分布式系統中的那些一致性(CAP、BASE、2PC、3PC、Paxos、ZAB)
前言
工作過幾年的同學,尤其是這幾年,大家或多或少都參與過分布式系統的開發,遇到過各式各樣“分布式”問題,而遇到這些問題去解決時就是我們對這個知識學習的過程。
不知道大家是否跟我一樣,每每搜索到“分布式”關鍵詞,總會出現各種“分布式理論”,比如CAP、BASE理論、2PC、3PC 以及 Paxos、Raft、ZAB 算法,而這些貌似跟一致性都有一定的關系。
在讀過數次與之相關的不同文章后,每次都會有不一樣的理解以及困惑,比如,CAP中的 C 怎么就強一致了?BASE 理論的定義怎么這么抽象?還有 Paxos、ZAB、Raft 都是一致性算法,奧… 干!!!管求它。轉眼就又忘了,不曉得大家是否跟我一樣。
本文以我對這些一致性理論的理解進行闡述,希望可以對大家有一點幫助。
CAP理論
CAP理論是Eric Brewer教授在2000年提出的,大概是這樣的:
在分布式系統中,數據一致性,分區容忍性,系統可用性是不可能同時達到的,只能保證其中兩項可以達到。而由于在互聯網交互應用中,網絡不穩定的情況總是存在,網絡分區始終是不可避免的,從而在設計分布式系統時,總是考慮如何在數據一致性和系統可用性上進行取舍。
理解誤導
通常在一些CAP的文章中可以看到很多類似以下的說法:
C(consistency)一致性:訪問所有節點得到的結果是一致的。
A(Availability)可用性:請求在一定時間內可以得到正確的響應。
P(Partition tolerance)分區容錯性:在網絡分區的情況下,系統仍能提供服務。
并且后面會跟上這句話分布式系統不能保證同時使用C、A和P,只能選擇CP或AP 。
這樣的說法并沒有錯,因為提出該理論的作者確實有提出:
Any distributed system cannot guarantly C,A,and P simultaneously
但是會誤導讀者去理解。比如在我之前看到上述說法時會有幾個疑問:
