機器學習初學者入門實踐:怎樣輕松創造高精度分類網絡
這是一個為沒有人工智能背景的程序員提供的機器學習上手指南。使用神經網絡不需要博士學位,你也不需要成為實現人工智能下一個突破的人,你只需要使用現有的技術就行了——畢竟我們現在已經實現的東西已經很突破了,而且還非常有用。我認為我們越來越多的人將會和機器學習打交道就像我們之前越來越多地使用開源技術一樣——而不再僅僅將其看作是一個研究主題。在這份指南中,我們的目標是編寫一個可以進行高準確度預測的程序——僅使用圖像本身來分辨 data/untrained-samples 中程序未見過的樣本圖像中是海豚還是海馬。下面是兩張圖像樣本:
為了實現我們的目標,我們將訓練和應用一個卷積神經網絡(CNN)。我們將從實踐的角度來接近我們的目標,而不是闡釋其基本原理。目前人們對人工智能有很大的熱情,但其中很多都更像是讓物理學教授來教你自行車技巧,而不是讓公園里你的朋友來教你。
為此,我(GitHub 用戶 humphd/David Humphrey)決定在 GitHub 上寫下我的指南,而不是直接發在博客上,因為我知道我下面的寫的一切可能會有些誤導、天真或錯誤。我目前仍在自學,我發現現在還很缺乏可靠的初學者文檔。如果你覺得文章有錯誤或缺失了某些重要的細節,請發送一個 pull 請求。下面就讓我教你「自行車的技巧」吧!
指南地址:https://github.com/humphd
概述
我們將在這里探索以下內容:
- 設置和使用已有的、開源的機器學習技術,尤其是 Caffe 和 DIDITS
- 創建一個圖像數據集
- 從頭開始訓練一個神經網絡
- 在我們的神經網絡從未見過的圖像上對其進行測試
- 通過微調已有的神經網絡(AlexNet 和 GoogLeNet)來提升我們的神經網絡的準確度
- 部署和使用我們的神經網絡
問:我知道你說過我們不會談論神經網絡理論,但我覺得在我們開始動手之前至少應該來一點總體概述。我們應該從哪里開始?
對于神經網絡的理論問題,你能在網上找到海量的介紹文章——從短帖子到長篇論述到在線課程。根據你喜歡的學習形式,這里推薦了三個比較好的起點選擇:
J Alammar 的博客《A Visual and Interactive Guide to the Basics of Neural Networks》非常贊,使用直觀的案例介紹了神經網絡的概念:https://jalammar.github.io/visual-interactive-guide-basics-neural-networks/
Brandon Rohrer 的這個視頻是非常好的卷積神經網絡介紹:https://www.youtube.com/watch?v=FmpDIaiMIeA
如果你想了解更多理論上的知識,我推薦 Michael Nielsen 的在線書籍《Neural Networks and Deep Learning》:http://neuralnetworksanddeeplearning.com/index.html
設置
安裝 Caffe
Caffe 地址:http://caffe.berkeleyvision.org/
首先,我們要使用來自伯克利視覺和學習中心(Berkely Vision and Learning Center)的 Caffe 深度學習框架(BSD 授權)。
問:稍等一下,為什么選擇 Caffe?為什么不選現在人人都在談論的 TensorFlow?
沒錯,我們有很多選擇,你也應該了解一下所有的選項。TensorFlow 確實很棒,你也應該試一試。但是這里選擇 Caffe 是基于以下原因:
- 這是為計算機視覺問題定制的
- 支持 C++ 和 Python(即將支持 node.js:https://github.com/silklabs/node-caffe)(https://github.com/silklabs/node-caffe%EF%BC%89)
- 快速且穩定
但是我選擇 Caffe 的頭號原因是不需要寫任何代碼就能使用它。你可以聲明性地完成所有工作(Caffe 使用結構化的文本文件來定義網絡架構),并且也可以使用命令行工具。另外,你也可以為 Caffe 使用一些漂亮的前端,這能讓你的訓練和驗證過程簡單很多。基于同樣的原因,下面我們會選擇 NVIDIA 的 DIGITS。
Caffe 的安裝有點麻煩。這里有不同平臺的安裝說明,包括一些預構建的 Docker 或 AWS 配置:http://caffe.berkeleyvision.org/installation.html
注:當我在進行練習的時候,我使用了來自 GitHub 的尚未發布的 Caffe 版本:https://github.com/BVLC/caffe/commit/5a201dd960840c319cefd9fa9e2a40d2c76ddd73
在 Mac 要配置成功則難得多,這個版本有一些版本問題會在不同的步驟終止你的進度。我用了好幾天時間來試錯,我看了十幾個指南,每一個都有一些不同的問題。最后發現這個最為接近:https://gist.github.com/doctorpangloss/f8463bddce2a91b949639522ea1dcbe4。另外我還推薦:https://eddiesmo.wordpress.com/2016/12/20/how-to-set-up-caffe-environment-and-pycaffe-on-os-x-10-12-sierra/,這篇文章比較新而且鏈接了許多類似的討論。
到目前為止,安裝 Caffe 就是我們做的最難的事情,這相當不錯,因為你可能原來還以為人工智能方面會更難呢!
如果安裝遇到問題請不要放棄,痛苦是值得的。如果我會再來一次,我可能會使用一個 Ubuntu 虛擬機,而不是直接在 Mac 上安裝。如果你有問題要問,可以到 Caffe 用戶討論組:https://groups.google.com/forum/#!forum/caffe-users
問:我需要一個強大的硬件來訓練神經網絡嗎?要是我沒法獲取一個強大的 GPU 怎么辦?
是的,深度神經網絡確實需要大量的算力和能量……但那是在從頭開始訓練并且使用了巨型數據集的情況。我們不需要那么做。我們可以使用一個預訓練好的網絡(其它人已經為其投入了數百小時的計算和訓練),然后根據你的特定數據進行微調即可。我們后面會介紹如何實現這一目標,但首先我要向你說明:后面的一切工作都是在一臺沒有強大 GPU 的一年前的 MacBook 上完成的。
另外說明一點,因為我有一塊集成英特爾顯卡,而不是英偉達的 GPU,所以我決定使用 OpenCL Caffe 分支:https://github.com/BVLC/caffe/tree/opencl,它在我的筆記本電腦上效果良好!
