Github熱榜:2021年33篇最酷AI論文綜述!多位華人作者入選
現(xiàn)如今,AI技術(shù)突飛猛進(jìn),每年都會誕生很多優(yōu)秀的論文。
想知道2021年有哪些paper是你不能錯過的嗎?
這不,在GitHub上,有一位小哥放出了這樣一個項目,目前,里面總結(jié)了33篇今年必看論文,堪稱「良心寶藏」。

??https://github.com/louisfb01/best_AI_papers_2021??
這個項目的名稱是「2021年充滿驚喜的人工智能論文綜述」,作者是Louis-Fran?ois Bouchard(GitHub名為louisfb01),上線一天就收獲314個star(持續(xù)上漲中)。
Louis-Fran?ois Bouchard來自加拿大蒙特利爾,我目前在école de Technologie Supérieure攻讀人工智能-計算機(jī)視覺碩士學(xué)位,同時在designstripe兼職做首席人工智能研究科學(xué)家。
值得一提的是,Louis還在YouTube上有自己的頻道「What's AI」。
What's AI主頁:https://www.louisbouchard.ai/
Louis之所以在YouTube上做「What's AI」這個頻道,是希望用簡單的語言分享和解釋人工智能,為大家分享新的研究和應(yīng)用。

YouTube What's AI 頻道:https://www.youtube.com/c/WhatsAI/featured
Louis想為所有人揭開人工智能「黑匣子」的神秘面紗,讓人們意識到使用它的風(fēng)險。
Louis是一個很有分享精神的人,喜歡學(xué)習(xí)和分享他所學(xué)到的東西。他寫了不少文章,也在自己的頻道更新視頻,在GitHub上也正在做一些有趣的項目。
其實,「2021年充滿驚喜的AI論文綜述」已經(jīng)是Louis更新「AI論文綜述」系列的第二年了。
在2020年,Louis也上線了「2020年充滿驚喜的AI論文綜述」項目,里面是按發(fā)布日期排列的AI最新突破的精選列表,帶有清晰的視頻解釋,更深入文章的鏈接和源代碼。

??https://github.com/louisfb01/Best_AI_paper_2020??
下面,就來看看「2021年充滿驚喜的AI論文綜述」里面到底有哪些讓人驚喜的AI最新研究成果吧!
2021年充滿驚喜的AI論文綜述
盡管世界仍在慢慢復(fù)蘇,但研究并沒有放緩其步伐,尤其是在人工智能領(lǐng)域。
此外,2021年還強(qiáng)調(diào)了許多重要的方面,如道德方面、重視偏見、治理、透明度等等。
人工智能和我們對人腦的理解及其與AI的聯(lián)系正在不斷發(fā)展,在不久的將來,也許有希望改善我們的生活質(zhì)量。
精彩論文節(jié)選
1、DALL-E:Zero-Shot Text-to-Image Generation,來自O(shè)penAI

論文地址:https://arxiv.org/pdf/2102.12092.pdf

一個Emoji的小企鵝,帶著藍(lán)帽子,紅手套,穿著黃褲子示例
論文介紹:
GPT-3表明,語言可以用來指導(dǎo)大型神經(jīng)網(wǎng)絡(luò)執(zhí)行各種文本生成任務(wù)。
而Image GPT表明,同樣類型的神經(jīng)網(wǎng)絡(luò)也可以用來生成高保真度的圖像。這個突破說明通過文字語言來操縱視覺概念現(xiàn)在已經(jīng)觸手可及。
OpenAI成功地訓(xùn)練了一個能夠從文本標(biāo)題生成圖像的網(wǎng)絡(luò)。它非常類似于GPT-3和Image GPT,并產(chǎn)生了驚人的結(jié)果。
? ?
?
和GPT-3一樣,DALL-E也是一個Transformer語言模型。它同時接收文本和圖像作為單一數(shù)據(jù)流,其中包含多達(dá)1280個token,并使用最大似然估計來進(jìn)行訓(xùn)練,以一個接一個地生成所有的token。
這個訓(xùn)練過程不僅允許DALL-E可以從頭開始生成圖像,而且還可以重新生成現(xiàn)有圖像的任何矩形區(qū)域,與文本提示內(nèi)容基本一致。

