什么是機器學習?
機器學習是人工智能(AI)的子集。它專注于訓練計算機,以從數據中學習并根據經驗進行改進,而不是為此進行顯式編程。在機器學習中,對算法進行訓練,以查找大型數據集中的模式和相關性,并根據該分析做出最佳決策和預測。機器學習應用程序會隨著使用而改進,并且隨著它們能夠訪問的數據越來越多而變得更加準確。機器學習的應用無處不在-在我們的家中,我們的購物車,我們的娛樂媒體和我們的醫療保健中。
人工智能和機器學習之間的關系圖
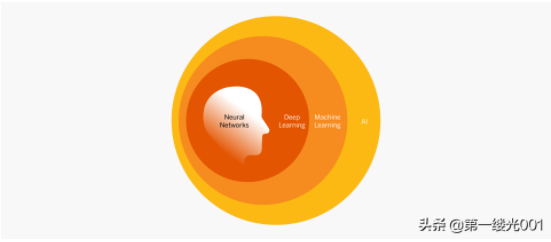
什么是神經網絡?
在生物大腦中的神經元上建立了一個人工神經網絡(ANN)。人工神經元稱為節點,并以多層形式聚集在一起,并并行運行。當人工神經元接收到數字信號時,它將對其進行處理并向與之連接的其他神經元發出信號。就像在人腦中一樣,神經強化可以改善模式識別,專業知識和整體學習能力。
什么是深度學習?
這種機器學習被稱為“深度學習”,因為它包括神經網絡的許多層以及大量復雜而分散的數據。為了實現深度學習,該系統與網絡中的多個層配合使用,提取出越來越高級的輸出。例如,用于處理自然圖像并尋找Gloriosa雛菊的深度學習系統將在第一層識別植物。當它在神經層中移動時,它將識別出花朵,然后是雛菊,最后是Gloriosa雛菊。深度學習應用的示例包括語音識別,圖像分類和藥物分析。
機器學習如何工作?
機器學習由使用各種算法技術的不同類型的機器學習模型組成。根據數據的性質和期望的結果,可以使用以下四種學習模型之一:有監督,無監督,半監督或增強。在每個模型中,相對于使用中的數據集和預期結果,可以應用一種或多種算法技術。機器學習算法的基本目的是對事物進行分類,查找模式,預測結果并做出明智的決策。當涉及復雜且更不可預測的數據時,可以一次使用一種算法,也可以組合使用這些算法以達到最佳的準確性。
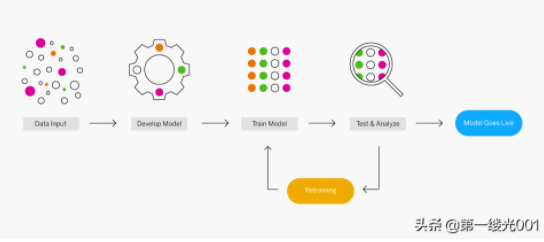
機器學習過程如何工作
什么是監督學習?
監督學習是四個機器學習模型中的第一個。在監督學習算法中,機器是通過示例進行教學的。監督學習模型由“輸入”和“輸出”數據對組成,其中輸出標記有所需的值。例如,假設目標是讓機器分辨雛菊和三色堇之間的區別。一個二進制輸入數據對包括一個雛菊圖像和一個三色堇圖像。該特定對的理想結果是選擇雛菊,因此它將被預先標識為正確的結果。
通過一種算法,系統會隨著時間的推移編譯所有這些訓練數據,并開始確定相關的相似性,差異和其他邏輯點-直到它可以完全自己預測雛菊或三色堇問題的答案為止。這相當于給孩子一個答案鍵來解決一系列問題,然后要求他們展示他們的工作并解釋他們的邏輯。我們每天與之交互的許多應用程序中都使用了監督學習模型,例如產品的推薦引擎和流量分析應用程序(例如Waze),它們預測了一天中不同時間的最快路線。
什么是無監督學習?
無監督學習是四種機器學習模型中的第二種。在無監督學習模型中,沒有答案鍵。機器研究輸入的數據(其中許多是未標記和非結構化的),并開始使用所有相關的可訪問數據來識別模式和相關性。在許多方面,無監督學習都以人類如何觀察世界為模型。我們使用直覺和經驗將事物組合在一起。隨著我們遇到越來越多的事物示例,我們對事物進行分類和識別的能力變得越來越準確。對于機器,“經驗”是由輸入的數據量和可用的數據量定義的。無監督學習應用的常見示例包括面部識別,基因序列分析,市場研究和網絡安全。
什么是半監督學習?
半監督學習是四種機器學習模型中的第三種。在理想情況下,所有數據在輸入到系統之前都將進行結構化和標記。但這顯然不可行,因此,當存在大量原始的,非結構化的數據時,半監督學習成為可行的解決方案。該模型包括輸入少量標記數據以擴充未標記數據集。從本質上講,標記的數據起著使系統運行的作用,并且可以大大提高學習速度和準確性。半監督學習算法指示機器分析標記數據的相關屬性,以將其應用于未標記數據。
正如本MIT Press研究論文中深入探討的那樣但是,存在與該模型相關的風險,其中標記的數據中的缺陷會被系統獲悉并復制。最成功地使用半監督學習的公司,請確保已制定最佳實踐協議。半監督學習用于語音和語言分析,復雜醫學研究(例如蛋白質分類)和高級欺詐檢測。
什么是強化學習?
強化學習是第四種機器學習模型。在監督學習中,機器會獲得答案鍵并通過查找所有正確結果之間的相關性來學習。強化學習模型不包括答案鍵,而是輸入一組允許的動作,規則和潛在的最終狀態。當算法的期望目標是固定的或二進制的時,機器可以通過示例學習。但是,在期望的結果是可變的情況下,系統必須通過經驗和獎勵來學習。在強化學習模型中,“獎勵”是數字,并作為系統尋求收集的內容編程到算法中。
在許多方面,該模型類似于教別人如何下棋。當然,不可能試圖向他們展示所有可能的舉動。取而代之的是,您解釋規則,然后它們通過實踐來增強技能。獎勵的形式不僅是贏得比賽,還包括獲得對手的棋子。強化學習的應用包括針對在線廣告,計算機游戲開發和高風險股票市場交易的買方的自動價格競標。
機器學習挑戰
數據科學家和哈佛大學畢業生泰勒·維甘(Tyler Vigan)在他的《虛假關聯》一書中指出:“并非所有的關聯都表明潛在的因果關系。” 為了說明這一點,他提供了一張圖表,顯示了人造黃油消費量與緬因州的離婚率之間很明顯的相關性。當然,此圖表旨在說明一個幽默點。但是,更重要的是,機器學習應用程序容易受到人為和算法偏見和錯誤的影響。而且由于其學習和適應的傾向,錯誤和虛假相關性可以在整個神經網絡中快速傳播和污染結果。