當你安裝完 Caffe 之后,你應該有或能夠做下列事情:
- 一個包含了你構建的 Caffe 的目錄。如果你是按標準方式做的,應該會有一個 build/ 目錄包含了運行 Caffe 所需的一切、捆綁的 Python 等等,build/ 的父目錄將是你的 CAFFE_ROOT(后面我們會用到它)
- 運行 make test && make runtest,應該會通過
- 安裝了所有的 Python 依賴包之后(在 python/ 中執行 for req in $(cat requirements.txt); do pip install $req; done;運行 make pycaffe && make pytest 應該會通過
- 你也應該運行 make distribute 以在 distribute/ 中創建一個帶有所有必要的頭文件、二進制文件等的可分發的 Caffe 版本
在我的機器上,Caffe 完全構建后,我的 CAFFE_ROOT 目錄有以下基本布局:
- caffe/
- build/
- python/
- lib/
- tools/
- caffe ← this is our main binary
- distribute/
- python/
- lib/
- include/
- bin/
- proto/
到現在,我們有了訓練、測試和編程神經網絡所需的一切。下一節我們會為 Caffe 增加一個用戶友好的基于網頁的前端 DIGITS,這能讓我們對網絡的訓練和測試變得更加簡單。
安裝 DIGITS
DIGITS 地址:https://github.com/NVIDIA/DIGITS
英偉達的深度學習 GPU 訓練系統(Deep Learning GPU Training System/DIGITS)是一個用于訓練神經網絡的 BSD 授權的 Python 網頁應用。盡管我們可以在 Caffe 中用命令行或代碼做到 DIGITS 所能做到的一切,但使用 DIGITS 能讓我們的工作變得更加簡單。而且因為 DIGITS 有很好的可視化、實時圖表等圖形功能,我覺得使用它也能更有樂趣。因為你正在嘗試和探索學習,所以我強烈推薦你從 DIGITS 開始。
在 https://github.com/NVIDIA/DIGITS/tree/master/docs 有一些非常好的文檔,包括一些安裝、配置和啟動的頁面。我強烈建議你在繼續之前通讀一下。我并不是一個使用 DIGITS 的專家,如果有問題可以在公開的 DIGITS 用戶組查詢或詢問:https://groups.google.com/forum/#!forum/digits-users
安裝 DIGITS 的方式有很多種,從 Docker 到 Linux 上的 pre-baked package,或者你也可以從源代碼構建。我用的 Mac,所以我就是從源代碼構建的。
注:在我的實踐中,我使用了 GitHub 上未發布的 DIGITS 版本:https://github.com/NVIDIA/DIGITS/commit/81be5131821ade454eb47352477015d7c09753d9
因為 DIGITS 只是一些 Python 腳本,所以讓它們工作起來很簡單。在啟動服務器之前你要做的事情是設置一個環境變量,告訴 DIGITS 你的 CAFFE_ROOT 的位置在哪里:
- export CAFFE_ROOT=/path/to/caffe
- ./digits-devserver
注:在 Mac 上,這些服務器腳本出現了一些問題,可能是因為我的 Python 二進制文件叫做 python2,其中我只有 python2.7。
你可以在 /usr/bin 中 symlink 它或在你的系統上修改 DIGITS 啟動腳本以使用合適的二進制文件。
一旦服務器啟動,你可以在你的瀏覽器中通過 http://localhost:5000 來完成一切后續工作。
訓練一個神經網絡
訓練神經網絡涉及到幾個步驟:
1. 準備一個帶有分類圖像的數據集
2. 定義網絡架構
3. 使用準備好的數據集訓練和驗證這個網絡
下面我們會做這三個步驟,以體現從頭開始和使用預訓練的網絡之間的差異,同時也展示如何使用 Caffe 和 DIGITS 上最常用的兩個預訓練的網絡 AlexNet、 GoogLeNet。
對于我們的訓練,我們將使用一個海豚(Dolphins)和海馬(Seahorses)圖像的小數據集。這些圖像放置在 data/dolphins-and-seahorses。你至少需要兩個類別,可以更多(有些我們將使用的網絡在 1000 多個類別上進行了訓練)。我們的目標是:給我們的網絡展示一張圖像,它能告訴我們圖像中的是海豚還是海馬。
準備數據集
- dolphins-and-seahorses/
- dolphin/
- image_0001.jpg
- image_0002.jpg
- image_0003.jpg
- ...
- seahorse/
- image_0001.jpg
- image_0002.jpg
- image_0003.jpg
最簡單的開始方式就是將你的圖片按不同類別建立目錄:
在上圖中的每一個目錄都是按將要分類的類別建立的,所建文件夾目錄下是將以用于訓練和驗證的圖片。
問:所有待分類和驗證的圖片必須是同樣大小嗎?文件夾的命名有影響嗎?
回答都是「否」。圖片的大小會在圖片輸入神經網絡之前進行規范化處理,我們最終需要的圖片大小為 256×256 像素的彩色圖片,但是 DIGITS 可以很快地自動裁切或縮放(我們采用縮放)我們的圖像。文件夾的命名沒有任何影響——重要的是其所包含的圖片種類。
問:我能對這些類別做更精細的區分嗎?