- 對于分區容錯性,我搞個集群就可以;對于一致性,我理解那就跟ACID中的C是不一樣的,更像是某個組件集群部署后節點之間的數據一致性,那應該還是集群,為什么說是分布式系統呢?
- 怎么不能保證同時使用C,A, P?怎么一致就不可用了?可用就不一致了?不沖突吧?
CAP是CAP,這個“CP”或“AP”先適當存疑
正確的理解
后面去了解CAP理論的背景,得知作者寫了2版來闡述CAP,最后一個版本中寫道:
In a distributed system(a collection of interconnected nodes that share data),you can only have two out of the following three guarantees across a write/read pair: Consistency,Availability,and Partition Tolerance
在分布式系統(共享數據的互連節點的集合)中,在寫/讀對中只能有以下三種保證中的兩種:一致性、可用性和分區容錯
在這一個版本中的(共享數據的互連節點的集合)證實了我第一個疑問,至于為什么說分布式系統,我覺得應該是集群屬于分布式系統中的一個場景。
至于第二個疑問其實還是場景問題,如果在沒有網絡分區的情況下,C,A是可以同時滿足的,如果出現了網絡分區,C,A確實不可以同時滿足,舉個例子:如果來了一個寫操作,如果要滿足一致性,意味著這幾個節點的數據要一致后,數據才能被訪問,但是出現了網絡分區,就會等待網絡恢復或重試或者其他操作,必然滿足不了可用性的要求(在一定時間內可以得到正確的響應)。反過來,如果要在一定時間內得到正確響應,在網絡分區的情況下,一致性必然也滿足不了了。
所以CAP理論是有前提和場景的,總結一下應該是這樣的:分布式系統中存在共享數據的互連節點,在網絡分區的前提下,不能保證同時保證可用性和一致性。
CAP理論的應用
現在再說 Zookeeper 是 CP 架構、Eureka 是 AP 架構 應該就不難理解了。
