機器學習:都有哪些具體分類?項目的流程是怎樣?
作者:NK冬至
機器學習、人工智能應該是近幾年最火的關鍵詞之一了。今天分享一些機器學習的基礎知識。如果有啥不正確的地方,歡迎各位大佬指正。
機器學習、人工智能應該是近幾年最火的關鍵詞之一了。今天分享一些機器學習的基礎知識。如果有啥不正確的地方,歡迎各位大佬指正。
01機器學習的定義
在說機器學習之前先明確一下,什么是人類的學習行為呢?
可以這樣總結,人類從歷史經驗中獲取規律,并將其應用到新的類似場景中,就是人類的學習行為。
相對應的,機器學習是指讓機器去訓練、去學習,讓機器從大量數據中找到數據中的內在特征,從而對新事物做出判斷。
02機器學習的分類
機器學習有哪些類別呢?按照不同的分類方式,有不同的細分類別。梳理了一下,主要有以下的概況圖:
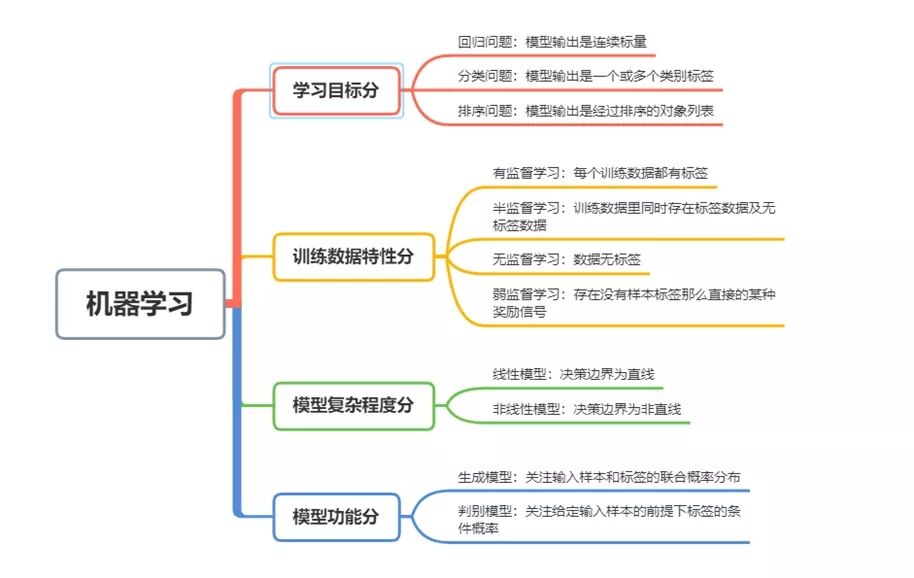
(1)按照學習目標分類
什么是機器學習目標呢?通俗來講,就是我們想通過機器學習,最終實現的結果形態是什么樣。
按照學習目標,主要可以分為三類:回歸問題、分類問題、排序問題。
- 回歸問題:解決的是目標是連續性變量的問題。比如想根據身高預測體重,體重就是一個連續性變量。
- 分類問題:解決的是目標是離散的標簽的問題。比如預測一個人是男還是女。
- 排序問題:模型輸出的是經過排序的對象列表。
(2)按照訓練數據的特性分類
上文提到了,進行機器學習是需要訓練數據為基礎的(不然機器沒法學習呀)。按照訓練數據的特性,主要分為以下兩類:
- 有監督學習:通過已有的訓練樣本去訓練得到一個最優模型,再利用這個模型將所有的輸入映射為相應的輸出,對輸出進行簡單的判斷從而實現預測和分類的目的,也就具有了對未知數據進行預測和分類的能力。有監督算法常見的有:線性回歸算法、BP神經網絡算法、決策樹、支持向量機、KNN等。
- 無監督學習:訓練樣本的標記信息未知,目標是通過對無標記訓練樣本的學習來揭示數據的內在性質及規律,為進一步的數據分析提供基礎,此類學習任務中研究最多、應用最廣的是"聚類",聚類目的在于把相似的東西聚在一起,主要通過計算樣本間和群體間距離得到。深度學習和PCA都屬于無監督學習的范疇。無監督算法常見的有:密度估計、異常檢測、層次聚類、EM算法、K-Means算法、DBSCAN算法等。
(3)按照模型的復雜程度分類
按照模型的復雜度,主要分為兩類:線性模型和非線性模型。
- 線性模型:決策邊界為直線。例如邏輯回歸模型。
- 非線性模型:決策邊界為非直線。例如神經網絡模型。
(4)按照模型功能分類
按照模型的功能來分類,主要分為判別模型與生成模型。
- 判別模型:由數據直接學習決策函數f(x)或條件概率分布P(y|x)進行預測的模型,其關心的是對給定的輸入x,應該預測什么樣的輸出y。常見的k近鄰法、感知機、決策樹、邏輯回歸、線性回歸、最大熵模型。
- 生成模型:由數據學習輸入和輸出聯合概率分布P(x,y),然后求出后驗概率分布P(y|x)進行預測的模型。常見的生成模型樸素貝葉斯、隱馬爾可夫(em算法)。
03機器學習的基本流程
對于一個機器學習項目而言,主要的流程有以下概況:
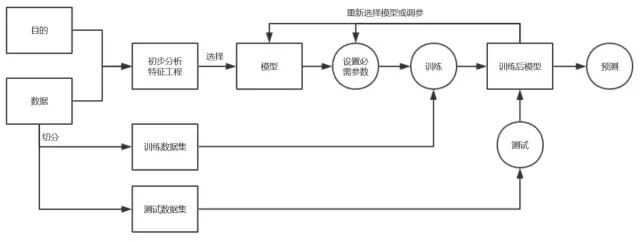
(1)數據預處理
數據清洗是檢測和去除數據集中的噪聲數據和無關數據,處理遺漏數據,去除空白數據域和知識背景下的白噪聲。
(2)數據切分
在機器學習中,通常將所有的數據劃分為三份:訓練數據集、驗證數據集和測試數據集。它們的功能分別為
- 訓練數據集(train dataset):用來構建機器學習模型
- 驗證數據集(validation dataset):輔助構建模型,用于在構建過程中評估模型,為模型提供無偏估計,進而調整模型超參數
- 測試數據集(test dataset):用來評估訓練好的最終模型的性能
關于數據如何進行切分,后續再進行分享。
(3)特征工程
特征構建是指從原始數據中人工的找出一些具有物理意義的特征。需要花時間去觀察原始數據,思考問題的潛在形式和數據結構,對數據敏感性和機器學習實戰經驗能幫助特征構建。
關于機器學習,就先分享這些。歡迎大家繼續關注~
責任編輯:華軒
來源:
首席數據科學家