當然可以。詳見 https://github.com/NVIDIA/DIGITS/blob/digits-4.0/docs/ImageFolderFormat.md。
我們要用這些圖片來創建一個新的數據集,準確的說是一個分類數據集(Classification Dataset)。
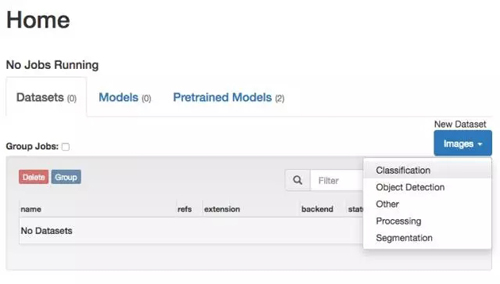
我們會使用 DIGITS 的默認設置,并把我們的訓練圖片文件路徑設置到 data/dolphins-and-seahorses 文件夾。如此一來,DIGITS 將會使用這些標簽(dolphin 和 seahorse)來創建一個圖像縮放過的數據集——圖片的大小將會是 256×256,其中 75% 的為訓練圖片,25% 的為測試圖片。
給你的數據集起一個名字,如 dolphins-and-seahorses,然后鼠標點擊創建(Create)。
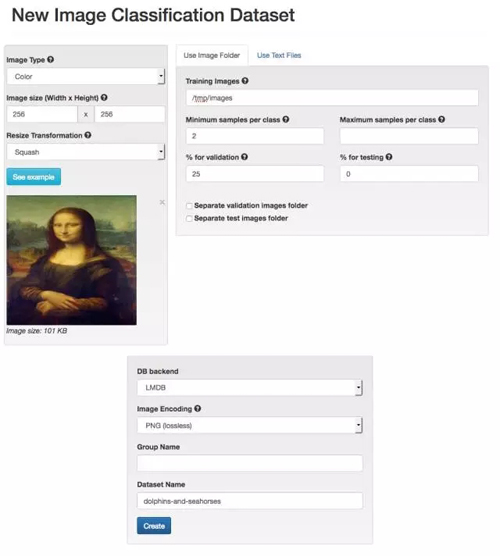
通過上面的步驟我們已經創建了一個數據集了,在我的筆記本上只需要 4 秒就可以完成。最終在所建的數據集里有 2 個類別的 92 張訓練圖片(其中 49 張 dolphin,43 張 seahorse),另外還有 30 張驗證圖片(16 張 dolphin 和 14 張 seahorse)。不得不說這的確是一個非常小的數據集,但是對我們的示范試驗和 DIGITS 操作學習來說已經足夠了,因為這樣網絡的訓練和驗證就不會用掉太長的時間了。
你可以在這個數據庫文件夾里查看壓縮之后的圖片。
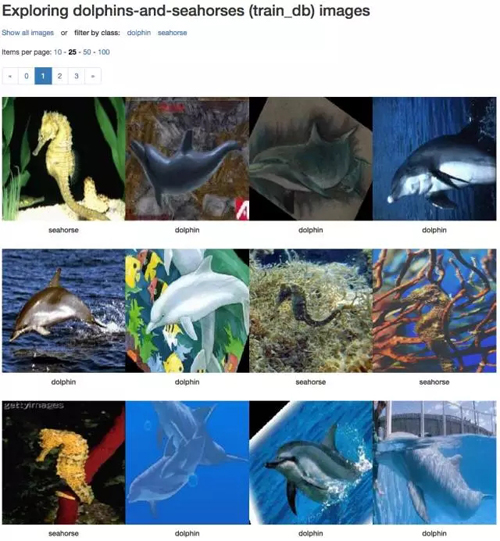
訓練嘗試 1:從頭開始
回到 DIGITS 的主頁,我們需要創建一個新的分類模型(Classification Model):
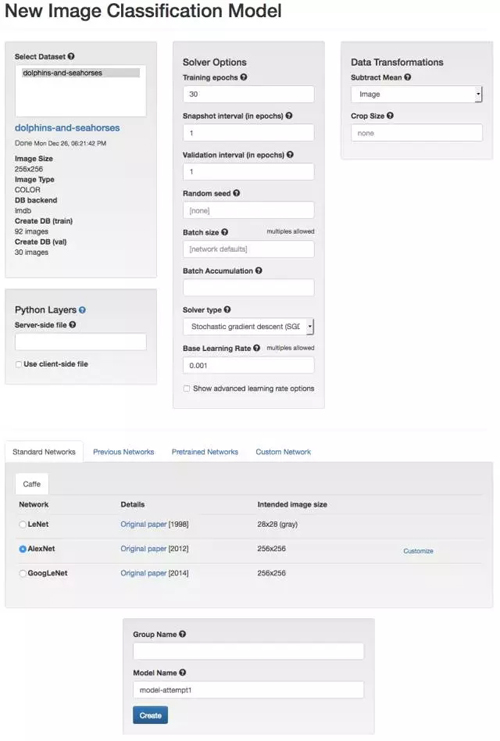
我們將開始用上一步所建立的 dolphins-and-seahorses 數據集來訓練模型,仍然使用 DIGITS 的默認設置。對于第一個神經網絡模型,我們可以從提供的神經網絡架構中選取一個既有的標準模型,即 AlexNet。AlexNet 的網絡結構在 2012 年的計算機視覺競賽 ImageNet 中獲勝過(ImageNet 為計算機視覺頂級比賽)。在 ImageNet 競賽里需要完成 120 萬張圖片中 1000 多類圖片的分類。
Caffe 使用結構化文本文件(structured text files)來定義網絡架構,其所使用的文本文件是基于谷歌的 Protocol Buffer。你可以閱讀 Caffe 采用的方案:https://github.com/BVLC/caffe/blob/master/src/caffe/proto/caffe.proto。其中大部分內容在這一部分的神經網絡訓練的時候都不會用到,但是了解這些構架對于使用者還是很有用的,因為在后面的步驟里我們將會對它們進行調整。AlexNet 的 prototxt 文件是這樣的,一個實例: https://github.com/BVLC/caffe/blob/master/models/bvlc_alexnet/train_val.prototxt。
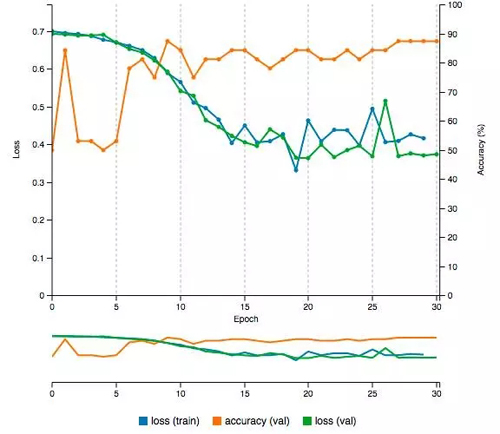
我們將會對這個神經網絡進行 30 次 epochs,這意味著網絡將會進行學習(運用我們的訓練圖片)并自行測試(運用我們的測試圖片),然后根據訓練的結果調整網絡中各項參數的權重值,如此重復 30 次。每一次 epoch 都會輸出一個分類準確值(Accuracy,介于 0% 到 100% 之間,當然值越大越好)和一個損失度(Loss,所有錯誤分類的比率,值越小越好)。理想的情況是我們希望所訓練的網絡能夠有較高的準確率(Accuracy)和較小的損失度(Loss)。
初始訓練的時候,所訓練網絡的準確率低于 50%。這是情理之中的,因為第一次 epoch,網絡只是在隨意猜測圖片的類別然后任意設置權重值。經過多次 epochs 之后,最后能夠有 87.5% 的準確率,和 0.37 的損失度。完成 30 次的 epochs 只需不到 6 分鐘的時間。
我們可以上傳一張圖片或者用一個 URL 地址的圖片來測試訓練完的網絡。我們來測試一些出現在我們訓練和測試數據集中的圖片:
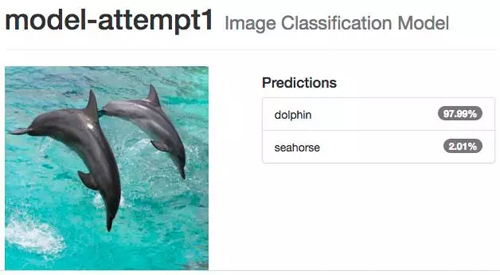

網絡的分類結果非常完美,當我們測試一些不屬于我們訓練和測試數據集的其他圖片時:
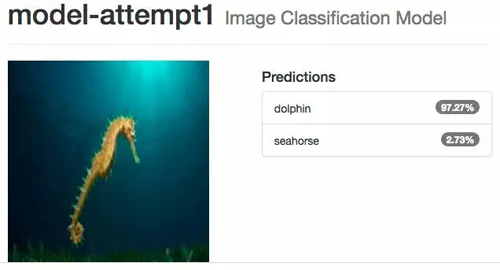
