Google開源ToTTo數據集,你的模型還「撐」得住嗎?

近日,Google研究人員提出一個大型從表轉換到文本的英文數據集,已經在Git上開源。該數據集不僅提供了一個可以受控的句子生成任務,還提供了一個基于迭代語句修訂的數據注釋過程。實驗結果證明,ToTTo可以作為有用且高效的數據集,用來幫助其他研究者建模研究,以及開發可以更好地檢測模型改進的評估指標。
在過去的幾年里,自然語言生成(用于文本摘要等任務)的研究取得了巨大的進展。
然而,盡管達到了高水平的流暢性,神經系統仍然容易產生「幻覺」(即產生的文本盡管可以被理解,但是含義并不忠實于源文本),這使得這些系統不能用于許多需要高準確性的應用。
我們可以舉例說明這個問題:
這是一個來自Wikibio數據集的例子,其中,負責總結比利時足球運動員Constant Vanden Stock的維基信息框條目的神經基線模型,在經過分析之后,錯誤地得出了他是一個美國花樣滑冰運動員的結論,如下圖:

雖然評估生成的文本與源內容的真實性相比,可能會具有一定的不一致。
但當源內容是結構化的(例如,以表格格式)時,在含義上保持一致往往會更容易。
此外,結構化數據還可以測試模型的推理和數值推理能力。
這么聽上去,結構化數據是蠻好的,對不對?
然而,現有的大規模結構化數據集往往有噪聲(即引用的句子不能從表格數據中完全推斷出來),這使得研究人員在模型開發中對「幻覺」的測量并不可靠。
針對這一問題,Google的研究人員提出了他們的解決方案:
在《ToTTo:一個受控的表到文本生成數據集》(ToTTo: A Controlled Table-to-Text Generation Dataset)中,研究人員提出了一個開放域的表到文本生成數據集。

該數據集是由一種新的注釋過程(通過句子修改)以及一個可用于評估模型「幻覺」的受控文本生成任務生成的。
在接下來的介紹中,我們將「表到文本」稱為ToTTo。
ToTTo包含121,000個訓練示例,以及7,500個用于開發和測試的示例。
由于標注的準確性,該數據集適合作為研究高精度文本生成的具有挑戰性的benchmark。
此外,數據集和代碼已經在Google的GitHub repo上開源:
Git地址:https://github.com/google-research-datasets/totto
論文地址:https://arxiv.org/pdf/2004.14373.pdf
引入受控任務,維基百科表成輸入來源
ToTTo引入了一個受控的生成任務——
在該任務中,源材料是帶有一組選定單元格的給定維基百科表,而生成的則是一個總結表上下文中單元格內容的單句描述。
下圖中的示例,展示了該任務中包含的一些挑戰,例如數值推理、大量的開放域詞匯表和多種表結構等等:
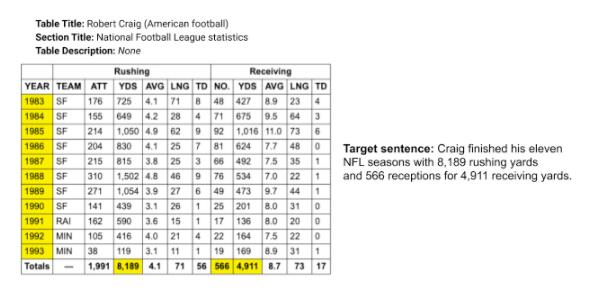
在ToTTo數據集中,輸入是源表和高亮顯示的單元格集(上圖左側),而目標是生成一個句子描述,例如“Target Sentence”(上圖右側)。
在這里需要注意的是,生成目標句子需要數值推理能力和對NFL領域的理解。
注釋器可實現分階段修訂,目標句簡潔自然有趣
接下來,研究人員要設計一個注釋過程,這個注釋過程可以使得從表格數據中獲得語法自然又干凈簡潔的目標句子,而這,無疑是一個重大的挑戰。
為什么呢?
一個方面來說,許多像Wikibio和RotoWire這樣的數據集,會將自然產生的文本啟發式地與表配對,然而,這是一個「嘈雜」的過程,因為在這個過程中,我們很難弄清楚「幻覺」主要是由數據噪聲還是模型缺陷引起的。
從另一方面來說,研究者確實可以讓注釋器從頭開始編寫忠于表的目標句子,但是不好的一點是,最終的目標句子在結構和風格方面往往缺乏多樣性。
相比之下,ToTTo是使用一種新的數據注釋策略構建的——
在這個方法下,注釋器可以分階段修改現有的維基百科句子。
如此以來,目標句可以具有簡潔干凈、自然的特點,并且還能包含有趣和多樣的語言特性。
具體過程是這樣的:
數據收集和注釋過程會從Wikipedia收集表開始,其中「給定表」會與根據啟發式從支持頁面上下文收集的「摘要句」配對。
這個摘要句可能包含沒有表格支持的信息,也可能包含只有表格中有先行詞的代詞,而不是句子本身。
然后,注釋器突出顯示表中支持該句子的單元格,并刪除表不支持的句子中的短語。
此外,注釋器還將句子去語境化,使其獨立成文(例如,在必要的時候使用正確的代詞),具有正確的語法。

