用于圖優化的端到端、可轉移的深度強化學習
越來越多的應用程序是由在不同加速器集上訓練的大型復雜神經網絡驅動的。這個過程由 ML 編譯器促進,將高級計算圖映射到低級、特定于設備的可執行文件。為此,ML 編譯器需要解決許多優化問題,包括圖形重寫、設備上的操作分配、操作融合、張量的布局和平鋪以及調度。例如,在設備放置問題中,編譯器需要確定計算圖中的操作到目標物理設備之間的映射,以便可以最小化目標函數,例如訓練步驟時間。放置性能由復雜因素的混合決定,包括設備間網絡帶寬、峰值設備內存、協同定位約束等,這使得啟發式算法或基于搜索的算法具有挑戰性,這些算法通常滿足于快速但低于-最佳,解決方案。此外,啟發式很難開發和維護,尤其是在出現新的模型架構時。
最近使用基于學習的方法的嘗試已經證明了有希望的結果,但它們有許多限制,使其無法在實踐中部署。首先,這些方法不容易推廣到看不見的圖,尤其是那些由較新的模型架構產生的圖,其次,它們的樣本效率很差,導致訓練過程中的資源消耗很高。最后,它們只能解決單個優化任務,因此無法捕獲編譯堆棧中緊耦合優化問題之間的依賴關系。
在最近在NeurIPS 2020 上作為口頭論文發表的“Transferable Graph Optimizers for ML Compilers ”中,我們提出了一種用于計算圖優化 (GO) 的端到端、可轉移的深度強化學習方法,該方法克服了上述所有限制。與TensorFlow默認優化相比,我們在三個圖優化任務上展示了 33%-60% 的加速。在包括Inception-v3、Transformer-XL和WaveNet在內的由多達 80,000 個節點組成的不同代表性圖集上,GO 比專家優化平均提高了 21%,比現有技術提高了 18%,提高了 15 倍更快的收斂。
ML 編譯器中的圖優化問題 ML 編譯器
中經常出現三個耦合優化任務,我們將它們表述為可以使用學習策略解決的決策問題。每個任務的決策問題可以重新定義為為計算圖中的每個節點做出決策。
第一個優化任務是設備放置,其目標是確定如何最好地將圖的節點分配給它運行的物理設備,從而最大限度地減少端到端的運行時間。
第二個優化任務是操作調度。計算圖中的操作已準備就緒當它的傳入張量存在于設備內存中時運行。一個常用的調度策略是為每個設備維護一個就緒的操作隊列,并按先進先出的順序調度操作。但是,這種調度策略沒有考慮到其他設備上可能被某個操作阻塞的下游操作,并且經常導致調度未充分利用的設備。為了找到可以跟蹤此類跨設備依賴關系的調度,我們的方法使用基于優先級的調度算法,該算法根據每個操作的優先級調度就緒隊列中的操作。類似于設備放置,操作調度可以被表述為學習策略的問題,該策略為圖中的每個節點分配優先級,以根據運行時間最大化獎勵。
第三個優化任務是操作融合。為簡潔起見,我們在這里省略了對這個問題的詳細討論,而只是注意類似于基于優先級的調度,操作融合也可以使用基于優先級的算法來決定融合哪些節點。在這種情況下,策略網絡的目標再次是為圖中的每個節點分配優先級。
最后,重要的是要認識到在三個優化問題中的每一個中做出的決定都會影響其他問題的最佳決策。例如,將兩個節點放在兩個不同的設備上會有效地禁用融合并引入可能影響調度的通信延遲。
RL 策略網絡架構
我們的研究提出了 GO,這是一種深度 RL 框架,可適用于單獨或聯合解決上述每個優化問題。所提議的架構有三個關鍵方面:
首先,我們使用圖神經網絡(特別是GraphSAGE)來捕獲計算圖中編碼的拓撲信息。GraphSAGE 的歸納網絡利用節點屬性信息泛化到以前看不見的圖,這使得對看不見的數據做出決策而不會產生大量的訓練成本。
其次,許多模型的計算圖通常包含超過 1 萬個節點。在如此大規模上有效地解決優化問題需要網絡能夠捕獲節點之間的遠程依賴關系。GO 的架構包括一個可擴展的注意力網絡,該網絡使用段級遞歸來捕獲這種遠程節點依賴關系。