分類的準確率直接掉下來了,誤把 seahorse 分類為 dolphin,更糟糕的是網絡對這樣的錯誤分類有很高的置信度。
事實是我們的數據集太小了,根本無法用來訓練一個足夠好的神經網絡。我們需要數萬乃至數百萬張圖片才能訓練一個有用的神經網絡,用這么多的圖片也意味著需要很強勁的計算能力來完成所有的計算過程。
訓練嘗試 2:微調 AlexNet
怎么微調網絡
從頭設計一個神經網絡,收集足量的用以訓練這個網絡的數據(如,海量的圖片),并在 GPU 上運行數周來完成網絡的訓練,這些條件遠非我們大多數人可以擁有。能夠以更加實際——用較小一些的數據集來進行訓練,我們運用一個稱為遷移學習(Transfer Learning)或者說微調(Fine Tuning)的技術。Fine tuning 借助深度學習網絡的輸出,運用已訓練好的神經網絡來完成最初的目標識別。
試想使用神經網絡的過程就好比使用一個雙目望遠鏡看遠處的景物。那么當你第一次把雙目望遠鏡放到眼前的時候,你看到的是一片模糊。當你開始調焦的時候,你慢慢可以看出顏色、線、形狀,然后最終你可以分辨出鳥的外形,在此之上你進一步調試從而可以識別出鳥的種類。
在一個多層網絡中,最開始的幾層是用于特征提取的(如,邊線),之后的網絡層通過這些提取的特征來識別外形「shape」(如,一個輪子,一只眼睛),然后這些輸出將會輸入到最后的分類層,分類層將會根據之前所有層的特征積累來確定待分類目標的種類(如,判斷為貓還是狗)。一個神經網絡從像素、線形、眼睛、兩只眼睛的確定位置,這樣的步驟來一步步確立分類目標的種類(這里是貓)。
我們在這里所做的就是給新的分類圖片指定一個已訓練好的網絡用于初始化網絡的權重值,而不是用新構建網絡自己的初始權重。因為已訓練好的網絡已經具備「看」圖片特征的功能的,我們所需要的是這個已訓練的網絡能「看」我們所建圖片數據集——這一具體任務中特定類型的圖片。我們不需要從頭開始訓練大部分的網絡層——我們只需要將已訓練網絡中已經學習的層轉接到我們新建的分類任務上來。不同于我們的上一次的實驗,在上次實驗中網絡的初始權重值是隨機賦予的,這次實驗中我們直接使用已經訓練網絡的最終權重值作為我們新建網絡的初始權重值。但是,必須去除已經訓練好的網絡的最后分類層并用我們自己的圖片數據集再次訓練這個網絡,即在我們自己的圖片類上微調已訓練的網絡。
對于這次實驗,我們需要一個與經由與我們訓練數據足夠相似的數據集所訓練的網絡,只有這樣已訓練網絡的權重值才對我們有用。幸運的是,我們下面所使用的網絡是在海量數據集(自然圖片集 ImageNet)上訓練得到的,這樣的已訓練網絡能滿足大部分分類任務的需要。
這種技術已經被用來做一些很有意思的任務如醫學圖像的眼疾篩查,從海里收集到的顯微圖像中識別浮游生物物種,給 Flickr 上的圖片進行藝術風格分類。
完美的完成這些任務,就像所有的機器學習一樣,你需要很好的理解數據以及神經網絡結構——你必須對數據的過擬合格外小心,你或許需要調整一些層的設置,也很有可能需要插入一些新的網絡層,等等類似的調整。但是,我們的經驗表明大部分時候還是可以完成任務的「Just work」,而且用我們這么原始的方法去簡單嘗試一下看看結果如何是很值得的。
上傳預訓練網絡
在我們的第一次嘗試中,我們使用了 AlexNet 的架構,但是網絡各層的權重是隨機分布的。我們需要做的就是需要下載使用一個已經經過大量數據集訓練的 AlexNet。
AlexNet 的快照(Snapshots)如下,可供下載:https://github.com/BVLC/caffe/tree/master/models/bvlc_alexnet。我們需要一個二進制文件 .caffemodel,含有訓練好的權重,可供下載 http://dl.caffe.berkeleyvision.org/bvlc_alexnet.caffemodel。在你下載這些與訓練模型的時候,讓我們來趁機多學點東西。2014 年的 ImageNet 大賽中,谷歌利用其開源的 GoogLeNet (https://research.google.com/pubs/pub43022.html)(一個 22 層的神經網絡)贏得了比賽。GoogLeNet 的快照如下,可供下載: https://github.com/BVLC/caffe/tree/master/models/bvlc_googlenet。在具備了所有的預訓練權重之后,我們還需要.caffemodel 文件,可供下載:http://dl.caffe.berkeleyvision.org/bvlc_googlenet.caffemodel.