利用DALL·E生成企鵝抱枕
2、Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows

論文地址:https://arxiv.org/pdf/2103.14030.pdf
論文介紹:
這篇文章介紹了一種新的、可以應(yīng)用于計算機(jī)視覺里的Transformer,Swin Transformer。
Transformer解決計算機(jī)視覺問題的挑戰(zhàn)主要來自兩個領(lǐng)域:圖像的比例差異很大,而且圖像具有很高的分辨率,在有些視覺任務(wù)和如語義分割中,像素級的密集預(yù)測對于Transformer來說是難以處理的,因為其self-attention的計算復(fù)雜度與圖像大小成二次關(guān)系。

為了克服這些問題,Swin Transformer構(gòu)建了分層Transformer特征圖,并采用移位窗口計算。移位窗口方案通過將self-attention計算限制在不重疊的局部窗口(用紅色標(biāo)出),同時還允許跨窗口連接,帶來了更高的效率。
Swin Transformer通過從小尺寸的面片(用灰色勾勒)開始,并逐漸合并更深的Transformer層中的相鄰面片來構(gòu)建分層表示。這種分層體系結(jié)構(gòu)可以靈活地在各種尺度上建模,并且在圖像大小方面具有線性計算復(fù)雜度。線性計算復(fù)雜度是通過在分割圖像的非重疊窗口(用紅色標(biāo)出)內(nèi)局部計算自我注意來實現(xiàn)的。 每個窗口中的面片數(shù)量是固定的,因此復(fù)雜度與圖像大小成線性關(guān)系。
Swin Transformer在圖像分類、目標(biāo)檢測和語義分割等識別任務(wù)上取得了很好的性能,在三個任務(wù)中,Swin Transformer的時間延遲與ViT,DeiT和ResNeXt模型相似,但性能卻得到了大幅提升:COCO test-dev 58.7 box AP和51.1 mask AP,力壓之前的最先進(jìn)結(jié)果2.7 box AP和2.6 mask AP。 在ADE20K語義分割任務(wù)中,Swin Transformer在驗證集上獲得了53.5 mIoU,比以前的最先進(jìn)水平(SETR)提高了3.2 mIoU。 在ImageNet-1K圖像分類中,它也達(dá)到了87.3%的最高精度,充分展現(xiàn)Transformer模型作為新視覺backbone的潛力。
該論文一作劉澤是中科大的學(xué)生,在微軟亞洲研究院實習(xí)。他于2019年獲中國科技大學(xué)學(xué)士學(xué)位,并以最高榮譽(yù)獲得郭沫若獎學(xué)金。
個人主頁介紹,其2篇論文和1篇Oral被ICCV2021接收。
個人主頁:https://zeliu98.github.io/
3、StyleCLIP: Text-driven manipulation of StyleGAN imagery

論文地址:https://arxiv.org/pdf/2103.17249.pdf
論文介紹:
這是一項來自以色列的研究人員的工作StyleCLIP,可以使用基于人工智能的生成對抗性網(wǎng)絡(luò)對照片進(jìn)行超逼真的修改,并且只需要讓用戶輸入他們想要的東西的描述即可,無需輸入特定的圖片。
這個模型也會產(chǎn)生一些非常搞笑的結(jié)果。例如可以給Facebook 的CEO馬克 · 扎克伯格的臉隨意修改,例如讓他看起來禿頂,戴上眼鏡,或者在下巴上扎上山羊胡。
這個「火星人」的臉上似乎也有了一點人類的感覺。

StyleCLIP模型主要由StyleGAN和CLIP模型組成。
StyleGAN可以在不同領(lǐng)域(domain)生成高度真實圖像,最近也有大量的工作都集中在理解如何使用StyleGAN的隱空間來處理生成的和真實的圖像。

但發(fā)現(xiàn)語義上潛在有意義的操作通常需要對多個自由度進(jìn)行細(xì)致的檢查,這需要耗費大量的人工操作,或者需要為每個期望的風(fēng)格創(chuàng)建一個帶注釋的圖像集合。
既然基于注釋,那多模態(tài)模型CLIP(Contrastive Language-Image Pre-training)的能力是否就可以利用上,來開發(fā)一個不需要手動操作的基于文本的StyleGAN圖像處理。
例如輸入可愛的貓(cute cat),瞇眼睛的貓就被放大了眼睛,獲取了所有可愛小貓的特征,還可以老虎變獅子等等。
4、GitHub Copilot & Codex: Evaluating Large Language Models Trained on Code

論文地址:https://arxiv.org/pdf/2107.03374.pdf
論文介紹:
OpenAI在2020年,曾推出1750億參數(shù)的GPT-3,參數(shù)規(guī)模直逼人類神經(jīng)元的數(shù)量。
GPT-3使用了在2019年之前的互聯(lián)網(wǎng)上的幾乎所有公開的書面文本進(jìn)行訓(xùn)練,所以它對于自然語言是有一定理解能力的,能作詩、聊天、生成文本等等。
今年夏天,OpenAI 發(fā)布了 Codex。

Codex基于GPT-3進(jìn)行訓(xùn)練,接受了從GitHub中提取的TB級公開代碼以及英語語言示例的訓(xùn)練。
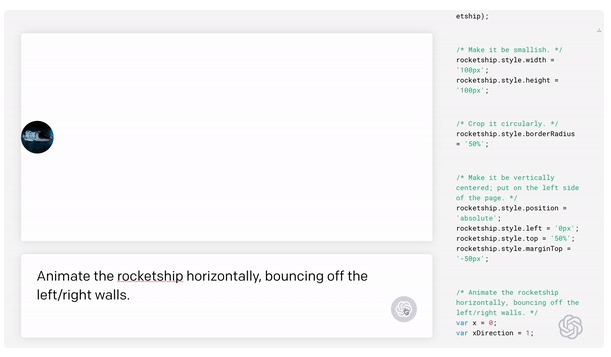
只要你對Codex發(fā)號施令,它就會將英語翻譯成代碼。
? ?
?
隨后,你的雙手離開鍵盤,Codex會自動編程,火箭就自己動起來了。
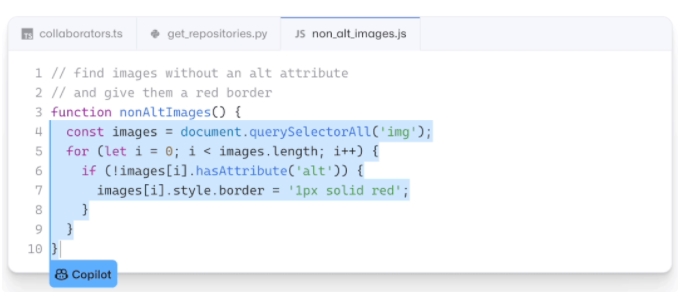
而Copilot正是建立在OpenAI強(qiáng)大的Codex算法之上,獲得了「海納百川」的代碼積累和前所未有的代碼生產(chǎn)能力。

Copilot不僅僅可以模仿它見過的代碼,而且還會分析利用函數(shù)名、方法名、類名和注釋的上下文來生成和合成代碼,為開發(fā)人員提供編輯器中整行代碼或函數(shù)的建議。
? ?
?
它能減少工程師通過API文檔做苦工的時間,還能幫忙編寫測試代碼。
? ?
?
5、Skillful Precipitation Nowcasting using Deep Generative Models of Radar