實驗結果表明,注釋器對上述任務的一致性很高:
單元格高亮顯示的Fleiss Kappa為0.856,最終目標句子的BLEU為67.0。
結果分析涉及話題極其廣泛,「體育和國家」占比最大
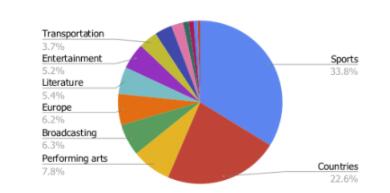
Google的研究人員對ToTTo數據集進行了超過44個類別的主題分析,例如體育和國家主題。
每個主題都包含一系列細粒度的主題,例如體育的足球/奧林匹克和國家的人口/建筑,這些共占數據集的56.4%。
另外44%的話題范圍更廣,包括表演藝術、交通和娛樂。
此外,研究人員對隨機選取的100多個實例數據集中的不同類型的語言現象進行了人工分析。
下表總結了需要參考頁面和章節標題的部分例子,以及數據集中可能對當前系統構成新挑戰的一些語言現象:

全新角度測試諸多先進模型,BERT-to-BERT最能還原原文含義
研究人員從文獻中提供了三個最先進模型(BERT-to-BERT、指針生成器和Puduppully 2019模型),使用了兩個評估指標,即BLEU和PARENT。
除了報告整個測試集的分數外,研究人員還在一個由域外示例組成的更具挑戰性的子集上評估了每個模型。
實驗結果如下表所示:
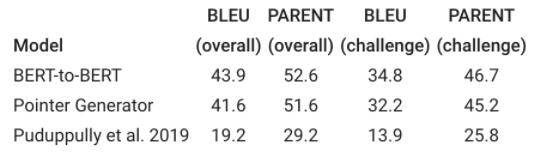
我們可以發現,BERT-to-BERT模型在「親近原文本」方面表現最好。
此外,所有模型在挑戰集上的性能都相當低,這表明了域外泛化任務還是具有很強的挑戰性。
雖然自動指標可以提供一些性能信息,但目前還不足以評估文本生成系統中的「幻覺」現象。
為了更好地理解「幻覺」,研究人員假設差異表明「幻覺」,并手動評估了最高表現基線,以確定目的句子對源表內容的忠實程度。
結果顯示,最高表現基線下,出現「幻覺」信息的概率為20%。

當前最新模型仍有諸多不足,文本生成「路漫漫其修遠兮」
在下表中,研究人員選擇了觀察到的模型錯誤,以突出顯示ToTTo數據集的面臨的一些更有挑戰性的問題:

研究人員發現,即使使用「干凈」的引用參考內容,最先進的模型也會與「幻覺」、「數值推理」和「罕見的主題」等問題「糾纏不清」(在上圖中,錯誤用紅色表明)。、
而最后一個例子表明,即使模型輸出是正確的,它有時也沒有原始引用提供的信息豐富——
原始引用包含了更多關于表的推理(在上圖中,用藍色顯示)。
最后,除了提出的任務,研究人員還表示,希望ToTTo也可以幫助其他任務,如表格的理解和句子的修改。