這兩個組件都符合 CAP 中的(共享數據的互連節點的集合),Zookeeper 集群是 Leader 在寫數據時需要過半節點同意才會寫入,客戶端才會讀取到這個值,所以說 Zookeeper 是 CP 架構;Eureka 集群是不論哪個節點在寫數據時都會立即刷新本地數據然后再同步給其他節點,客戶端這個時候讀取不同節點時就會發現數據不一致,所以 Eureka 是 AP 架構。
BASE理論
BASE是Basically Available(基本可用)、Soft state(軟狀態)和 Eventually consistent(最終一致性)三個短語的縮寫。
- 基本可用
基本可用是指分布式系統在出現不可預知故障的時候,允許損失部分可用性,不像 CAP 中的定義那樣嚴格(在一定時間內可以得到正確的響應)。比如:
響應時間上的損失。正常情況下,0.5秒之內返回給用戶結果,但由于出現故障,會有重試等操作,3秒內返回也是接受的。
系統功能上的損失:正常情況下,用戶可以順利完成每一筆訂單,但是在一些節日大促購物高峰的時候,為了保護系統的穩定性,部分用戶可能會被引導到一個降級頁面。
- 軟狀態
軟狀態指允許系統中的數據存在中間狀態,這種中間狀態的存在不會影響系統的整體可用性。比如:在交易的場景中,因為會存在交易失敗的情況,所以不會直接扣減 A 賬戶100到 B 賬戶上,而是先凍結 A 賬戶100。
- 最終一致性
最終一致性是指在經過一段時間后,軟狀態的數據達到一致的狀態。比如:在凍結 A 賬戶100后,如果失敗那就扣減A賬戶凍結的100至可用余額中;交易成功再將 A 賬戶凍結的100扣減,并添加至 B 賬戶的可用余額。最終達到一致性。
有很多的文章說是BASE理論是CAP理論的演進,這種說法先存疑,先存疑。因為CAP理論的場景是分布式系統(共享數據的互連節點的集合),而BASE理論是滿足更多的場景的。
Paxos算法
Paxos算法是萊斯利·蘭伯特于1990年提出的一種基于消息傳遞且具有高度容錯特性的一致性算法。
