八張圖搞懂 Flink 端到端精準一次處理語義 Exactly-once
本文轉載自微信公眾號「五分鐘學大數據」,作者園陌 。轉載本文請聯系五分鐘學大數據公眾號。
Flink
在 Flink 中需要端到端精準一次處理的位置有三個:
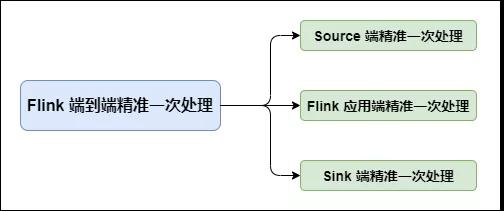
Flink 端到端精準一次處理
- Source 端:數據從上一階段進入到 Flink 時,需要保證消息精準一次消費。
- Flink 內部端:這個我們已經了解,利用 Checkpoint 機制,把狀態存盤,發生故障的時候可以恢復,保證內部的狀態一致性。不了解的小伙伴可以看下我之前的文章:
- Flink可靠性的基石-checkpoint機制詳細解析
Sink 端:將處理完的數據發送到下一階段時,需要保證數據能夠準確無誤發送到下一階段。
在 Flink 1.4 版本之前,精準一次處理只限于 Flink 應用內,也就是所有的 Operator 完全由 Flink 狀態保存并管理的才能實現精確一次處理。但 Flink 處理完數據后大多需要將結果發送到外部系統,比如 Sink 到 Kafka 中,這個過程中 Flink 并不保證精準一次處理。
在 Flink 1.4 版本正式引入了一個里程碑式的功能:兩階段提交 Sink,即 TwoPhaseCommitSinkFunction 函數。該 SinkFunction 提取并封裝了兩階段提交協議中的公共邏輯,自此 Flink 搭配特定 Source 和 Sink(如 Kafka 0.11 版)實現精確一次處理語義(英文簡稱:EOS,即 Exactly-Once Semantics)。
端到端精準一次處理語義(EOS)
以下內容適用于 Flink 1.4 及之后版本
對于 Source 端:Source 端的精準一次處理比較簡單,畢竟數據是落到 Flink 中,所以 Flink 只需要保存消費數據的偏移量即可, 如消費 Kafka 中的數據,Flink 將 Kafka Consumer 作為 Source,可以將偏移量保存下來,如果后續任務出現了故障,恢復的時候可以由連接器重置偏移量,重新消費數據,保證一致性。
對于 Sink 端:Sink 端是最復雜的,因為數據是落地到其他系統上的,數據一旦離開 Flink 之后,Flink 就監控不到這些數據了,所以精準一次處理語義必須也要應用于 Flink 寫入數據的外部系統,故這些外部系統必須提供一種手段允許提交或回滾這些寫入操作,同時還要保證與 Flink Checkpoint 能夠協調使用(Kafka 0.11 版本已經實現精確一次處理語義)。