第三,ML 編譯器需要解決來自不同應用領域的各種圖形的優化問題。用異構圖訓練共享策略網絡的幼稚策略不太可能捕捉到特定類別圖的特質。為了克服這個問題,GO 使用了一種特征調制機制,該機制允許網絡專門針對特定的圖類型而無需增加參數數量。
為了共同解決多個相關優化任務,GO 能夠為每個任務添加額外的循環注意層,并在不同任務之間共享參數。具有剩余動作連接的循環注意層能夠跟蹤任務間的依賴關系。

結果
接下來,我們展示了基于真實硬件測量的設備放置任務的單任務加速評估結果,對具有不同 GO 變體的不可見圖的泛化,以及聯合優化操作融合、設備放置和調度的多任務性能。
加速:
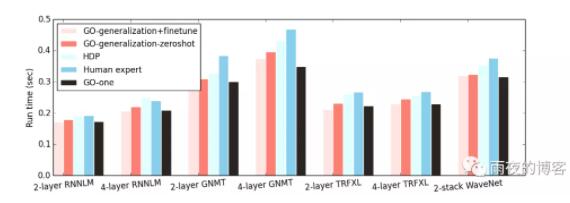
為了評估該架構的性能,我們將 GO 應用于基于真實硬件評估的設備放置問題,我們首先在每個工作負載上分別訓練模型。這種稱為GO-one 的方法始終優于專家手動放置 (HP)、TensorFlow METIS放置和分層設備放置(HDP)——當前最先進的基于強化學習的設備放置。重要的是,憑借高效的端到端單次布局,GO-one 的布局網絡在 HDP 上的收斂時間加快了 15 倍。
我們的實證結果表明,GO-one始終優于專家布局、TensorFlow METIS 布局和分層設備布局(HDP)。由于 GO 的設計方式可以擴展到由超過 80,000 個節點組成的超大圖,例如 8 層Google 神經機器翻譯(GNMT) 模型,因此它優于以前的方法,包括 HDP、REGAL和Placeto。GO 為 GNMT 等大型圖實現了優化的圖運行時間,分別比 HP 和 HDP 快 21.7% 和 36.5%。總體而言,GO-one 平均減少了 20.5% 和 18.2% 的運行時間分別與 HP 和 HDP 相比,包含 14 個不同的圖形集。重要的是,憑借高效的端到端單次布局,GO-one的布局網絡在 HDP 上的收斂時間加快了15 倍。
泛化:
GO 使用離線預訓練對未見過的圖進行泛化,然后對未見過的圖進行微調。在預訓練期間,我們在訓練集中的圖的異構子集上訓練 GO。在切換到下一個之前,我們在每個這樣的批次圖上訓練 GO 1000 步。然后在保留圖上對這個預訓練模型進行微調(GO-generalization+finetune),步驟少于 50 步,通常不到一分鐘。GO-generalization+finetune for hold-out graphs 在所有數據集上始終優于專家放置和 HDP,并且平均匹配GO-one。
我們還直接在預訓練模型上運行推理,而不對目標保持圖進行任何微調,并將其命名為GO-generalization-zeroshot。這種未調整模型的性能僅比GO-generalization+finetune差一點,而略好于專家布局和 HDP。這表明圖嵌入和學習到的策略都有效地轉移,允許模型泛化到看不見的數據。
協同優化布局、調度和融合(pl+sch+fu):
同時優化布局、調度和融合與未優化的單 GPU 情況相比提供 30%-73% 的加速,與 TensorFlow 相比提供 33%-60% 的加速默認放置、調度和融合。與單獨優化每個任務相比,多任務 GO ( pl+sch+fu ) 比單任務 GO ( p | sch | fu )——一次優化所有任務——平均高 7.8%。此外,對于所有工作負載,與優化任意兩個任務并為第三個任務使用默認策略相比,共同優化所有三個任務可提供更快的運行時間。
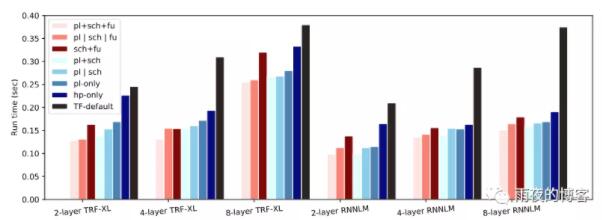
pl+sch:多任務 GO 使用默認融合協同優化布局和調度。sch+fu:多任務 GO 協同優化調度和融合與人類安置。pl | sch | fu:GO 分別優化布局、調度和融合。pl+sch+fu:多任務 GO 協同優化布局、調度和融合。
結論
硬件加速器日益復雜和多樣化,使得開發健壯且適應性強的 ML 框架變得既繁瑣又耗時,通常需要數百名工程師的多年努力。在本文中,我們證明了此類框架中的許多優化問題都可以使用精心設計的學習方法有效且最優地解決。