基于消息傳遞通信模型的分布式系統,不可避免的會發生以下錯誤:進程可能會慢、被殺死或者重啟,消息可能會延遲、丟失、重復。Paxos 算法解決的問題是在一個可能發生上述異常的分布式系統中如何就某個值達成一致,保證不論發生以上任何異常,都不會破壞決議的一致性。
如何保證一致性?
OK,通過下圖看看 Paxos 是如何保證一致性的。為了方便理解,圖中的議員暫且當作一個注冊中心集群中的實例。
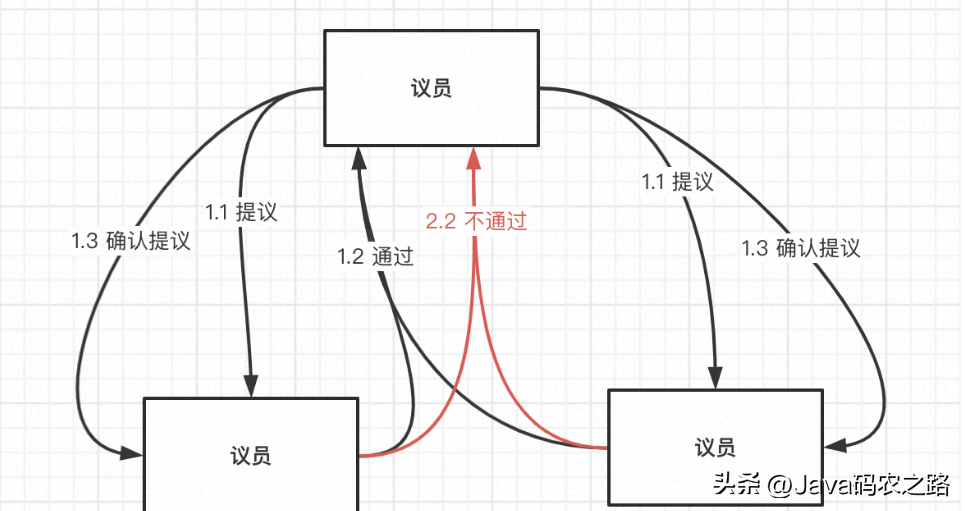
- 當某個議員有某些想法時想讓其他議員認可并批準,那么會以提案的方式進行決定。
- 在提交一個提案時都會獲取到一個具有全局唯一性的、遞增的提案編號(N),然后發送給其他議員。
- 其他議員在收到這個編號后會與自己批準過的提案中最大編號進行比較:
如果沒有收到的編號(N)大,那么它就會將它已經批準過編號最大的提案響應給提案者,意味著認可這個提案。
如果比收到的編號(N)大,則代表編號(N)被處理過,不做任何響應,意味著不認可這個提案。
4.提案者在收到半數以上響應后,就會再次發送一個確認的請求給其它議員進行執行。
5.其他議員在收到確認的請求后,發現沒有對編號大于N的提案請求做出過響應,它就批準該提案。
這個我感覺是和2PC一樣,通過兩階段提交,最終確認是否批準,只不過是實現細節以及使用場景不同罷了。當然也會存在2PC中第二階段節點失去通信問題,這種情況議員們最多不批準提案,不會影響一致性問題。
死循環問題
Paxos 算法有幾率出現死循環問題,導致提案不通過。如下圖:
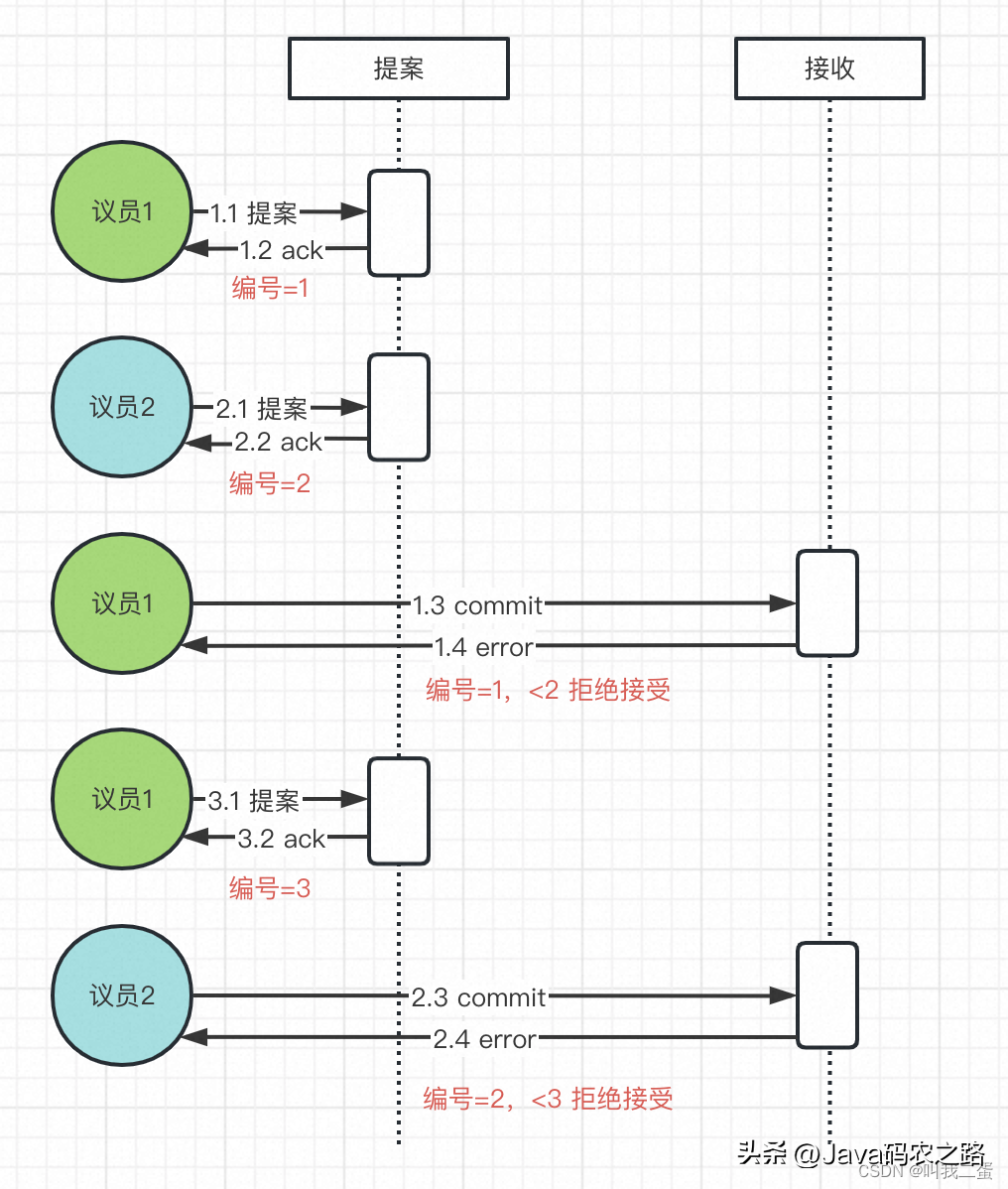
假設我們有2個議員同時發出提案請求。
- 議員1提交編號為1的提案并收到過半響應。
- 此時議員2提交編號為2的提案也收到過半響應。
- 由于提案階段響應的編號已為2,根據“沒有對編號大于N的提案請求做出過響應,它就批準該提案”,所以議員1的編號(1)在接收階段不會被批準。
- 如果此時議員1重新發送編號為3的提案并通過后,議員2的提案在接收階段也不會通過。
如此循環,就會造成死循環。
ZAB協議