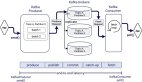
我們以 Flink 與 Kafka 組合為例,Flink 從 Kafka 中讀數據,處理完的數據在寫入 Kafka 中。
為什么以Kafka為例,第一個原因是目前大多數的 Flink 系統讀寫數據都是與 Kafka 系統進行的。第二個原因,也是最重要的原因 Kafka 0.11 版本正式發布了對于事務的支持,這是與Kafka交互的Flink應用要實現端到端精準一次語義的必要條件。
當然,Flink 支持這種精準一次處理語義并不只是限于與 Kafka 的結合,可以使用任何 Source/Sink,只要它們提供了必要的協調機制。
Flink 與 Kafka 組合
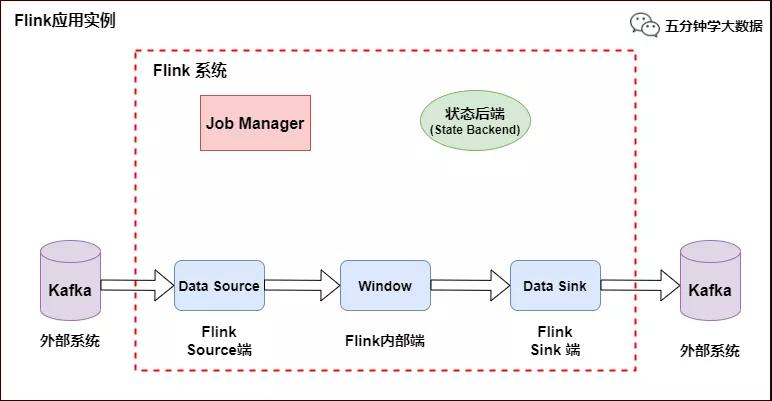
Flink 應用示例
如上圖所示,Flink 中包含以下組件:
- 一個 Source,從 Kafka 中讀取數據(即 KafkaConsumer)
- 一個時間窗口化的聚會操作(Window)
- 一個 Sink,將結果寫入到 Kafka(即 KafkaProducer)
若要 Sink 支持精準一次處理語義(EOS),它必須以事務的方式寫數據到 Kafka,這樣當提交事務時兩次 Checkpoint 間的所有寫入操作當作為一個事務被提交。這確保了出現故障或崩潰時這些寫入操作能夠被回滾。
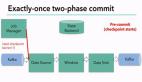
當然了,在一個分布式且含有多個并發執行 Sink 的應用中,僅僅執行單次提交或回滾是不夠的,因為所有組件都必須對這些提交或回滾達成共識,這樣才能保證得到一個一致性的結果。Flink 使用兩階段提交協議以及預提交(Pre-commit)階段來解決這個問題。
兩階段提交協議(2PC)
兩階段提交協議(Two-Phase Commit,2PC)是很常用的解決分布式事務問題的方式,它可以保證在分布式事務中,要么所有參與進程都提交事務,要么都取消,即實現 ACID 中的 A (原子性)。
在數據一致性的環境下,其代表的含義是:要么所有備份數據同時更改某個數值,要么都不改,以此來達到數據的強一致性。
兩階段提交協議中有兩個重要角色,協調者(Coordinator)和參與者(Participant),其中協調者只有一個,起到分布式事務的協調管理作用,參與者有多個。
