謹(jǐn)慎使用!從入門到精通,一文帶你學(xué)會(huì)Python面向監(jiān)獄爬蟲

網(wǎng)絡(luò)爬蟲簡(jiǎn)單來(lái)說(shuō),就是從網(wǎng)絡(luò)中批量獲取自己想要的數(shù)據(jù)。
網(wǎng)上爬取數(shù)據(jù)有兩種方法可以實(shí)現(xiàn):
- 使用官方 API
- 網(wǎng)絡(luò)抓取
API (應(yīng)用程序接口)是為了以標(biāo)準(zhǔn)的方式在不同的系統(tǒng)之間交換數(shù)據(jù)。但是,大多數(shù)時(shí)候,網(wǎng)站所有者并不提供任何 API。在這種情況下,我們只能使用 web 抓取提取數(shù)據(jù)了。
基本上,每個(gè) web 頁(yè)面都以 HTML 格式從服務(wù)器返回,這意味著我們的實(shí)際數(shù)據(jù)被很好地包裝在 HTML 元素中。這使得檢索特定數(shù)據(jù)的整個(gè)過(guò)程非常簡(jiǎn)單和直接。
本教程將是一個(gè)自始至終的指南,讓你可以盡可能簡(jiǎn)單的使用 Python學(xué)習(xí)爬蟲。首先,我將向你介紹一些基本的示例,讓你熟悉 web 抓取。稍后,我們將使用這些知識(shí)從 Livescore.cz 中提取足球比賽的數(shù)據(jù)。
開始
為了讓我們開始,你需要啟動(dòng)一個(gè)新的 Python3 項(xiàng)目,并安裝 Scrapy (一個(gè)用于 Python 的 web 爬蟲庫(kù))。我在本教程中使用了 pipenv,但是你也可以使用 pip 和 venv,或 conda。
- pipenv install scrapy # Pipenv 安裝 scrap
現(xiàn)在,你已經(jīng)有了 Scrapy,但是你仍然需要?jiǎng)?chuàng)建一個(gè)新的 web 抓取項(xiàng)目,為此 Scrapy 提供了一個(gè)命令行,可以為我們完成這項(xiàng)工作。
現(xiàn)在,讓我們使用 scrapy clii 創(chuàng)建一個(gè)名為 web _ scraper 的新項(xiàng)目。
如果你像我一樣使用 pipenv,請(qǐng)使用:
- pipenv run scrapy startproject web_scraper
或者在你自己的虛擬環(huán)境中,使用:
- scrapy startproject web_scraper
這將在工作目錄中創(chuàng)建一個(gè)基本項(xiàng)目,其結(jié)構(gòu)如下:

01. 使用 XPath
我們將從一個(gè)非常簡(jiǎn)單的例子開始我們的網(wǎng)絡(luò)抓取教程。首先,我們將在 HTML 中定位 Live Code Stream 網(wǎng)站的標(biāo)志。正如我們所知,它只是一個(gè)文本,而不是一個(gè)圖像,所以我們將簡(jiǎn)單地提取這個(gè)文本。
代碼
為了開始,我們需要為這個(gè)項(xiàng)目創(chuàng)建一個(gè)新的爬取器。我們可以通過(guò)創(chuàng)建一個(gè)新文件或使用 CLI 來(lái)實(shí)現(xiàn)這一點(diǎn)。
因?yàn)槲覀円呀?jīng)知道我們需要的代碼,所以我們將在這個(gè)路徑 /web_scraper/spiders/live _ code _ stream. py 上創(chuàng)建一個(gè)新的 Python 文件
下面是這個(gè)文件中的代碼。

