分布式系統的 CAP 定理與 BASE 理論
本文轉載自微信公眾號「碼農私房話」,作者GoQeng。轉載本文請聯系碼農私房話公眾號。
最近在總結之前面試騰訊財付通考察注冊中心的知識點,但寫著寫著發現有很多功能點需要基礎理論鋪墊,因此決定先總結分布式系統中常用的理論,方便后續對面試考察點的理解。
什么是 CAP ?
CAP 理論作為分布式系統的基礎理論,它描述的是一個分布式系統在以下三個特性中:
- 一致性(Consistency)
- 可用性(Availability)
- 分區容錯性(Partition Tolerance)
最多滿足其中的兩個特性,也就是下圖所描述的:分布式系統要么滿足 CA,要么 CP,要么 AP,而無法同時滿足 CAP。
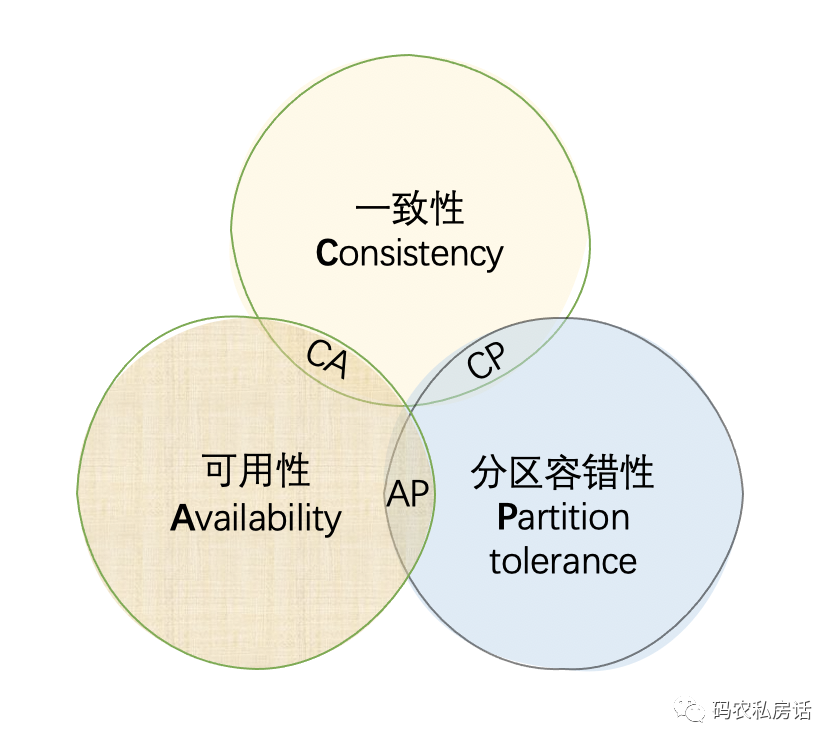
分區容錯性:指分布式系統中的某個節點或網絡分區出現了故障時,整個系統仍然能對外提供滿足一致性和可用性的服務,也就是說部分故障不影響整體使用。
可用性:系統一直可以正常地做讀寫操作,簡單而言就是客戶端一直可以正常訪問并得到系統的正常響應,從用戶角度來看是不會出現系統操作失敗或者訪問超時等問題。
一致性:在分布式系統完成某寫操作后任何讀操作,都應該獲取到該寫操作寫入的那個最新的值。相當于要求分布式系統中的各節點時時刻刻保持數據的一致性。
如何理解 CAP ?
首先在保證了分區容錯性的前提下,意味著若某個節點故障了,用戶還可以繼續訪問,但這時用戶在訪問過程中就會出現一致性和可用性不能同時滿足的情況,如下圖:
情景一:

假設分布式系統有 S0、S1 兩個節點,節點中的變量初始值都是 v0,現在有一個客戶端向系統寫入了新值 v1,這里假設直接寫的是節點 S0,寫完之后客戶端再去讀取這個值,但此時讀到了 S1 節點的。
由于 S1 節點與 S0 節點失去通信,此時 S0 節點的數據還未同步到 S1 節點,因此客戶端讀取到的是舊的值 v0,這就出現不滿足一致性的情況,即滿足了可用性,失去了一致性。
情景二:
類似的,如果系統保證了強一致性,那么在客戶端往 S0 節點寫完數據后,S0 向 S1 節點同步數據出現了問題,此時如果客戶端再去讀取 S1 節點的數據,客戶端就會一直處于等待狀態,因為系統各節點的數據未同步完,需要等同步完才能使用,即滿足了一致性,而失去了可用性。

情景三:
當多個客戶端訪問的情況時,一致性與可用性可這么理解:假設客戶端1 向 S0 修改某個值的時候, 寫操作還未完成,客戶端2就發起來對該值的讀操作,但讀取的是 S1 節點的值,這時如果要滿足一致性,就得讓客戶端1暫時無法使用,如果要讓客戶端2可使用,那么獲取的數據不是最新的,系統就不滿足一致性。
CAP 三者不可得兼,如何取舍 ?