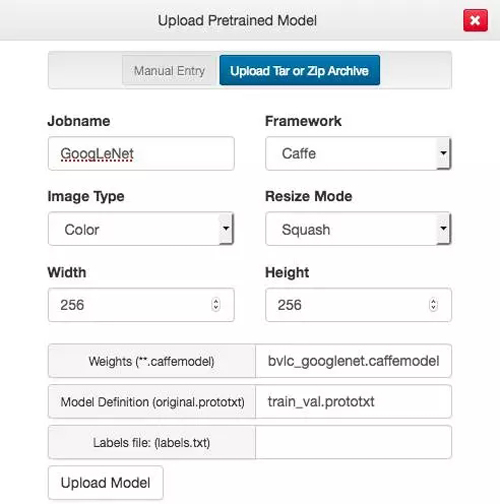
有了 .caffemodel 文件之后,我們既可以將它們上傳到 DIGITS 當中。在 DIGITS 的主頁當中找到預訓練模型(Pretrained Models)的標簽,選擇上傳預訓練模型(Upload Pretrained Model):
對于這些預訓練的模型,我們可以使用 DIGITS 的默認值(例如,大小為 256×256 像素的彩色圖片)。我們只需要提供 Weights (.caffemodel) 和 Model Definition (original.prototxt)。點擊這些按鈕來選擇文件。
模型的定義,GoogLeNet 我們可以使用 https://github.com/BVLC/caffe/blob/master/models/bvlc_googlenet/train_val.prototxt,AlexNet 可以使用 https://github.com/BVLC/caffe/blob/master/models/bvlc_alexnet/train_val.prototxt。我們不打算使用這些網絡的分類標簽,所以我們可以直接添加一個 labels.txt 文件:
在 AlexNet 和 GoogLeNet 都重復這一過程,因為我們在之后的步驟當中兩者我們都會用到。
問題:有其他的神經網絡能作為微調的基礎嗎?
回答:Caffe Model Zoo 有許多其他預訓練神經網絡可供使用,詳情請查看 https://github.com/BVLC/caffe/wiki/Model-Zoo
使用預訓練 Caffe 模型進行人工神經網絡訓練就類似于從頭開始實現,雖然我們只需要做一些調整。首先我們需要將學習速率由 0.01 調整到 0.001,因為我們下降步長不需要這么大(我們會進行微調)。我們還將使用預訓練網絡(Pretrained Network)并根據實際修改它。
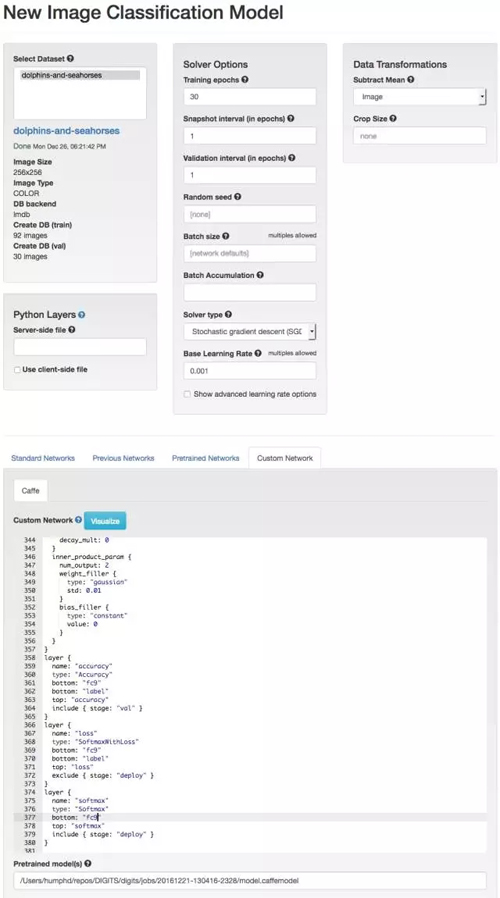
在預訓練模型的定義(如原文本)中,我們需要對最終完全連接層(輸出結果分類的地方)的所有 references 重命名。我們這樣做是因為我們希望模型能從現在的數據集重新學習新的分類,而不是使用以前最原始的訓練數據(我們想將當前最后一層丟棄)。我們必須將最后的全連接層由「fc8」重命名為一些其他的(如 fc9)。最后我們還需要將分類類別從 1000 調整為 2,這里需要調整 num_output 為 2。
下面是我們需要做的一些調整代碼:
- @@ -332,8 +332,8 @@
- }
- layer {- name: "fc8"+ name: "fc9"
- type: "InnerProduct"
- bottom: "fc7"- top: "fc8"+ top: "fc9"
- param {
- lr_mult: 1@@ -345,5 +345,5 @@
- }
- inner_product_param {- num_output: 1000+ num_output: 2
- weight_filler {
- type: "gaussian"@@ -359,5 +359,5 @@
- name: "accuracy"
- type: "Accuracy"- bottom: "fc8"+ bottom: "fc9"
- bottom: "label"
- top: "accuracy"@@ -367,5 +367,5 @@
- name: "loss"
- type: "SoftmaxWithLoss"- bottom: "fc8"+ bottom: "fc9"
- bottom: "label"
- top: "loss"@@ -375,5 +375,5 @@
- name: "softmax"
- type: "Softmax"- bottom: "fc8"+ bottom: "fc9"
- top: "softmax"
- include { stage: "deploy" }
我已經將所有的改進文件放在 src/alexnet-customized.prototxt 里面。
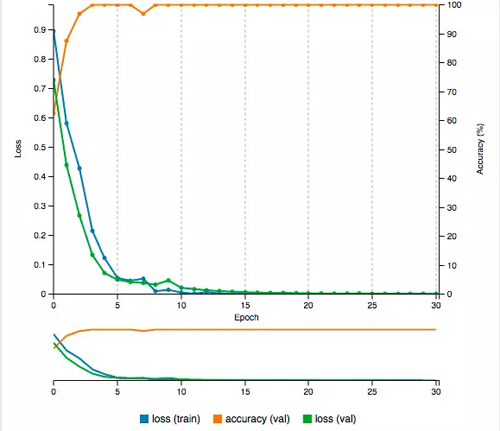
這一次,我們的準確率由 60% 多先是上升到 87.5%,然后到 96% 一路到 100%,同時損失度也穩步下降。五分鐘后,我們的準確率到達了 100%,損失也只有 0.0009。
測試海馬圖像時以前的網絡會出錯,現在我們看到完全相反的結果,即使是小孩畫的海馬,系統也 100% 確定是海馬,海豚的情況也一樣。
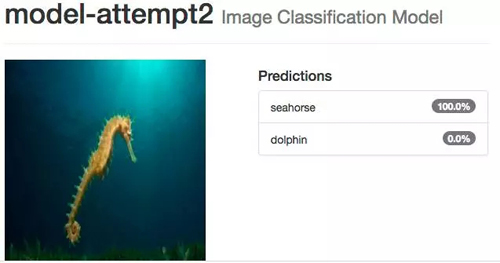
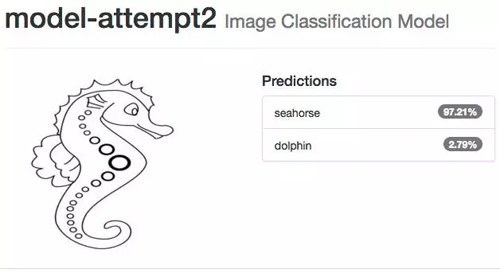
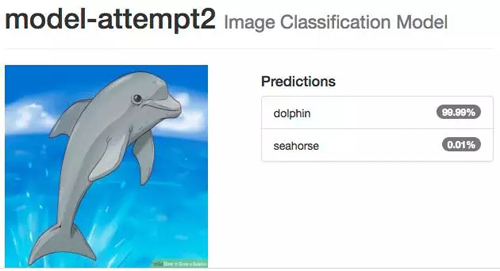
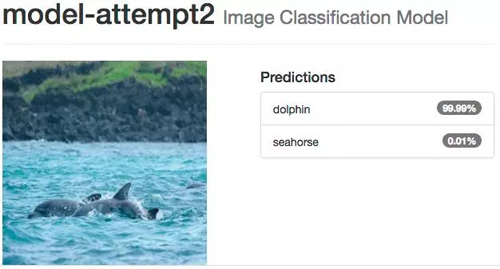
即使你認為可能很困難的圖像,如多個海豚擠在一起,并且它們的身體大部分在水下,系統還是能識別。
訓練嘗試 3:微調 GoogLeNet
像前面我們微調 AlexNet 模型那樣,同樣我們也能用 GoogLeNet。修改這個網絡會有點棘手,因為你已經定義了三層全連接層而不是只有一層
