













Python 操作 MongoDB 基礎講解
MongoDB是一種面向文檔型的非關系型數據庫(NoSQL),非關系數據庫中是以鍵值對存儲,結構不固定,易存儲,減少時間和空間的開銷。
文檔型數據庫通常是以JSON或XML格式存儲數據,而Mongodb使用的數據結構是BSON,即二進制JSON。和JSON相比,BSON提高了存儲和掃描效率,但空間占用會更多一些。
本文默認已經安裝了MongoDB服務器,著重介紹Python操作MongoDB的庫PyMongo,在命令行中輸入如下內容安裝:
- # Windows
- pip install pymongo
- # Mac
- pip3 install pymongo
一、連接服務器
連接服務器需要提供一個地址和接口
- import pymongo
- client = pymongo.MongoClient(host='localhost', 27017)
- # 地址和端口也可以用一個字符串完成
- client = pymongo.MongoClient('mongodb://localhost:27017/')
27017 是默認端口。如果設置過密碼進行連接就不能簡單使用上面的代碼了,需要在代碼中帶上密碼:
- import pymongo
- client = pymongo.MongoClient(host='localhost', 27017)
- auth = mongo_client.admin
- auth.authenticate('用戶名', '密碼')
連接服務器可以用下面的代碼判斷是否成功:
- print(client.server_info())
二、獲取數據庫
獲取數據庫有以下兩種表述方法(以數據庫 data 為例):
- # 方法一
- db = client['data']
- # 方法二
- db = client.data
另外需要說明,MongoDB不需要提前創建好數據庫,而是直接使用,如果發現沒有則自動創建一個 testdb 的數據庫:
- db = client.testdb
三、獲取集合
非關系型數據庫中的集合類似于關系型數據庫中的表獲取集合與獲取數據庫類似,同樣有兩種方法(以集合 practice 為例):
- collection = db['practice']
- # 方法二
- collection = db.practice
四、插入數據
下面的操作進行前默認已經通過代碼獲取到了 practice 集合:
- import pymongo
- client = pymongo.MongoClient(host='localhost', 27017)
- db = client.data
- collection = db.practice
4.1 插入單條數據
數據形式是字典,可以通過 insert_one 完成單個數據的寫入:
- data = {
- 'name' : 'Chenxi',
- 'text' : 'Hello World',
- 'tags' : ['a', 'b', 'c']
- }
- collection.insert_one(data)
在MongoDB中,每條數據都有_id屬性來唯一標識。可以輸出返回的id確認數據情況:
- result = collection.insert_one(data)
- print(result.inserted_id)
4.2 插入多條數據
如果有多條數據,每條數據形式依然是字典,但需要組合成字典列表的形式后用 insert_many() 完成寫入:
- data1 = {
- 'name' : 'Chenxi',
- 'text' : 'Hello World',
- 'tags' : ['a', 'b', 'c']
- }
- data2 = {
- 'name' : 'Zaoqi',
- 'text' : 'Hello World',
- 'tags' : ['a', 'b', 'c']
- }
- collection.insert_many([data1, data2])
五、刪除數據
5.1 刪除單條數據
刪除一條數據。若刪除條件相同匹配到多條數據,默認刪除第一條。如上例中插入的兩條數據均符合 {'text' : 'Hello World'} 那么通過 delete_one 會刪除第一條數據,保留 {'name' : 'Zaoqi'} 這條數據:
- collection.delete_one({'text' : 'Hello World'})
5.2 刪除多條數據
刪除滿足條件的所有數據。如上例中插入的兩條數據均符合 {'text' : 'Hello World'} 那么通過 delete_many 會刪除全部兩條數據:
- collection.delete_many({'text' : 'Hello World'})
六、更新數據