顧名思義,兩階段提交將提交過程劃分為連續的兩個階段:表決階段(Voting)和提交階段(Commit)。
兩階段提交協議過程如下圖所示:
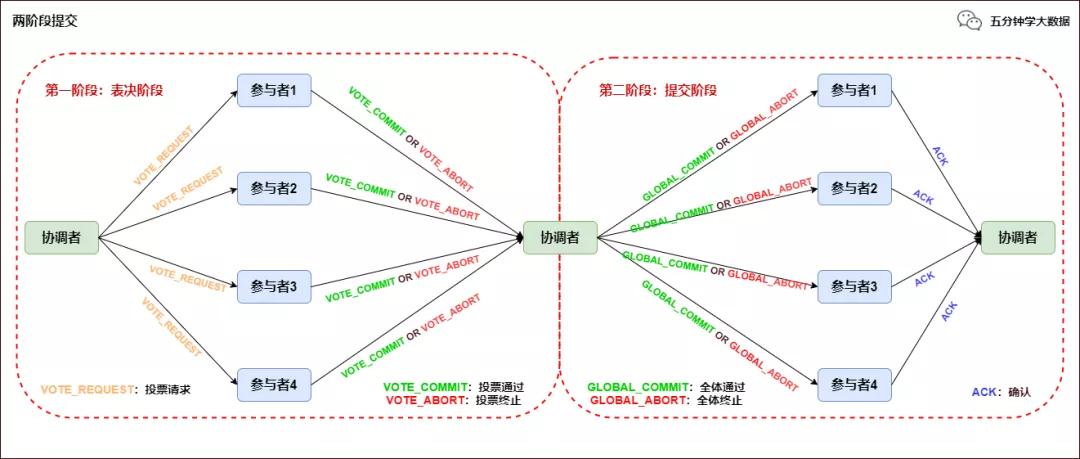
兩階段提交協議
第一階段:表決階段
協調者向所有參與者發送一個 VOTE_REQUEST 消息。
當參與者接收到 VOTE_REQUEST 消息,向協調者發送 VOTE_COMMIT 消息作為回應,告訴協調者自己已經做好準備提交準備,如果參與者沒有準備好或遇到其他故障,就返回一個 VOTE_ABORT 消息,告訴協調者目前無法提交事務。
第二階段:提交階段
- 協調者收集來自各個參與者的表決消息。如果所有參與者一致認為可以提交事務,那么協調者決定事務的最終提交,在此情形下協調者向所有參與者發送一個 GLOBAL_COMMIT 消息,通知參與者進行本地提交;如果所有參與者中有任意一個返回消息是 VOTE_ABORT,協調者就會取消事務,向所有參與者廣播一條 GLOBAL_ABORT 消息通知所有的參與者取消事務。
- 每個提交了表決信息的參與者等候協調者返回消息,如果參與者接收到一個 GLOBAL_COMMIT 消息,那么參與者提交本地事務,否則如果接收到 GLOBAL_ABORT 消息,則參與者取消本地事務。
兩階段提交協議在 Flink 中的應用
Flink 的兩階段提交思路:
我們從 Flink 程序啟動到消費 Kafka 數據,最后到 Flink 將數據 Sink 到 Kafka 為止,來分析 Flink 的精準一次處理。
- 當 Checkpoint 啟動時,JobManager 會將檢查點分界線(checkpoint battier)注入數據流,checkpoint barrier 會在算子間傳遞下去,如下如所示:
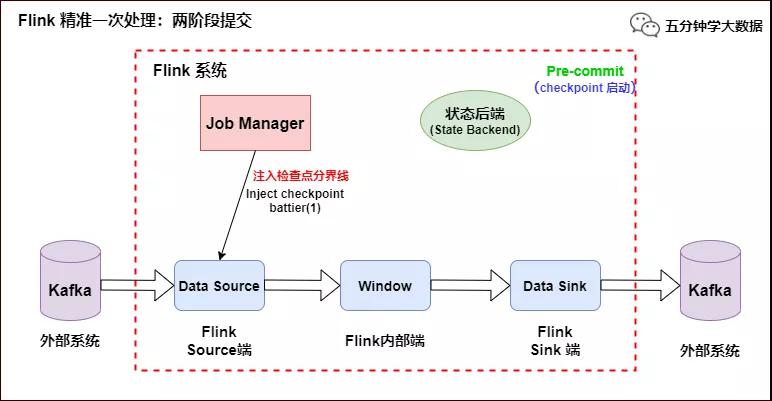
Flink 精準一次處理:Checkpoint 啟動
- Source 端:Flink Kafka Source 負責保存 Kafka 消費 offset,當 Chckpoint 成功時 Flink 負責提交這些寫入,否則就終止取消掉它們,當 Chckpoint 完成位移保存,它會將 checkpoint barrier(檢查點分界線) 傳給下一個 Operator,然后每個算子會對當前的狀態做個快照,保存到狀態后端(State Backend)。