ZAB 協議(ZooKeeper Atomic Broadcast)原子廣播是 ZooKeeper 用來保持所有服務器消息的順序同步并保證一致,與 Paxos 不同,其為主備架構,所以在同步數據時不會出現多個節點同時提交提案(死循環問題),而是會在集群節點中選舉 Leader ** 節點,統一經由 Leader 節點進行提案,但是主備架構避免不了 Leader 節點的崩潰,如果出現該問題,ZAB 還會保證集群節點的崩潰恢復**。關于ZAB更多描述去ZooKeeper官網看看。
所以 ZAB 協議主要做了3件事:
- 選舉 Leader 節點。
- 以廣播的方式保證副本之間的消息一致。
- Leader 節點崩潰后進行崩潰恢復。
Leader 選舉
在這之前先了解下 ZAB 節點的三種狀態:
- FOLLOWING:當前節點是跟隨者,服從 leader 節點的命令。
- LEADING:當前節點是 leader,負責協調事務。
- LOOKING:節點處于選舉狀態。
當集群初始啟動時,每個節點會投自己一票并向其他節點發起投票請求,進入 LOOKING 狀態。當某個節點的投票數過半后,該節點進入LEADING 狀態,當選 Leader,其他節點則會進入 FOLLOWING 狀態,成為 Follower。下面以3臺服務器為例,介紹 Leader 選舉過程:
發起投票
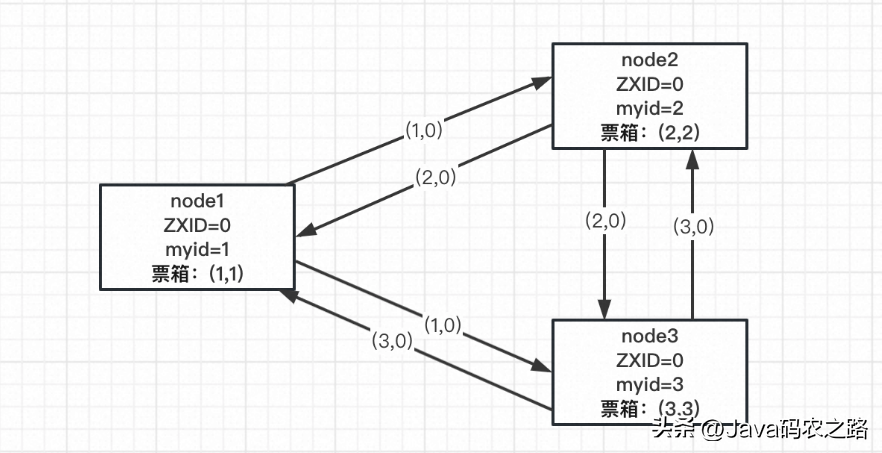
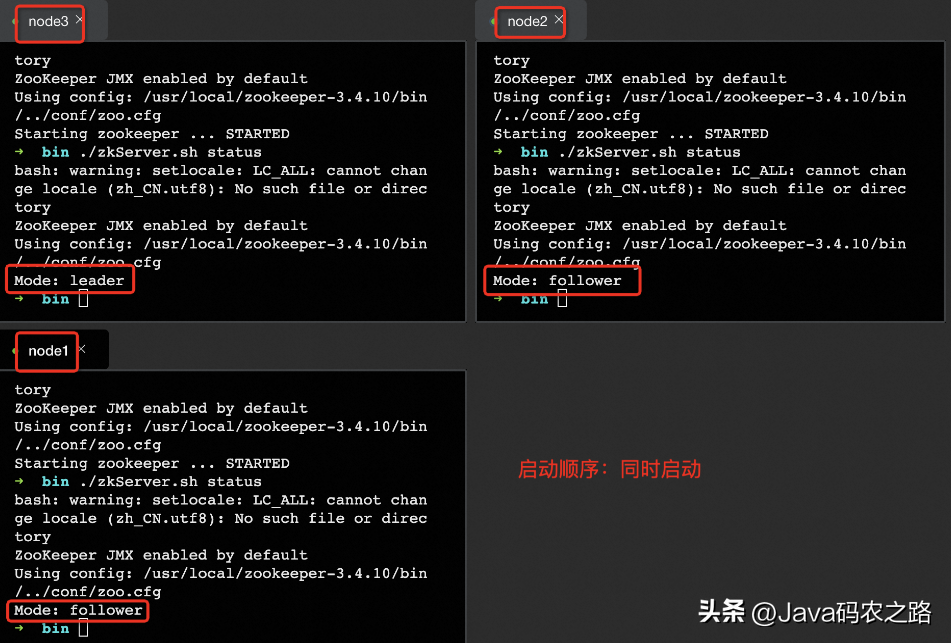
如上圖,三個節點同時啟動首先會向自己投一票,并將(myid,ZXID)作為投票信息向其他兩個節點發送。此時每個節點的投票箱都是自己投個自己(myid,myid)。myid是每個節點的標識;ZXID 是最近一次的事務ID,初始值為0。
PK階段
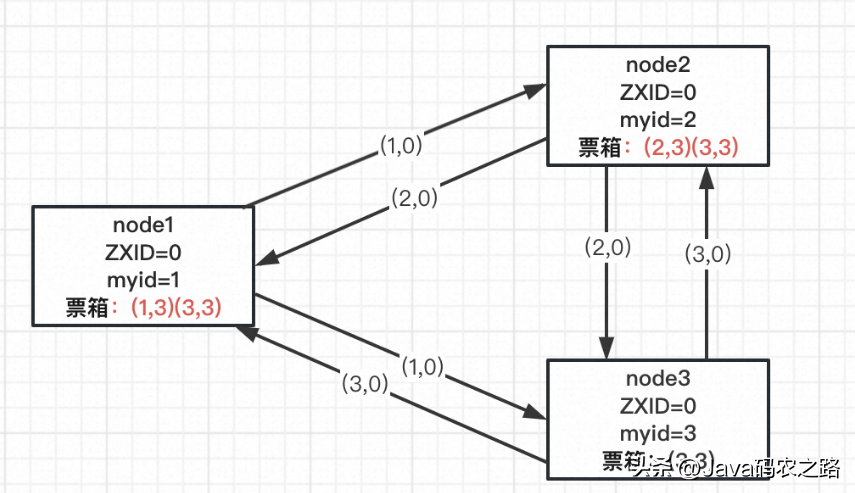
每個節點在收到投票請求后會比較 ZXID,如果 ZXID 相等則比較 myid 。比較時如果自己節點的ZXID或myid小,那么更新自己的投票(myid,勝出節點id)并添加收到的投票至票箱(勝出節點id,勝出節點id)。
