從PDF和圖像中提取文本,以供大型語言模型使用
想法
大型語言模型已經席卷了互聯網,導致更多的人沒有認真關注使用這些模型最重要的部分:高質量的數據!本文旨在提供一些有效從任何類型文檔中提取文本的技術。

Python庫
本文專注于Pytesseract、easyOCR、PyPDF2和LangChain庫。實驗數據是一個單頁PDF文件,可在以下鏈接獲取:
https://github.com/keitazoumana/Experimentation-Data/blob/main/Experimentation_file.pdf
由于Pytesseract和easyOCR可以處理圖像,因此在執行內容提取之前需要將PDF文件轉換為圖像。可以使用pypdfium2進行轉換,這是一個用于處理PDF文件的強大庫,其實現如下:
pip install pypdfium2以下函數以PDF作為輸入,并將PDF的每一頁作為圖像列表返回。
def convert_pdf_to_images(file_path, scale=300/72):
pdf_file = pdfium.PdfDocument(file_path)
page_indices = [i for i in range(len(pdf_file))]
renderer = pdf_file.render(
pdfium.PdfBitmap.to_pil,
page_indices = page_indices,
scale = scale,
)
final_images = []
for i, image in zip(page_indices, renderer):
image_byte_array = BytesIO()
image.save(image_byte_array, format='jpeg', optimize=True)
image_byte_array = image_byte_array.getvalue()
final_images.append(dict({i:image_byte_array}))
return final_images現在,我們可以使用display_images函數來可視化PDF文件的所有頁面。
def display_images(list_dict_final_images):
all_images = [list(data.values())[0] for data in list_dict_final_images]
for index, image_bytes in enumerate(all_images):
image = Image.open(BytesIO(image_bytes))
figure = plt.figure(figsize = (image.width / 100, image.height / 100))
plt.title(f"----- Page Number {index+1} -----")
plt.imshow(image)
plt.axis("off")
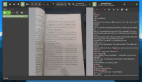
plt.show()通過組合上述兩個函數,我們可以得到以下結果:
convert_pdf_to_images = convert_pdf_to_images('Experimentation_file.pdf')
display_images(convert_pdf_to_images)
圖片PDF以圖像格式可視化
深入文本提取過程
1.Pytesseract
Pytesseract(Python-tesseract)是用于從圖像中提取文本信息的Python OCR工具,可以使用以下pip命令進行安裝:
pip install pytesseract以下的輔助函數使用了 Pytesseract 的 image_to_string() 函數從輸入圖像中提取文本。
from pytesseract import image_to_string
def extract_text_with_pytesseract(list_dict_final_images):
image_list = [list(data.values())[0] for data in list_dict_final_images]
image_content = []
for index, image_bytes in enumerate(image_list):
image = Image.open(BytesIO(image_bytes))
raw_text = str(image_to_string(image))
image_content.append(raw_text)
return "\n".join(image_content)可以使用 extract_text_with_pytesseract 函數提取文本,如下所示:
text_with_pytesseract = extract_text_with_pytesseract(convert_pdf_to_images)
print(text_with_pytesseract)成功執行以上代碼將生成以下結果:
This document provides a quick summary of some of Zoumana’s article on Medium.
It can be considered as the compilation of his 80+ articles about Data Science, Machine Learning and
Machine Learning Operations.
...
Pytesseract was able to extract the content of the image.
Here is how it managed to do it!
Pytesseract starts by identifying rectangular shapes within the input image from top-right to bottom-right. Then it extracts the content of the individual images, and the final result is the concatenation of those extracted content. This approach works perfectly when dealing with column-based PDFs and image documents.