對于 Source 任務而言,就會把當前的 offset 作為狀態保存起來。下次從 Checkpoint 恢復時,Source 任務可以重新提交偏移量,從上次保存的位置開始重新消費數據,如下圖所示:
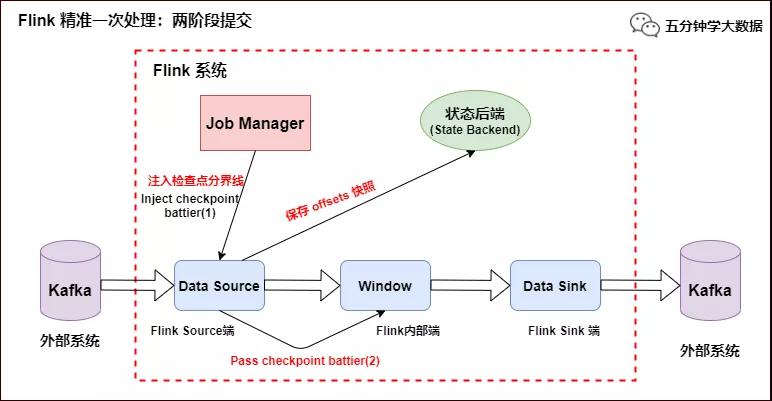
Flink 精準一次處理:checkpoint barrier 及 offset 保存
- Slink 端:從 Source 端開始,每個內部的 transform 任務遇到 checkpoint barrier(檢查點分界線)時,都會把狀態存到 Checkpoint 里。數據處理完畢到 Sink 端時,Sink 任務首先把數據寫入外部 Kafka,這些數據都屬于預提交的事務(還不能被消費),此時的 Pre-commit 預提交階段下 Data Sink 在保存狀態到狀態后端的同時還必須預提交它的外部事務,如下圖所示:
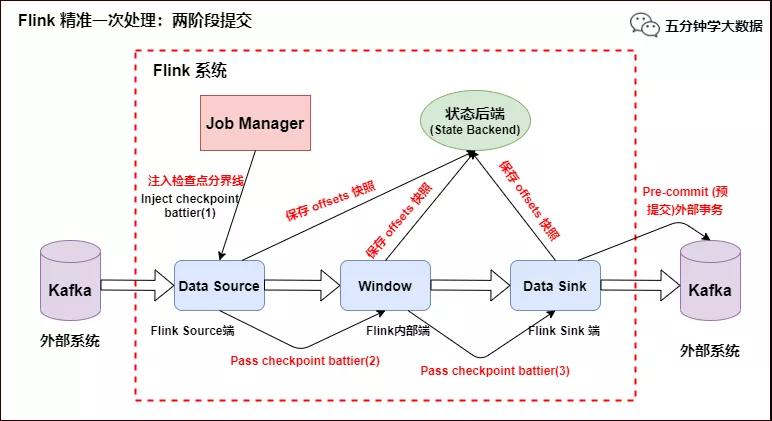
Flink 精準一次處理:預提交到外部系統
- 當所有算子任務的快照完成(所有創建的快照都被視為是 Checkpoint 的一部分),也就是這次的 Checkpoint 完成時,JobManager 會向所有任務發通知,確認這次 Checkpoint 完成,此時 Pre-commit 預提交階段才算完成。才正式到兩階段提交協議的第二個階段:commit 階段。該階段中 JobManager 會為應用中每個 Operator 發起 Checkpoint 已完成的回調邏輯。
本例中的 Data Source 和窗口操作無外部狀態,因此在該階段,這兩個 Opeartor 無需執行任何邏輯,但是 Data Sink 是有外部狀態的,此時我們必須提交外部事務,當 Sink 任務收到確認通知,就會正式提交之前的事務,Kafka 中未確認的數據就改為“已確認”,數據就真正可以被消費了,如下圖所示:
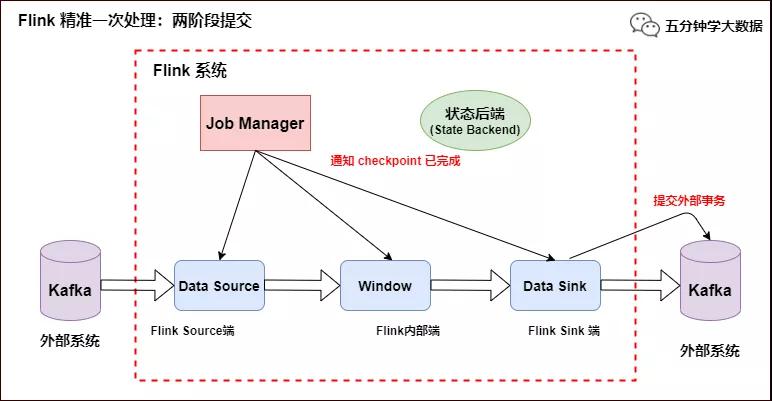
Flink 精準一次處理:數據精準被消費
注:Flink 由 JobManager 協調各個 TaskManager 進行 Checkpoint 存儲,Checkpoint 保存在 StateBackend(狀態后端) 中,默認 StateBackend 是內存級的,也可以改為文件級的進行持久化保存。
最后,一張圖總結下 Flink 的 EOS: