小技巧:如何在Linux上從圖像和PDF中提取文本
gImageReader是Tesseract開源OCR引擎的前端。Tesseract最初是由HP開發的,然后于2006年開源。
基本上,OCR(Optical Character Recognition光學字符識別)引擎使您可以掃描圖片或文件(PDF)中的文本。默認情況下,它可以檢測多種語言,并且還支持通過Unicode字符進行掃描。
但是,Tesseract本身就是沒有任何GUI的命令行工具。因此,在這里,gImageReader可以幫助任何用戶利用它來從圖像和文件中提取文本。
讓我重點介紹一些有關它的內容,同時提及我在測試期間的使用經驗。
gImageReader:Tesseract OCR的跨平臺前端
為了簡化工作,gImageReader可以方便地從PDF文件或包含任何類型文本的圖像中提取文本。
無論是拼寫檢查還是翻譯都需要它,它對于特定的用戶組應該很有用。
gImageReader功能介紹:
- 從磁盤,掃描設備,剪貼板和屏幕截圖添加PDF文檔和圖像
- 旋轉圖像的能力
- 通用圖像控件可調節亮度,對比度和分辨率
- 直接通過應用程序掃描圖像
- 能夠一次處理多個圖像或文件
- 手動或自動識別區域定義
- 識別純文本或hOCR文檔
- 編輯器顯示識別的文本
- 可以拼寫檢查提取的文本
- 從hOCR文檔轉換/導出為PDF文檔
- 將提取的文本導出為.txt文件
- 跨平臺(Windows)
在Linux上安裝gImageReader
注意:您需要顯式安裝Tesseract語言包以從軟件管理器中的圖像/文件中進行檢測。
您可以在某些Linux發行版(例如Fedora和Debian)的默認存儲庫中找到gImageReader。
對于Ubuntu,您需要添加一個PPA,然后再安裝它。為此,您需要在終端中輸入以下內容:
- linuxmi@linuxmi:~/www.linuxmi.com$ sudo add-apt-repository ppa:sandromani/gimagereader
- linuxmi@linuxmi:~/www.linuxmi.com$ sudo apt update
- linuxmi@linuxmi:~/www.linuxmi.com$ sudo apt install gimagereader tesseract-ocr tesseract-ocr-eng tesseract-ocr-chi-sim tesseract-ocr-chi-tra -y
- linuxmi@linuxmi:~/www.linuxmi.com$ sudo apt install tesseract-ocr-chi-sim-vert tesseract-ocr-chi-tra-vert -y
您還可以從其構建服務中為openSUSE找到它,AUR將成為Arch Linux用戶的地方。
到存儲庫和軟件包的所有鏈接都可以在其GitHub頁面中找到。
使用gImageReader的經驗
gImageReader是一個非常有用的工具,可以在需要時從圖像中提取文本。當您嘗試使用PDF文件時,它的效果很好。
為了從智能手機拍攝的照片中提取圖像,檢測很接近,但是有點不準確。也許當您掃描某些內容時,從文件中識別字符可能會更好。
因此,您必須自己嘗試一下,看看它在您的用例中的效果如何。我在Ubuntu 20.04.2 LTS上進行了嘗試。
操作步驟
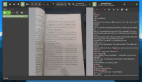
打開 gImageReader
添加pdf
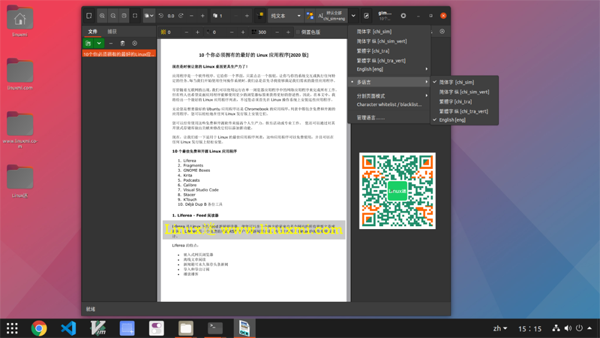
識別語言選擇 多種語言 ==> 簡體字[chi_sim]+ English[eng]
復制或保存識別文本
操作結果參照下圖:
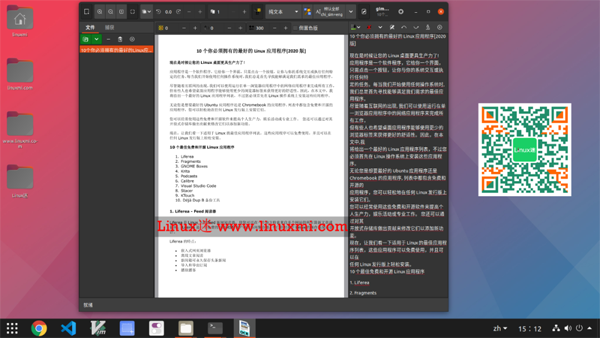
我只是在管理設置中的語言時遇到了一個問題,但沒有得到快速的解決方案。如果遇到此問題,則可能需要對其進行故障排除,并進一步了解如何解決該問題。
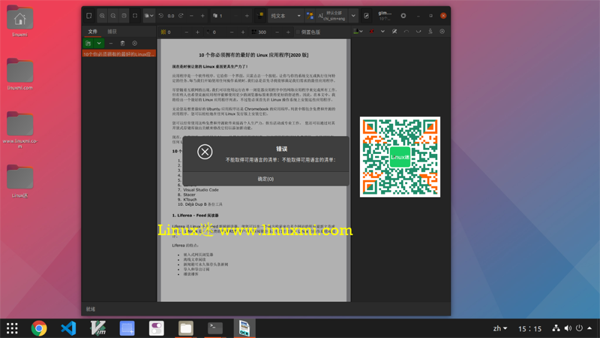
除此之外,它工作得很好。
永久鏈接:https://www.linuxmi.com/linux-ocr-gimagereader-pdf.html