記一次集合去重導致的線上問題
前言
在工作中一次排查慢接口時,查到了一個函數耗時較長,最終定位到是通過 List 去重導致的。
由于測試環境還有線上早期數據較少,這個接口的性能問題沒有引起較大關注,后面頻繁超時,才引起重視。
之前看《阿里巴巴Java開發手冊》里面有這樣一段描述:

你看,阿里前輩們都免費總結了,不過還是會看到有人會用List的contains函數來去重......
不記得的,罰抄10萬遍
如果需要這本書資源的網上下載也行,私聊我發你也行
今天我就結合源碼聊聊Set是怎樣保證數據的唯一性的,為什么兩種去重方式性能差距這么大
HashSet源碼
先看看類注釋:
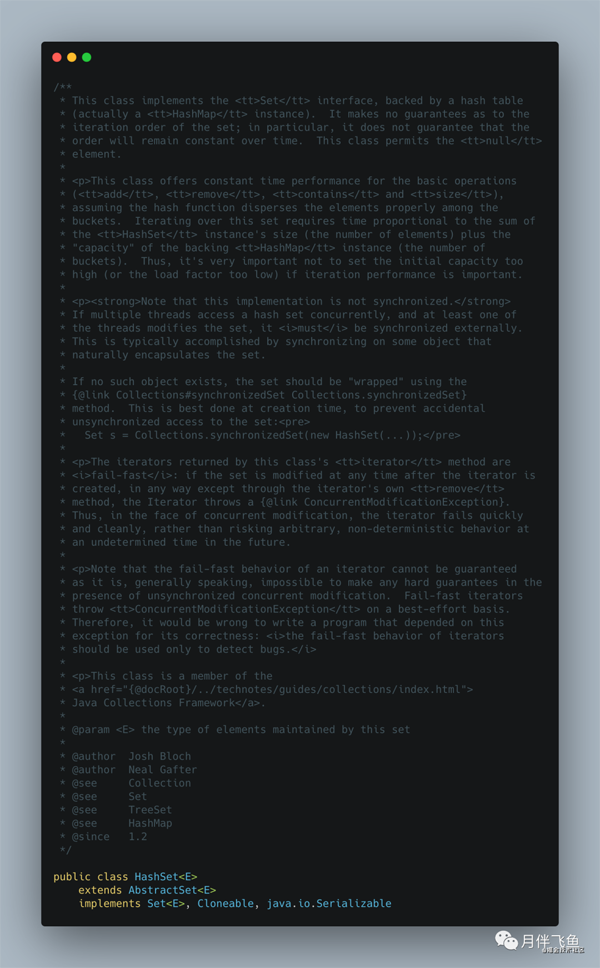
看類注釋上,我們可以得到的信息有:
- 底層實現基于 HashMap,所以迭代時不能保證按照插入順序,或者其它順序進行迭代;
- add、remove、contanins、size 等方法的耗時性能,是不會隨著數據量的增加而增加的,這個主要跟 HashMap 底層的數組數據結構有關,不管數據量多大,不考慮 hash 沖突的情況下,時間復雜度都是 O (1);
- 線程不安全的,如果需要安全請自行加鎖,或者使用 Collections.synchronizedSet;
- 迭代過程中,如果數據結構被改變,會快速失敗的,會拋出 ConcurrentModificationException 異常。
剛才是從類注釋中看到,HashSet 的實現是基于 HashMap 的,在 Java 中,要基于基礎類進行創新實現,有兩種辦法:
- 繼承基礎類,覆寫基礎類的方法,比如說繼承 HashMap , 覆寫其 add 的方法;
- 組合基礎類,通過調用基礎類的方法,來復用基礎類的能力。
HashSet 使用的就是組合 HashMap,其優點如下:
繼承表示父子類是同一個事物,而 Set 和 Map 本來就是想表達兩種事物,所以繼承不妥,而且 Java 語法限制,子類只能繼承一個父類,后續難以擴展。
組合更加靈活,可以任意的組合現有的基礎類,并且可以在基礎類方法的基礎上進行擴展、編排等,而且方法命名可以任意命名,無需和基礎類的方法名稱保持一致。
組合就是把 HashMap 當作自己的一個局部變量,以下是 HashSet 的組合實現:
- // 把 HashMap 組合進來,key 是 Hashset 的 key,value 是下面的 PRESENT