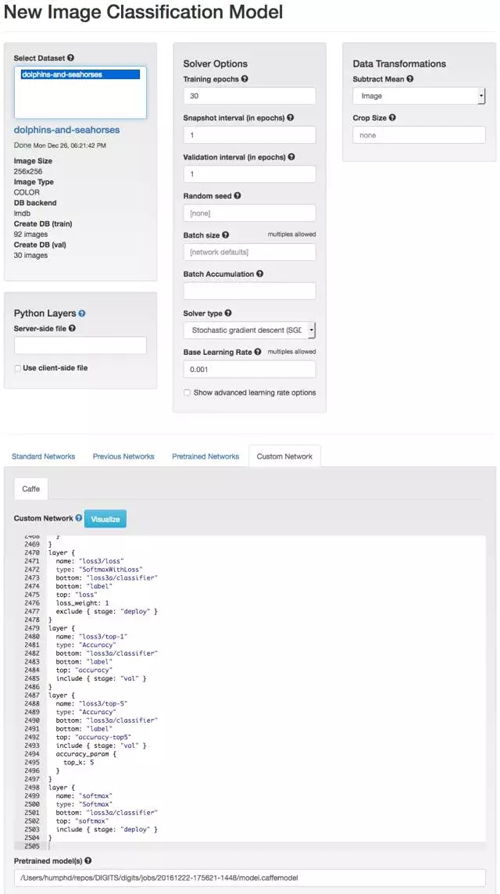
在這個案例中微調 GoogLeNet,我們需要再次創建一個新的分類模型:我們需要重命名三個全連接分類層的所有 references,即 loss1/classifier、loss2/classifier 和 loss3/classifier,并重新定義結果類別數(num_output: 2)。下面是我們需要將三個分類層重新命名和從 1000 改變輸出類別數為 2 的一些代碼實現。
- @@ -917,10 +917,10 @@
- exclude { stage: "deploy" }
- }
- layer {- name: "loss1/classifier"+ name: "loss1a/classifier"
- type: "InnerProduct"
- bottom: "loss1/fc"- top: "loss1/classifier"+ top: "loss1a/classifier"
- param {
- lr_mult: 1
- decay_mult: 1@@ -930,7 +930,7 @@
- decay_mult: 0
- }
- inner_product_param {- num_output: 1000+ num_output: 2
- weight_filler {
- type: "xavier"
- std: 0.0009765625@@ -945,7 +945,7 @@
- layer {
- name: "loss1/loss"
- type: "SoftmaxWithLoss"- bottom: "loss1/classifier"+ bottom: "loss1a/classifier"
- bottom: "label"
- top: "loss1/loss"
- loss_weight: 0.3@@ -954,7 +954,7 @@
- layer {
- name: "loss1/top-1"
- type: "Accuracy"- bottom: "loss1/classifier"+ bottom: "loss1a/classifier"
- bottom: "label"
- top: "loss1/accuracy"
- include { stage: "val" }@@ -962,7 +962,7 @@
- layer {
- name: "loss1/top-5"
- type: "Accuracy"- bottom: "loss1/classifier"+ bottom: "loss1a/classifier"
- bottom: "label"
- top: "loss1/accuracy-top5"
- include { stage: "val" }@@ -1705,10 +1705,10 @@
- exclude { stage: "deploy" }
- }
- layer {- name: "loss2/classifier"+ name: "loss2a/classifier"
- type: "InnerProduct"
- bottom: "loss2/fc"- top: "loss2/classifier"+ top: "loss2a/classifier"
- param {
- lr_mult: 1
- decay_mult: 1@@ -1718,7 +1718,7 @@
- decay_mult: 0
- }
- inner_product_param {- num_output: 1000+ num_output: 2
- weight_filler {
- type: "xavier"
- std: 0.0009765625@@ -1733,7 +1733,7 @@
- layer {
- name: "loss2/loss"
- type: "SoftmaxWithLoss"- bottom: "loss2/classifier"+ bottom: "loss2a/classifier"
- bottom: "label"
- top: "loss2/loss"
- loss_weight: 0.3@@ -1742,7 +1742,7 @@
- layer {
- name: "loss2/top-1"
- type: "Accuracy"- bottom: "loss2/classifier"+ bottom: "loss2a/classifier"
- bottom: "label"
- top: "loss2/accuracy"
- include { stage: "val" }@@ -1750,7 +1750,7 @@
- layer {
- name: "loss2/top-5"
- type: "Accuracy"- bottom: "loss2/classifier"+ bottom: "loss2a/classifier"
- bottom: "label"
- top: "loss2/accuracy-top5"
- include { stage: "val" }@@ -2435,10 +2435,10 @@
- }
- }
- layer {- name: "loss3/classifier"+ name: "loss3a/classifier"
- type: "InnerProduct"
- bottom: "pool5/7x7_s1"- top: "loss3/classifier"+ top: "loss3a/classifier"
- param {
- lr_mult: 1
- decay_mult: 1@@ -2448,7 +2448,7 @@
- decay_mult: 0
- }
- inner_product_param {- num_output: 1000+ num_output: 2
- weight_filler {
- type: "xavier"
- }@@ -2461,7 +2461,7 @@
- layer {
- name: "loss3/loss"
- type: "SoftmaxWithLoss"- bottom: "loss3/classifier"+ bottom: "loss3a/classifier"
- bottom: "label"
- top: "loss"
- loss_weight: 1@@ -2470,7 +2470,7 @@
- layer {
- name: "loss3/top-1"
- type: "Accuracy"- bottom: "loss3/classifier"+ bottom: "loss3a/classifier"
- bottom: "label"
- top: "accuracy"
- include { stage: "val" }@@ -2478,7 +2478,7 @@
- layer {
- name: "loss3/top-5"
- type: "Accuracy"- bottom: "loss3/classifier"+ bottom: "loss3a/classifier"
- bottom: "label"
- top: "accuracy-top5"
- include { stage: "val" }@@ -2489,7 +2489,7 @@
- layer {
- name: "softmax"
- type: "Softmax"- bottom: "loss3/classifier"+ bottom: "loss3a/classifier"
- top: "softmax"
- include { stage: "deploy" }
- }
我己經將完整的文件放在 src/googlenet-customized.prototxt 里面。
問題:這些神經網絡的原文本(prototext)定義需要做什么修改嗎?我們修改了全連接層名和輸出結果分類類別數,那么在什么情況下其它參數也能或也需要修改的?
回答:問得好,這也是我有一些疑惑的地方。例如,我知道我們能「固定」確切的神經網絡層級,并保證層級之間的權重不改變。但是要做其它的一些改變就涉及到理解我們的神經網絡層級是如何起作用的,這已經超出了這份入門向導的范圍,同樣也超出了這份向導作者現有的能力。
就像我們對 AlexNet 進行微調,將下降的學習速率由 0.01 減少十倍到 0.001 一樣。
問:還有什么修改是對這些網絡微調有意義的?遍歷所有數據的次數(numbers of epochs)不同怎么樣,改變批量梯度下降的大小(batch sizes)怎么樣,求解器的類型(Adam、 AdaDelta 和 AdaGrad 等)呢?還有下降學習速率、策略(Exponential Decay、Inverse Decay 和 Sigmoid Decay 等)、步長和 gamma 值呢?
問得好,這也是我有所疑惑的。我對這些只有一個模糊的理解,如果你知道在訓練中如何修改這些值,那么我們很可能做出些改進,并且這需要更好的文檔。
因為 GoogLeNet 比 AlexNet 有更復雜的網絡構架,所以微調需要更多的時間。在我的筆記本電腦上,用我們的數據集重新訓練 GoogLeNet 需要 10 分鐘,這樣才能實現 100% 的準確率,同時損失函數值只有 0.0070。
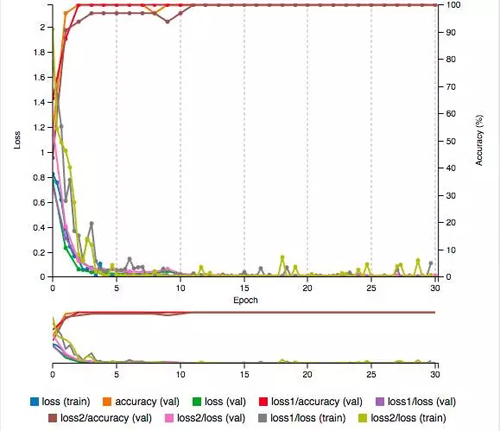
正如我們看到的 AlexNet 微調版本,我們修改過的 GoogLeNet 表現得十分驚人,是我們目前最好的。
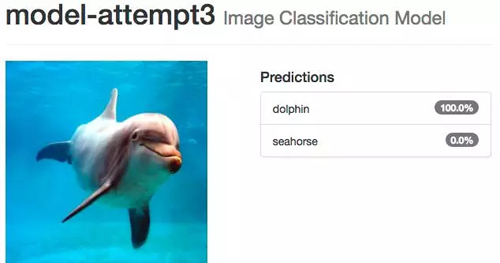
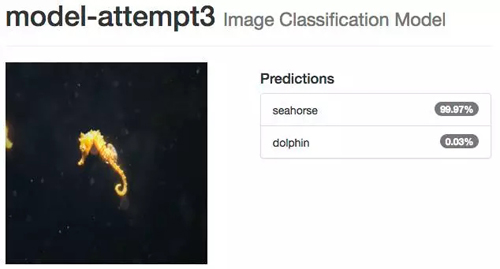
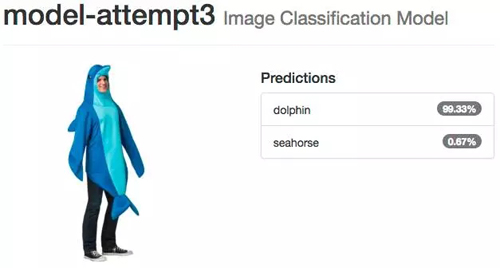
使用我們的模型
我們的網絡在訓練和檢測之后,就可以下載并且使用了。我們利用 DIGITS 訓練的每一個模型都有了一下載模型(Download Model)鍵,這也是我們在訓練過程中選擇不同 snapshots 的一種方法(例如 Epoch #30):
在點擊 Download Model 之后,你就會下載一個 tar.gz 的文檔,里面包含以下文件:
- deploy.prototxt
- mean.binaryproto
- solver.prototxt
- info.json
- original.prototxt
- labels.txt
- snapshot_iter_90.caffemodel
- train_val.prototxt
在 Caffe 文檔中對我們所建立的模型使用有一段非常好的描述。如下:
一個網絡是由其設計,也就是設計(prototxt)和權重(.caffemodel)決定。在網絡被訓練的過程中,網絡權重的當前狀態被存儲在一個.caffemodel 中。這些東西我們可以從訓練/檢測階段移到生產階段。在它的當前狀態中,網絡的設計并不是為了部署的目的。在我們可以將我們的網絡作為產品發布之前,我們通常需要通過幾種方法對它進行修改:
1. 移除用來訓練的數據層,因為在分類時,我們已經不再為數據提供標簽了。
2. 移除所有依賴于數據標簽的層。
3. 設置接收數據的網絡。
4. 讓網絡輸出結果。
DIGITS 已經為我們做了這些工作,它已經將我們 prototxt 文件中所有不同的版本都分離了出來。這些文檔我們在使用網絡時會用到:
- deploy.prototxt -是關于網絡的定義,準備接收圖像輸入數據
- mean.binaryproto - 我們的模型需要我們減去它處理的每張圖像的圖像均值,所產生的就是平均圖像(mean image)。
- labels.txt - 標簽列表 (dolphin, seahorse),以防我們想要把它們打印出來,否則只有類別編號。
- snapshot_iter_90.caffemodel -這些是我們網絡的訓練權重。
利用這些文件,我們可以通過多種方式對新的圖像進行分類。例如,在 CAFFE_ROOT 中,我們可以使用 build/examples/cpp_classification/classification.bin 來對一個圖像進行分類:
- $ cd $CAFFE_ROOT/build/examples/cpp_classification
- $ ./classification.bin deploy.prototxt snapshot_iter_90.caffemodel mean.binaryproto labels.txt dolphin1.jpg
這會產生很多的調試文本,后面會跟著對這兩種分類的預測結果:
- 0.9997 -「dolphin」
- 0.0003 -「seahorse」
你可以在這個 Caffe 案例中查看完整的 C++ 源碼:https://github.com/BVLC/caffe/tree/master/examples
使用 Python 界面和 DIGITS 進行分類的案例:https://github.com/NVIDIA/DIGITS/tree/master/examples/classification
最后,Caffe 的案例中還有一個非常好的 Python 演示:https://github.com/BVLC/caffe/blob/master/examples/00-classification.ipynb
我希望可以有更多更好的代碼案例、API 和預先建立的模型等呈現給大家。老實說,我找到的大多數代碼案例都非常的簡短,并且文檔介紹很少——Caffe 的文檔雖然有很多,但也有好有壞。對我來說,這似乎意味著會有人為初學者建立比 Caffe 更高級的工具。如果說在高級語言中出現了更加簡單的模型,我可以用我們的模型「做正確的事情」;應該有人將這樣的設想付諸行動,讓使用 Caffe 模型變得像使用 DIGITS 訓練它們一樣簡單。當然我們不需要對這個模型或是 Caffe 的內部了解那么多。雖然目前我還沒有使用過 DeepDetect,但是它看起來非常的有趣,另外仍然還有其他我不知道的工具。
結果
文章開頭提到,我們的目標是編寫一個使用神經網絡對 data/untrained-samples 中所有的圖像進行高準確度預測的程序。這些海豚和海馬的圖像是在訓練數據或是驗證數據時候從未使用過的。
未被訓練過的海豚圖像
未被訓練過的海馬圖像
接下來,讓我們一起來看看在這一挑戰當中存在的三次嘗試的結果:
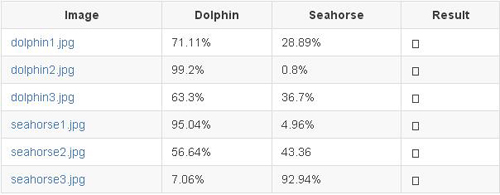
模型嘗試 1: 從零開始構建 AlexNet(第 3 位)
模型嘗試 2:微調 AlexNet(第 2 位)

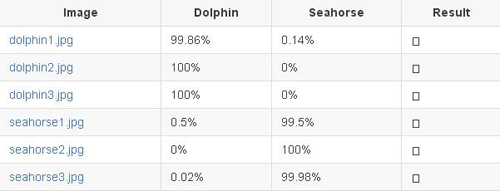
模型嘗試 3:微調 GoogLeNet(第 1 位)
結論
我們的模型運作非常好,這可能是通過調整一個預訓練的網絡完成的。很顯然,海豚 vs. 海馬的例子有一些牽強,數據集也非常的有限——如果我們想擁有一個強大的網絡,那我們確實需要更多、更好的數據。但因為我們的目標是去檢測神經網絡的工具和工作流程,所以這其實是一種很理想的情況,尤其是它不需要昂貴的設備或是花費大量的時間。
綜上所述,我希望這些經驗能夠讓那些一直對機器學習望而卻步的人擺脫對開始學習的恐懼。在你看到它的作用之后,再決定是否要在學習積極學習和神經網絡理論中投入時間要簡單很多。現在你已經對它的設置和工作方法都已經有所了解,之后你便可以嘗試去做一些分類。你也可以利用 Caffe 和 DIGITS 去做一些其他的事情,例如,在圖像中尋找物體,或是進行圖像分割。
【本文為51CTO專欄“機器之心”原創稿件,轉載請通過微信公眾號(ID:almosthuman2014)獲取授權】