...Pytesseract 首先通過從圖像的右上角到右下角識別矩形形狀。然后它提取各個圖像的內容,最終的結果是這些提取內容的串聯。這種方法在處理基于列的 PDF 和圖像文檔時效果非常好。
2.easyOCR
easyOCR 也是一個用于光學字符識別的開源 Python 庫,目前支持提取 80 多種語言的文本。easyOCR需要安裝Pytorch 和 OpenCV,可以使用以下指令安裝:
!pip install opencv-python-headless==4.1.2.30根據您的操作系統,安裝 Pytorch 模塊的方法可能不同。但所有的說明都可以在官方頁面上找到。現在我們來安裝 easyOCR 庫:
!pip install easyocr在使用 easyOCR 時,因為它支持多語言,所以在處理文檔時需要指定語言。通過其 Reader 模塊設置語言,指定語言列表。例如,fr 用于法語,en 用于英語。語言的詳細列表在此處可用。
from easyocr import Reader
# Load model for the English language
language_reader = Reader(["en"])文本提取過程在extract_text_with_easyocr 函數中實現:
def extract_text_with_easyocr(list_dict_final_images):
image_list = [list(data.values())[0] for data in list_dict_final_images]
image_content = []
for index, image_bytes in enumerate(image_list):
image = Image.open(BytesIO(image_bytes))
raw_text = language_reader.readtext(image)
raw_text = " ".join([res[1] for res in raw_text])
image_content.append(raw_text)
return "\n".join(image_content)我們可以如下執行上述函數:
text_with_easy_ocr = extract_text_with_easyocr(convert_pdf_to_images)
print(text_with_easy_ocr)
easyOCR 的結果
與 Pytesseract 相比,easyOCR 的效果似乎不太高效。例如,它能夠有效地讀取前兩個段落。然而,它不是將每個文本塊視為獨立的文本,而是使用基于行的方法進行讀取。例如,第一個文本塊中的字符串“Data Science section covers basic to advanced”已與第二個文本塊中的“overfitting when training computer vision”組合在一起,這種組合完全破壞了文本的結構并使最終結果產生偏差。
3.PyPDF2
PyPDF2 也是一個專門用于 PDF 處理任務的 Python 庫,例如文本和元數據的檢索、合并、裁剪等。
!pip install PyPDF2提取邏輯實現在 extract_text_with_pyPDF 函數中:
def extract_text_with_pyPDF(PDF_File):
pdf_reader = PdfReader(PDF_File)
raw_text = ''
for i, page in enumerate(pdf_reader.pages):
text = page.extract_text()
if text:
raw_text += text
return raw_text
text_with_pyPDF = extract_text_with_pyPDF("Experimentation_file.pdf")
print(text_with_pyPDF)
使用 PyPDF 庫進行文本提取
提取過程快速而準確,甚至保留了原始字體大小。PyPDF 的主要問題是它不能有效地從圖像中提取文本。
4.LangChain
LangChain 的 UnstructuredImageLoader 和 UnstructuredFileLoader 模塊可分別用于從圖像和文本/PDF 文件中提取文本,并且在本節中將探討這兩個選項。
首先,我們需要按照以下方式安裝 langchain 庫:
!pip install langchain(1) 從圖像中提取文本
from langchain.document_loaders.image import UnstructuredImageLoader以下是提取文本的函數:
def extract_text_with_langchain_image(list_dict_final_images):
image_list = [list(data.values())[0] for data in list_dict_final_images]
image_content = []
for index, image_bytes in enumerate(image_list):
image = Image.open(BytesIO(image_bytes))
loader = UnstructuredImageLoader(image)
data = loader.load()
raw_text = data[index].page_content
image_content.append(raw_text)
return "\n".join(image_content)現在,我們可以提取內容:
text_with_langchain_image = extract_text_with_langchain_image(convert_pdf_to_images)
print(text_with_langchain_image)
來自 langchain UnstructuredImageLoader 的文本提取。
該庫成功高效地提取了圖像的內容。
(2) 從 PDF 中提取文本
以下是從 PDF 中提取內容的實現:
from langchain.document_loaders import UnstructuredFileLoader
def extract_text_with_langchain_pdf(pdf_file):
loader = UnstructuredFileLoader(pdf_file)
documents = loader.load()
pdf_pages_content = '\n'.join(doc.page_content for doc in documents)
return pdf_pages_content
text_with_langchain_files = extract_text_with_langchain_pdf("Experimentation_file.pdf")
print(text_with_langchain_files)類似于 PyPDF 模塊,langchain 模塊能夠生成準確的結果,同時保持原始字體大小。

從 langchain 的 UnstructuredFileLoader 中提取文本。