代碼解釋
- 首先,我們導(dǎo)入了 Scrapy 庫(kù),因?yàn)槲覀冃枰墓δ軄?lái)創(chuàng)建一個(gè)Python web spider。這個(gè)爬蟲隨后將用于抓取指定的網(wǎng)站和提取有用的信息。
- 我們創(chuàng)建了一個(gè)類,并將其命名為L(zhǎng)iveCodeStreamSpider。基本上,它繼承了 scrapy。這就是為什么我們把它作為一個(gè)參數(shù)來(lái)傳遞。
- 現(xiàn)在,重要的一步是使用一個(gè)名為 name 的變量為你的 spider 定義一個(gè)唯一的名稱。請(qǐng)記住,不允許使用現(xiàn)有 spider 的名稱。同樣,不能使用此名稱創(chuàng)建新的爬行器。它必須在整個(gè)項(xiàng)目中是獨(dú)一無(wú)二的。
- 之后,我們使用 start_urls list 傳遞網(wǎng)站 URL 。
- parse() 的方法,該方法將在 HTML 代碼中定位標(biāo)記并提取其文本。在 Scrapy,有兩種方法可以在源代碼中找到 HTML 元素。這些都在下面提到:
CSS 和 XPath
你甚至可以使用一些外部庫(kù),比如 BeautifulSoup 和 lxml。但是,對(duì)于這個(gè)例子,我們使用了 XPath。
一個(gè)快速確定任何 HTML 元素的 XPath 的方法是在 Chrome Devtools 中打開它。現(xiàn)在,只需右鍵單擊該元素的 HTML 代碼,將鼠標(biāo)光標(biāo)懸停在剛剛出現(xiàn)的彈出菜單中的“復(fù)制”上。最后,單擊“ Copy XPath”菜單項(xiàng)。
請(qǐng)看下面的截圖,以便更好地理解它。
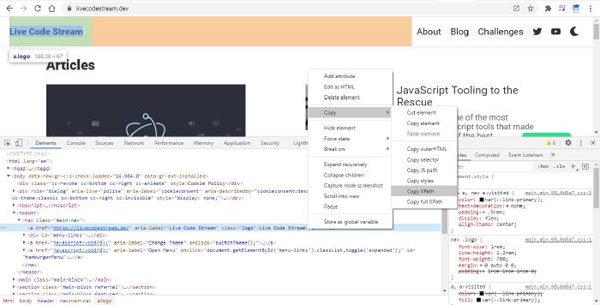
順便說(shuō)一下,我在元素的實(shí)際 XPath 之后使用了/text () ,只從該元素中檢索文本,而不是從完整的元素代碼中檢索。
注意:不可對(duì)上面提到的變量、列表或函數(shù)使用任何其他名稱。這些名稱是在 Scrapy 圖書館預(yù)先定義的。因此,你必須實(shí)事求是地使用它們。否則,程序?qū)o(wú)法正常工作。
運(yùn)行爬蟲
因?yàn)槲覀円呀?jīng)在命令提示符下的 web_scraper 文件夾中了。讓我們執(zhí)行 spider 并使用下面的代碼在新文件 lcs.json 中填充結(jié)果。我們得到的結(jié)果將使用 JSON 格式進(jìn)行良好的結(jié)構(gòu)化。
- pipenv run scrapy crawl lcs -o lcs.json scrapy crawl lcs -o lcs.json
結(jié)果
當(dāng)執(zhí)行上面的代碼時(shí),我們會(huì)在項(xiàng)目文件夾中看到一個(gè)新的文件 lcs.json。
下面是這個(gè)文件的內(nèi)容。
- [ {"logo": "Live Code Stream"} ]
02. 使用 CSS
我們大多數(shù)人都喜歡體育運(yùn)動(dòng),比如足球。
世界各地經(jīng)常組織足球比賽。有幾個(gè)網(wǎng)站在比賽進(jìn)行時(shí)提供比賽結(jié)果的實(shí)時(shí)反饋。但是,大多數(shù)這些網(wǎng)站并沒有提供任何官方的 API。
反過(guò)來(lái),它為我們創(chuàng)造了一個(gè)機(jī)會(huì),使用我們的網(wǎng)絡(luò)抓取技能和提取有意義的信息,直接抓取他們的網(wǎng)站。
在他們的主頁(yè)上,他們很好地展示了今天(你訪問(wèn)網(wǎng)站的日期)將要進(jìn)行的比賽和比賽。
我們可以檢索如下信息
- 比賽名稱
- 比賽時(shí)間
- A隊(duì)隊(duì)名
- A隊(duì)進(jìn)球數(shù)
- B隊(duì)隊(duì)名
- B隊(duì)進(jìn)球數(shù)
- etc. 等等
在我們的代碼示例中,我們將提取今天有匹配的比賽名稱。
代碼
讓我們?cè)陧?xiàng)目中創(chuàng)建一個(gè)新的 spider 來(lái)檢索比賽名稱,我將項(xiàng)目命名為livescore_t.py
下面是你在 livescore _ t.py 中需要輸入的代碼:

代碼解釋
- 像往常一樣,導(dǎo)入 Scrapy
- 創(chuàng)建一個(gè)類,該類繼承 scrapy.Spider
- 給我們的爬蟲取一個(gè)獨(dú)一無(wú)二的名字 LiveScoreT
- 提供 livescore.cz 的URL
最后,用 parse() 函數(shù)遍歷所有匹配的包含競(jìng)賽名稱的元素,并使用 yield 將其連接在一起。最后,我們會(huì)收到今天有比賽的所有比賽名稱。需要注意的一點(diǎn)是,這次我使用了 CSS 而不是XPath。
運(yùn)行
是時(shí)候看看我們的爬蟲是如何行動(dòng)的了。運(yùn)行下面的命令讓 spider 到達(dá) Livescore.cz 網(wǎng)站的主頁(yè)。然后,web 抓取結(jié)果將被添加到一個(gè)名為 ls _ t.json 的新文件中。
- pipenv run scrapy crawl LiveScoreT -o ls_t.json
結(jié)果
這是我們的網(wǎng)絡(luò)爬蟲在2020年11月18日從 Livescore.cz 中提取的內(nèi)容。記住,輸出可能每天都在變化。

03. 一個(gè)更高級(jí)的例子
在本節(jié)中,我們將不僅僅是檢索錦標(biāo)賽名稱,而是進(jìn)入下一個(gè)階段,獲取錦標(biāo)賽及其比賽的完整細(xì)節(jié)。
在 /web _ scraper/web _ scraper/spider/ 中創(chuàng)建一個(gè)新文件,并將其命名為 livescore.py。

代碼解釋
此文件的代碼結(jié)構(gòu)與前面的示例相同。在這里,我們只是用一個(gè)新的功能更新了 parse () 方法。
基本上,我們從頁(yè)面中提取了所有的 HTML <tr> </tr> 元素。然后,我們通過(guò)循環(huán)找出這是一個(gè)錦標(biāo)賽或比賽。如果它是一個(gè)錦標(biāo)賽,我們提取它的名字。在比賽的情況下,我們提取了它的“時(shí)間”、“狀態(tài)”和“兩支球隊(duì)的名稱和得分”
運(yùn)行
在控制臺(tái)鍵入以下命令并執(zhí)行它
- pipenv run scrapy crawl LiveScore -o ls.json
結(jié)果
下面是已經(jīng)檢索到的一些樣本:

現(xiàn)在有了這些數(shù)據(jù),我們可以做任何我們想做的事情,比如用它來(lái)訓(xùn)練我們自己的神經(jīng)網(wǎng)絡(luò)來(lái)預(yù)測(cè)未來(lái)的游戲。
04. 總結(jié)
數(shù)據(jù)分析師經(jīng)常使用網(wǎng)絡(luò)抓取,因?yàn)樗梢詭椭麄兪占瘮?shù)據(jù)來(lái)預(yù)測(cè)未來(lái)。類似地,企業(yè)使用它從網(wǎng)頁(yè)中提取電子郵件,因?yàn)檫@是一種有效的方式產(chǎn)生領(lǐng)導(dǎo)。我們甚至可以用它來(lái)監(jiān)控產(chǎn)品的價(jià)格。
換句話說(shuō),web 抓取有許多用例,Python完全有能力做到這一點(diǎn)。
那么,你還在等什么呢? 現(xiàn)在就試著抓取你最喜歡的網(wǎng)站吧。