CA:優先保證一致性和可用性,放棄分區容錯。這也意味著放棄系統的擴展性,系統不再是分布式的,有違設計的初衷。
CP:優先保證一致性和分區容錯性,放棄可用性。在數據一致性要求比較高的場合,例如:Zookeeper、Hbase 等是比較常見的做法,一旦發生網絡故障或者消息丟失,就會犧牲用戶體驗,等恢復之后用戶才逐漸能訪問。
AP:優先保證可用性和分區容錯性,放棄一致性。在 Spring Cloud 體系中使用的 Eureka 注冊中心就是這種架構,但放棄一致性只是指放棄強一致性,保證最終一致性。
什么是 BASE 理論 ?
BASE 全稱是 Basically Available(基本可用)、Soft State(軟狀態)和 Eventually Consistent(最終一致性)三個短語的縮寫,來自 ebay 的架構師提出。
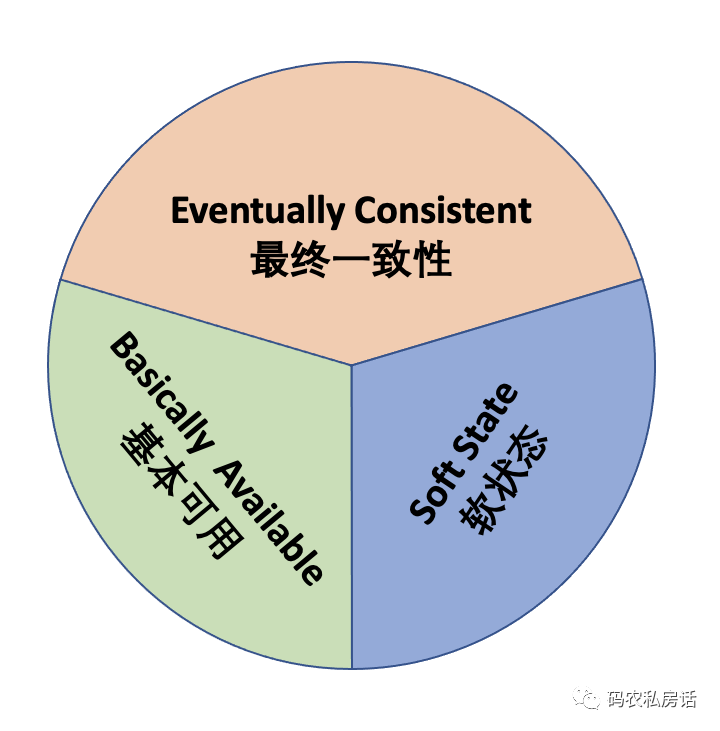
Base 理論是對 CAP 中一致性和可用性權衡的結果,其來源于對大型互聯網分布式實踐的總結,是基于 CAP 定理逐步演化而來的。
其核心思想是:既然無法做到強一致性,但每個應用都可以根據自身的業務特點,采用適當的方式來使系統達到最終一致性。
Basically Available(基本可用)
基本可用就是假設系統某個模塊出現了不可預知的故障,但其他模塊依舊可用,例如商城雙十一活動時,評論模塊出現故障,但不會影響交易、商品等核心模塊的流程使用。
Soft State(軟狀態)
軟狀態指的是允許系統中的數據存在中間狀態,并認為該狀態不影響系統的整體可用性,即允許系統在多個不同節點的數據副本存在數據延時。
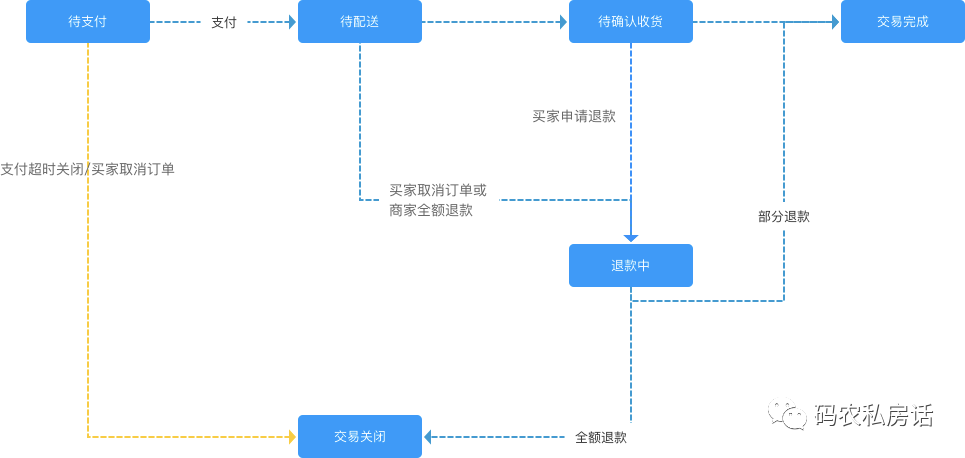
用戶在商城下單時,因網絡超時等因素,訂單處于“支付中”的狀態,待數據最終一致后狀態將變更為“關閉”或“成功”狀態。
Eventually Consistent(最終一致性)
上面講到的軟狀態不可能一直是軟狀態,必須有時間期限。在期限過后,應當保證所有副本保持數據一致性,從而達到數據的最終一致性,因此所有客戶端對系統的數據訪問最終都能夠獲取到最新的值,而這個時間期限取決于網絡延時,系統負載,數據復制方案等因素。