論文地址:https://www.nature.com/articles/s41586-021-03854-z
論文介紹:
今天的天氣預(yù)測是由強(qiáng)大的數(shù)值天氣預(yù)報(NWP)系統(tǒng)驅(qū)動的。通過解決物理方程,數(shù)值天氣預(yù)報系統(tǒng)可以提前數(shù)天得到地球尺度的預(yù)測。然而,它們很難在兩小時內(nèi)產(chǎn)生高分辨率的預(yù)測。
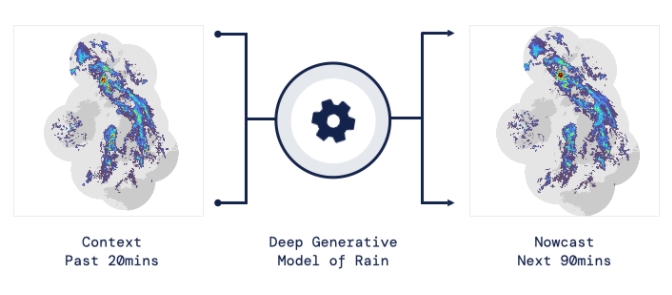
即時預(yù)報填補(bǔ)了這一關(guān)鍵時間區(qū)間的性能空白。氣象傳感的進(jìn)步使高分辨率雷達(dá)可以高頻地(在1公里分辨率下每5分鐘)提供測量出的地面降水量數(shù)據(jù)。
? ?
?
過去20分鐘的觀測雷達(dá)被用來提供未來90分鐘的概率預(yù)測
已有的短期預(yù)測方法,如STEPS和PySTEPS,沿用NWP的方法來考慮不確定性,但按照帶有雷達(dá)信息的平流方程對降水進(jìn)行建模。
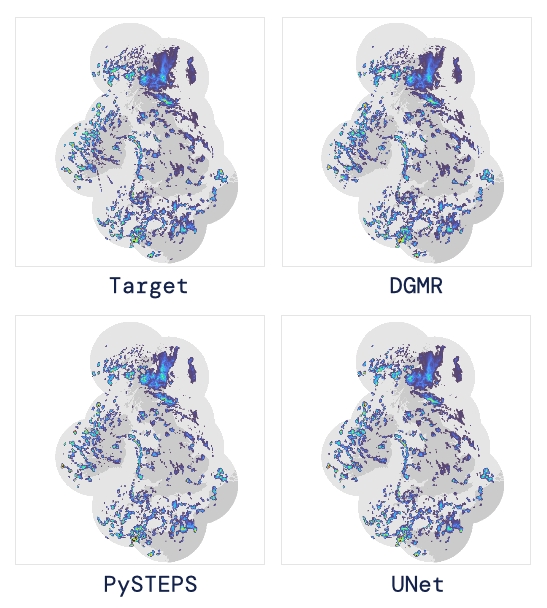
基于深度學(xué)習(xí)的方法則不需要對平流方程的依賴,但現(xiàn)有方法側(cè)重于特定地點的預(yù)測,而不是對整個降水場的概率預(yù)測,這使其無法在多個空間和時間集合中同時提供一致的預(yù)測結(jié)果,限制了實用性。
? ?
?
為此,DeepMind使用深度生成模型(DGMR)為概率預(yù)報開發(fā)了一種觀測驅(qū)動的方法。DGMR是學(xué)習(xí)數(shù)據(jù)概率分布的統(tǒng)計模型,可以從學(xué)習(xí)到的分布中輕松生成樣本。由于生成模型從根本上是概率性的,可以從給定的歷史雷達(dá)的條件分布中模擬許多樣本,生成預(yù)測集合。此外,DGMR既能從觀測數(shù)據(jù)中學(xué)習(xí),又能表示多個空間和時間尺度上的不確定性。
? ?
?
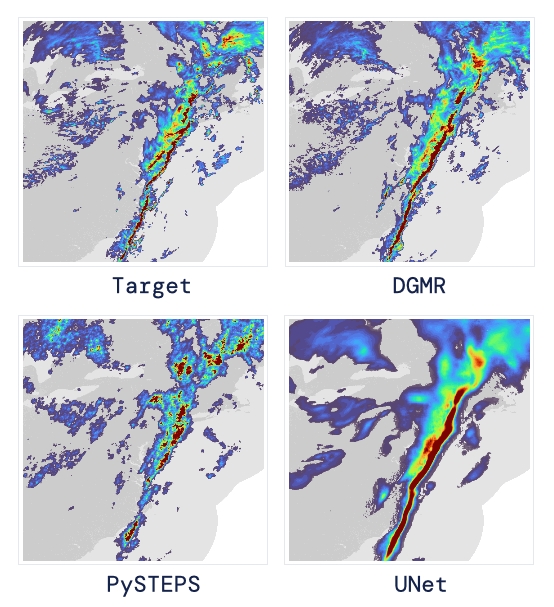
結(jié)果表明,DeepMind的深度生成模型可以提供更好的預(yù)測質(zhì)量、預(yù)測一致性和預(yù)測價值。模型在1,536公里×1,280公里的區(qū)域內(nèi)產(chǎn)生了逼真且時空一致的預(yù)測,提前期為5-90分鐘。

DGMR能更好地預(yù)測較長時段的空間覆蓋和對流,同時不會高估強(qiáng)度
通過50多位氣象專家的系統(tǒng)評估,與其他兩種競爭方法相比,DeepMind的生成模型以89%的絕對優(yōu)勢在準(zhǔn)確性和實用性兩方面排名第一。
其他有意思的論文都可以在Louis的GitHub主頁上找到,目前這個項目仍在更新中,收藏一波,繼續(xù)追更!