6.1 更新單條數據
類似刪除單條數據,只會更新滿足條件的第一條數據。代碼為 update_one(filter,update,upsert=False),其中第一個參數 filter為更新的條件,第二個參數 update 為更新的內容,第三個參數 upsert 默認 False, 若為 True 則當更新條件沒找到時會插入更新的內容
- data3 = {
- 'name': 'Xiaoming',
- 'text': 'Goodbye World',
- 'tags': [1, 2, 3]
- }
- update_condition = {'name' : 'Chenxi'}
- collection.update_one(update_condition, {'$set' : data3})
6.2 更新多條數據
有了上面刪除和插入多條數據的認識,就很好理解更新多條數據的邏輯了,同理也是更新符合條件的全部數據。
- data3 = {
- 'name': 'Xiaoming',
- 'text': 'Goodbye World',
- 'tags': [1, 2, 3]
- }
- update_condition = {'text' : 'Hello World'}
- collection.update_many(update_condition, {'$set' : data3})
七、查詢數據
7.1 查詢單條數據
匹配第一條滿足的條件的結果,這條結果以字典形式返回,若沒有查詢到,則返回 None
- find_result = collection.find_one({'text' : 'Hello World'})
- print(find_result)
可以通過 projection 參數來指定需要查詢的字段:
- find_result = collection.find_one({'text' : 'Hello World'}, projection= {'_id':False, 'name':True, 'tags':False})
- print(find_result)
7.2 查詢多條數據
返回滿足條件的所有結果,返回后需要通過迭代獲取每個查詢結果,每個結果類型為字典。和之前的增、刪、改不類似,查詢多條為 find()
- find_result = collection.find({'text' : 'Hello World'})
- for i in find_result:
- print(i)
7.3 查詢且刪除
代碼為 find_one_and_delete(filter,projection=None,sort=None,session=None,**kwargs),其中 sort為元祖列表類型,當查詢匹配到多條數據時,根據某個條件排序,函數返回時返回第一條數據:
- find_condition = {'text' : 'Hello World'}
- deleted_item = collection.find_one_and_delete(find_condition, sort= [('name', pymongo.DESCENDING)])
- print(deleted_item)
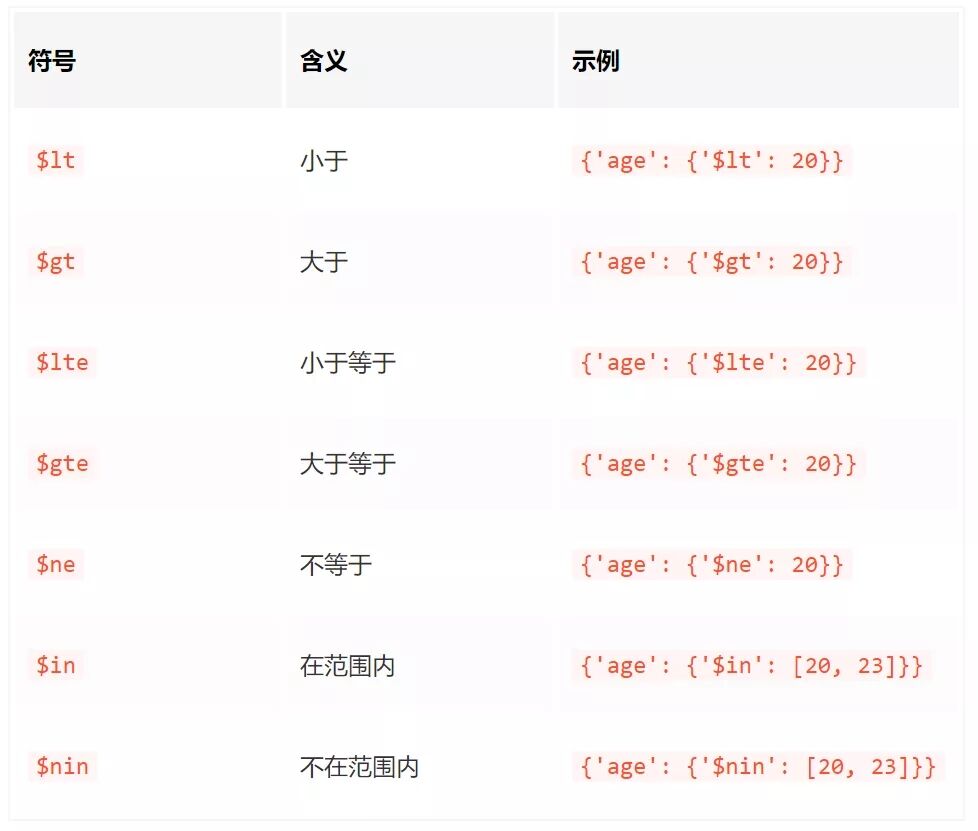
查詢也可以通過 $ 限定查詢范圍,常用內容如下:
img
八、計數
要統計查詢結果有多少條數據,可以調用 count() 方法。具體操作如下:
- count = collection.find({'text' : 'Hello World'}).count()
- print(count)
九、排序
查詢中已經看到 sort 可以作為參數發揮排序作用。實際上 sort 可以類似計數方法一樣直接跟在查詢的后面:
- results = collection.find({'text' : 'Hello World'}).sort('name', pymongo.ASCENDING)
- print([result['name'] for result in results])
十、索引
10.1 創建索引
在插入數據時,已經有一個 _id 索引了,但我們還可以自定義創建索引:
- collection.create_index('name', unique= True)
10.2 獲取索引信息
可以利用 index_information 獲取索引介紹:
- index_info = collection.index_information()
- print(index_info)
10.3 刪除索引
- del_index = collection.drop_index(index_name)
以上就是一些 Python 操作 MongoDB的基本用法,更多關于 PyMongo 的詳細用法,可以自行查閱官方文檔。











