













2021年最酷的數據科學庫
我成為數據科學家是因為我最喜歡找到解決復雜問題的解決方案,工作的創造性部分以及從數據中獲得的見解。諸如清理數據,預處理和調整超參數之類的無聊的事情并沒有給我帶來什么樂趣,這就是為什么我嘗試盡可能自動執行這些任務的原因。
如果您還喜歡將無聊的東西自動化,那么您會喜歡本文中將要介紹的庫。
如今,沒有人使用Scikit-Learn的線性回歸來預測Kaggle競爭中的房價,因為XGboost方法更準確。
但是,XGboost超參數很難調整。它們很多,而機器學習工程師在使用此算法時浪費了很多時間進行調整。好吧,不再了。
介紹Xgboost-AutoTune
我很高興與您分享由MIT的Sylwia Oliwia開發的Python Xgboost AutoTune庫,該庫最近已成為我自動XGboost微調的首選。
讓我們看一下此氣候數據集的示例,我們可以根據溫室氣體濃度預測溫度升高,并評估每種氣體的影響。
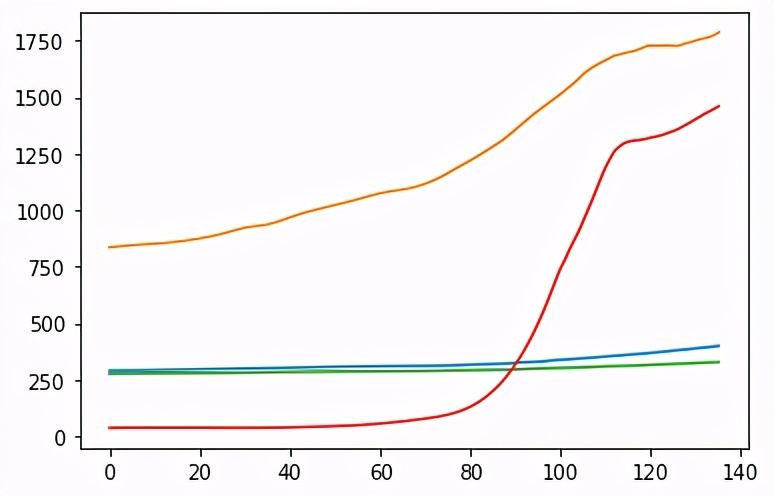
首先,我們導入數據集并繪制CO2,CH4,N20和合成氣的氣體濃度:
通過運行,我們可以看到過去140年中所有溫室氣體的增加情況:
太酷了,現在我們可以導入我提到的Autotuning庫,但是以防萬一您沒有下載存儲庫,我也會在此處顯示代碼:
基本上,您只需要記住該自動調整庫的主要方法是“ fit_parameters”,只需調用它,它就為找到超參數的最佳值進行了所有艱苦的工作,如下所示:
請注意,我們選擇了一種計分方法(在本例中為均方根對數誤差RMSLE),并且初始模型為XGBRegressor,因為這是一個回歸問題(另一個選項將是分類問題)。
太酷了,因此我們僅用兩行代碼構建了最佳的XGboost模型,現在讓我們做出預測:
這將輸出一個圖形,其中包含預測溫度與測試集中的實際值的對比:
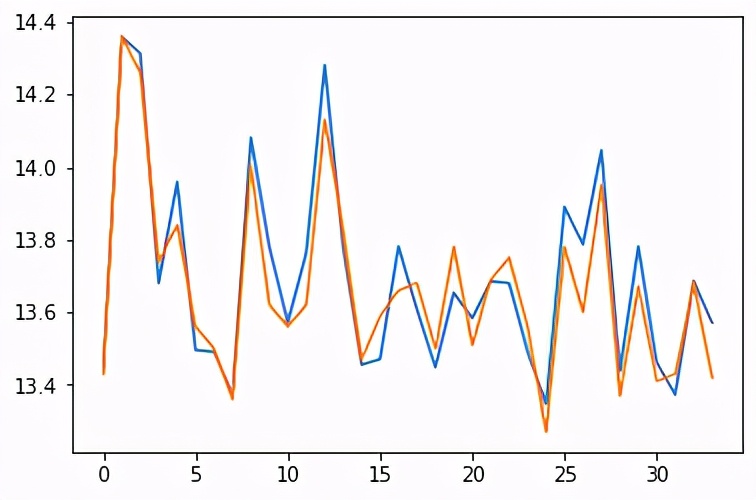
看起來不錯。
現在,如果我們想知道在變暖作用中最重要的氣體是什么,我們可以做:
這將返回以下內容:
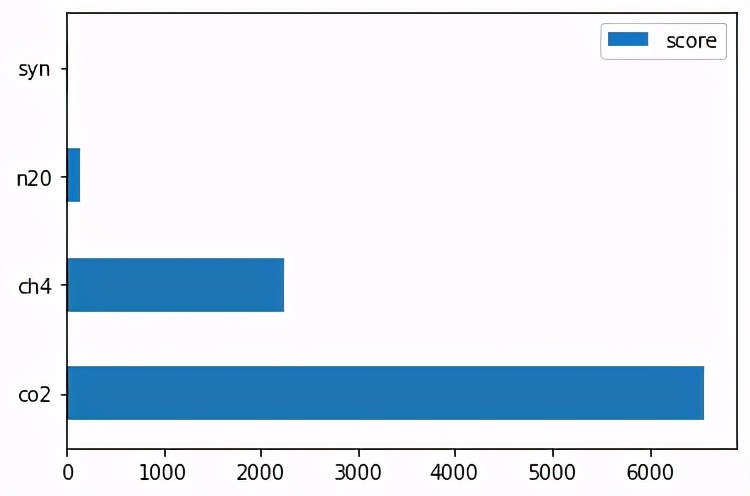
正如預期的那樣,CO2是效果最強的氣體,這不足為奇,但是我們可以看到CH4也具有非常重要的作用,最重要的是,這種模型訓練起來非常快。
結論
梯度提升是其不涉及深度學習的回歸和分類任務中最常用的算法,因為它具有很高的準確性,可解釋性和速度。
遺憾的是,盡管Python生態系統提供了XGboost庫,但是它沒有像Scikit-Learn這樣的其他庫那么廣泛,并且數據科學家必須手動完成調整參數,這會造成很多麻煩。
這就是為什么我認為這個自動調整庫是一個需要共享的瑰寶。
我最后的反思是:數據科學家的聘用費用昂貴,而他們的時間最好花在進行非瑣碎的工作上。
您能想象一位銷售主管打了電話嗎?當然那不是他們的工作。
好吧,可悲的是,許多數據科學家都是各行各業的佼佼者,他們的工作通常包括:查找數據,清理數據,攝取數據,決定使用的模型,編碼模型,編碼腳本以調整模型,部署模型,將模型展示給企業,上帝知道還有什么。
因此,數據科學家擁有的自動化工具越多,她就越能專注于最重要的工作:理解數據并從中獲取價值
希望您喜歡這篇文章,它可以幫助您更快地訓練模型。
祝您編碼愉快!
原文鏈接:https://towardsdatascience.com/the-coolest-data-science-library-i-found-in-2021-956af253fb2c