- private transient HashMap<E,Object> map;
- // HashMap 中的 value
- private static final Object PRESENT = new Object();
從這兩行代碼中,我們可以看出兩點:
我們在使用 HashSet 時,比如 add 方法,只有一個入參,但組合的 Map 的 add 方法卻有 key,value 兩個入參,相對應上 Map 的 key 就是我們 add 的入參,value 就是第二行代碼中的 PRESENT,此處設計非常巧妙,用一個默認值 PRESENT 來代替 Map 的 Value;
我們再來看看add方法:
- public boolean add(E e) {
- // 直接使用 HashMap 的 put 方法,進行一些簡單的邏輯判斷
- return map.put(e, PRESENT)==null;
- }
我們進入更底層源碼java.util.HashMap#put:
- public V put(K key, V value) {
- return putVal(hash(key), key, value, false, true);
- }
再瞧瞧hash方法:
- static final int hash(Object key) {
- int h;
- return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
- }
可以看到如果 key 為 null ,哈希值為 0,否則將 key 通過自身hashCode函數計算的的哈希值和其右移 16 位進行異或運算得到最終的哈希值。
我們再回到 java.util.HashMap#putVal中:
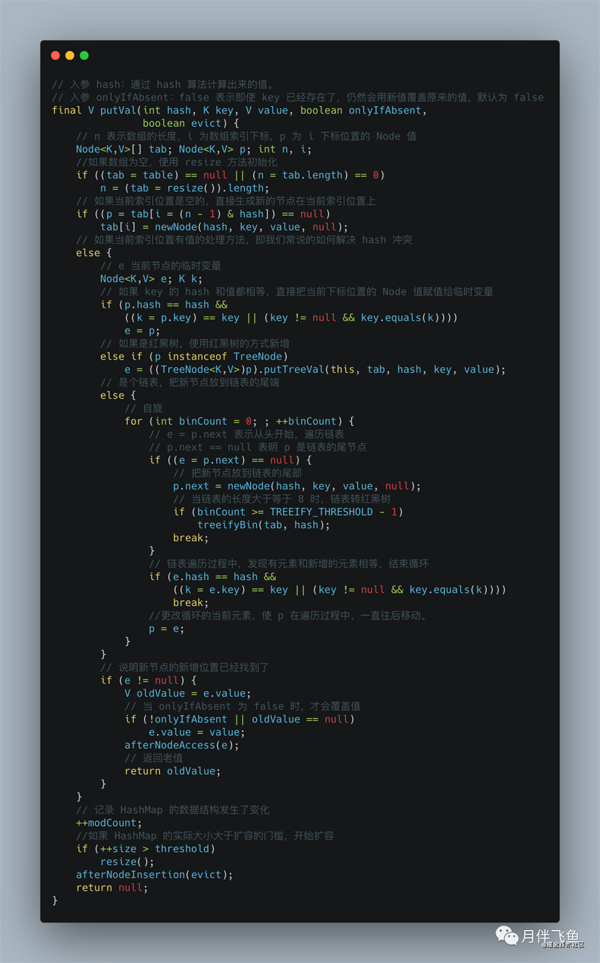
在 java.util.HashMap#putVal中,直接通過 (n - 1) & hash 來得到當前元素在節點數組中的位 置。如果不存在,直接構造新節點并存儲到該節點數組的對應位置。如果存在,則通過下面邏 輯:
- p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))
來判斷元素是否相等。
如果相等則用新值替換舊值,否則添加紅黑樹節點或者鏈表節點。
總結:通過HashMap的key的唯一性來保證的HashSet元素的唯一性。
最后再看看:
《阿里巴巴Java開發手冊》里面還有這樣一段描述:

