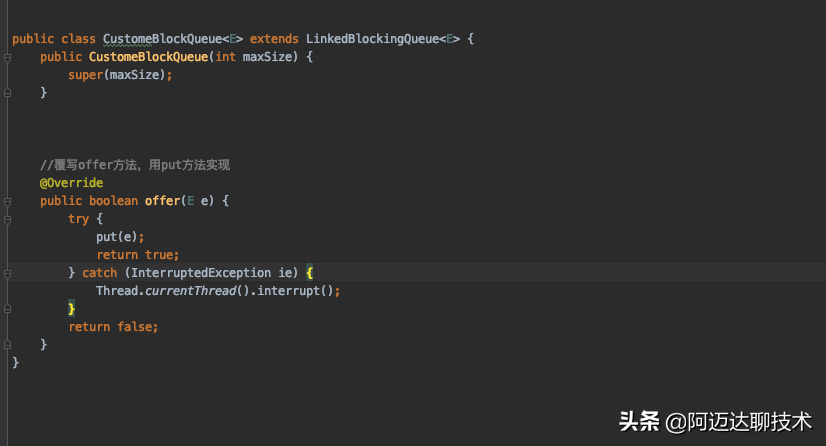
為什么要自己定義一個阻塞隊列CustomeBlockQueue?這相比很多人碰到過這個問題,如果采用默認的阻塞隊列,例如:ArrayBlockingQueue,當隊列長度長度超過設置的值時,ArrayBlockingQueue會拒絕新的數據進入,并且拋出異常,所以我們需要自己定義CustomeBlockQueue,并且重寫他的offer方法(BlockingQueue默認采用offer方法將元素增加到隊列),offer方法不會阻塞,put方法會阻塞,所以我們需要重寫offer方法,并且內部采用put方法實現。關于這一點,大家可以多嘗試。ArrayBlockingQueue和LinkedBlockingQueue都有很多坑等大家去踩。
按照上述代碼處理完成上線以后,系統開始正常運行,kafka積壓的消息也開始慢慢降低,系統趨于恢復正常,而這時已經是12點了,驚心動魄的2小時總算過去了,阿彌陀佛。