在 CAP 中的一致性要求在任何時間查詢每個節點數據都必須一致,它強調的是強一致性,而最終一致性是允許在一段時間內每個節點的數據不一致,但是經過一段時間每個節點的數據必須一致,它強調的是最終數據的一致性。
在實際情景中,最終一致性分為 5 種:
1. 因果一致性(Causal consistency)
如果節點 A 在更新完某個數據后通知了節點 B,那么節點 B 之后對該數據的訪問和修改都是基于 A 更新后的值,但對和節點 A 無因果關系的節點 C 的數據訪問則沒這限制。
2. 讀己之所寫(Read your writes)
節點 A 更新一個數據后,它自身總是能訪問到自身更新過的最新值,而不會看到舊值。
3. 會話一致性(Session consistency)
會話一致性將對系統數據的訪問過程限定在一個會話當中:系統能保證在同一個有效的會話中實現 “讀己之所寫” 的一致性,也就是說,執行更新操作之后,客戶端能夠在同一個會話中始終讀取到該數據項的最新值。
4. 單調讀一致性( Read consistency)
單調讀一致性指如果一個節點從系統中讀取出一個數據項的某個值后,那么系統對于該節點后續的任何數據訪問都不應該返回更舊的值。
5. 單調寫一致性(Write consistency)
指一個系統要能夠保證來自同一個節點的寫操作被順序的執行。
對于上面的 5 種最終一致性,在實際系統中往往會結合使用,以構建一個具有最終一致性的分布式系統。
實際上,不只是分布式系統使用最終一致性,在關系型數據庫的某個功能上,也是使用最終一致性的,比如數據備份、數據庫主從復制等過程是需要時間的。
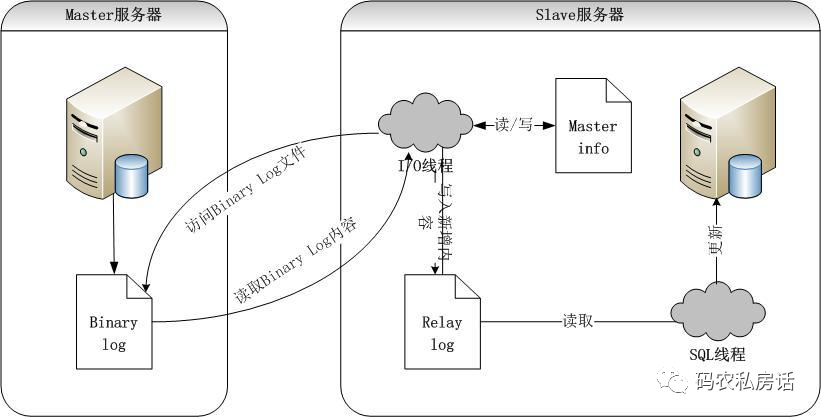
在復制過程中,業務讀取從服務器的值是舊的,經過一定時間后,主從服務器才會達成數據一致性,這也是最終一致性的經典案例。
最后總結
總的來說,BASE 理論面向的是大型高可用可擴展的分布式系統,和傳統事務的 ACID 是相反的,它完全不同于 ACID 的強一致性模型,而是通過犧牲強一致性來獲得可用性,并允許數據在一段時間是不一致的。