到現在是不是明白了,這個2,3點的原因
性能對比
其實HashSet和ArrayList去重性能差異的核心在于contains函數性能對比。
我們分別查看java.util.HashSet#contains和java.util.ArrayList#contains的實現。
java.util.HashSet#contains源碼:
- public boolean contains(Object o) {
- return map.containsKey(o);
- }
最終也是通過HashMap判斷的
如果 hash 沖突不是極其嚴重(大多數都沒怎么有哈希沖突),n 個元素依次判斷并插入到 Set 的時間復雜度接近于 O (n),查找的復雜度是O(1)。
接下來我們看java.util.ArrayList#contains的源碼:
- public boolean contains(Object o) {
- return indexOf(o) >= 0;
- }
- public int indexOf(Object o) {
- if (o == null) {
- for (int i = 0; i < size; i++)
- if (elementData[i]==null)
- return i;
- } else {
- for (int i = 0; i < size; i++)
- if (o.equals(elementData[i]))
- return i;
- }
- return -1;
- }
發現其核心邏輯為:如果為 null, 則遍歷整個集合判斷是否有 null 元素;否則遍歷整個列表,通 過 o.equals(當前遍歷到的元素) 判斷與當前元素是否相等,相等則返回當前循環的索引。
所以, java.util.ArrayList#contains判斷并插入n個元素到 Set 的時間復雜度接近于O (n^2),查找的復雜度是O(n)。
因此,通過時間復雜度的比較,性能差距就不言而喻了。
我們分別將兩個時間復雜度函數進行作圖, 兩者增速對比非常明顯:
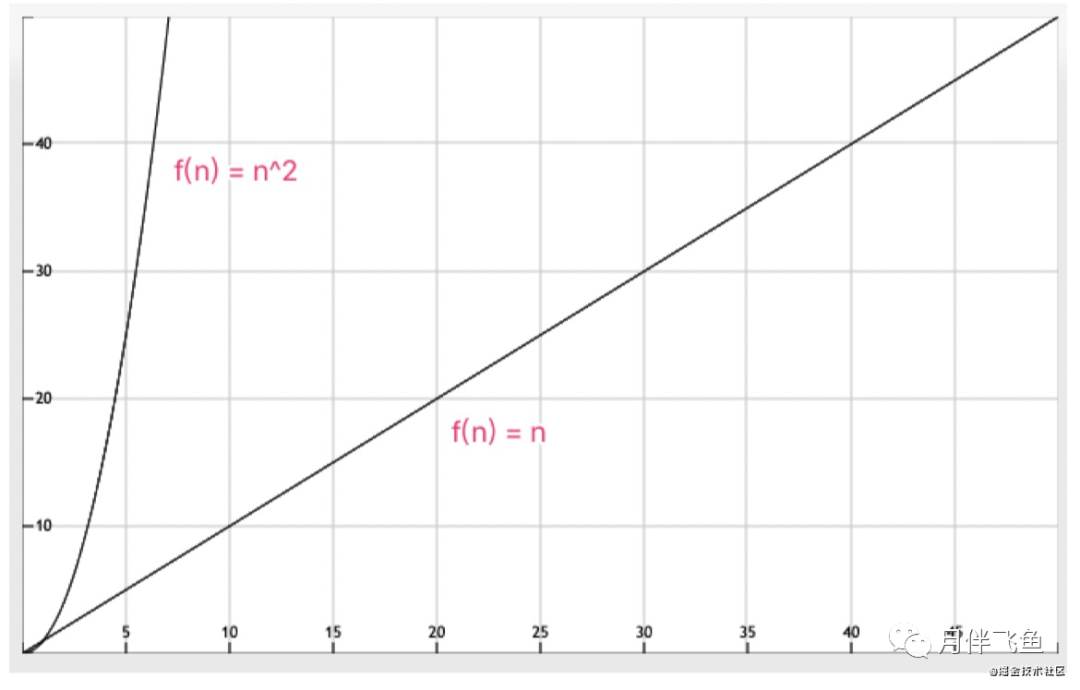
如果數據量不大時采用 List 去重勉強可以接受,但是數據量增大后,接口響應時間會超慢,這 是難以忍受的,甚至造成大量線程阻塞引發故障。
本文轉載自微信公眾號「 月伴飛魚」,可以通過以下二維碼關注。轉載本文請聯系 月伴飛魚公眾號。