如上圖,node1 在收到 node2、3 的投票請求后,由于ZXID相等,node3的myid大,所以 node1 更新自己的投票箱并添加 node3 的投票,此時為(1,3)(3,3)。
node2同樣如此,投票結果為此時為(2,3)(3,3)。
node3不做更新操作。
廣播投票
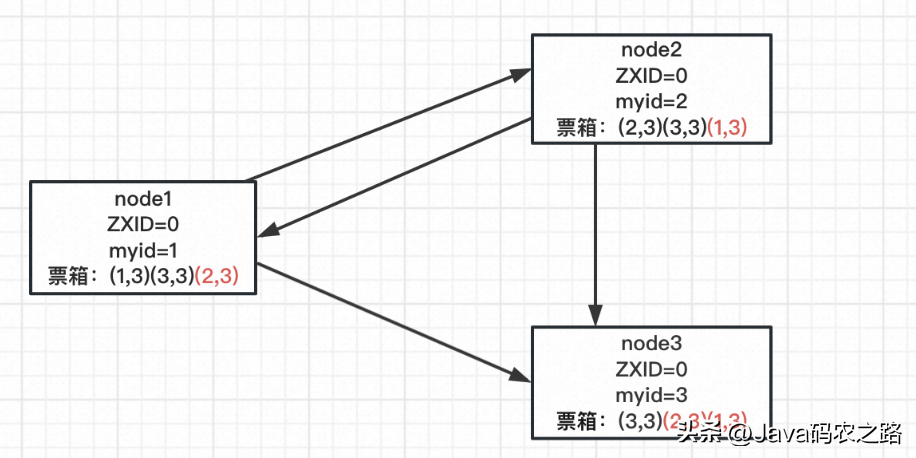
node1、node2 在更新自己的投票結果后向其他兩個節點廣播投票結果,結果如上圖。
根據上述投票,三個服務器一致認為 node3 應該是 Leader 。所以 node3 進入 LEADING 狀態成為 Leader,node1、node2 進入 FOLLOWING 狀態稱為 follower。
下圖是搭建了 Zookeeper 集群啟動后的結果,也驗證上述選舉算法。
廣播消息
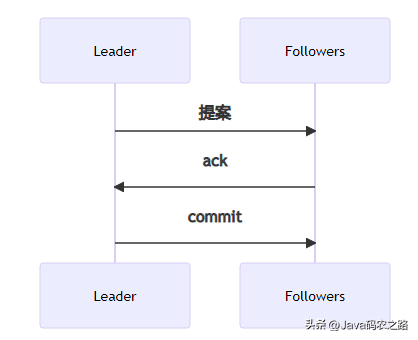
為了保障副本之間的數據一致,ZAB協議做了以下幾點:
- 所有的寫請求都通過 Leader 進行操作,如果 Follower 收到寫請求,會轉發給 Leader。
- Leader 針對寫請求會生成一個提案,并為這個提案生成一個ZXID(保障一致、順序。)
- Followers 在收到提案后 ack 給 Leader。
- Leader 在收到過半的 Follower ack 后會廣播一個 commit 消息。
- Follower 收到 commit 消息后會比較 ZXID,如果之前沒有處理過比 ZXID 大的寫請求,那就進行提交。
崩潰恢復
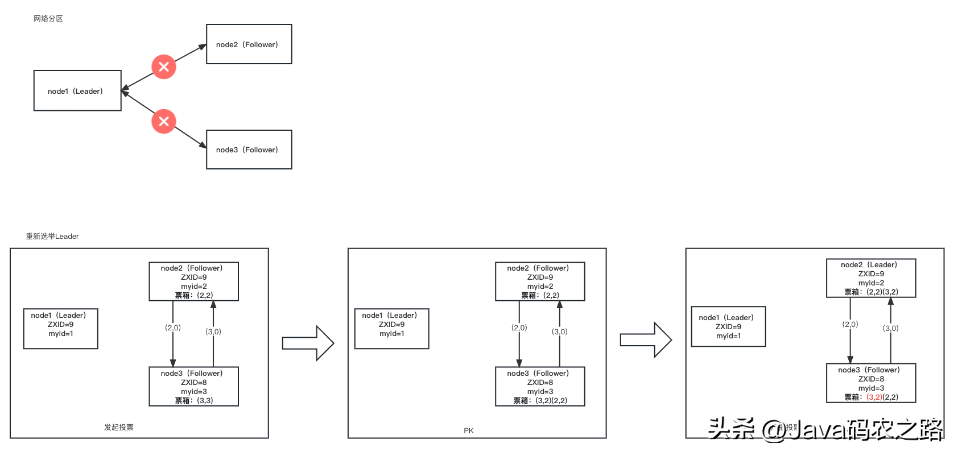
Leader 重新選舉
當網絡異常造成網絡分區或者某個節點崩潰,如果是 Leader 節點這時候需要進行重新選舉。如下圖
數據同步
選舉新的 Leader 后,其他節點的數據要與之同步。同步過程如下圖
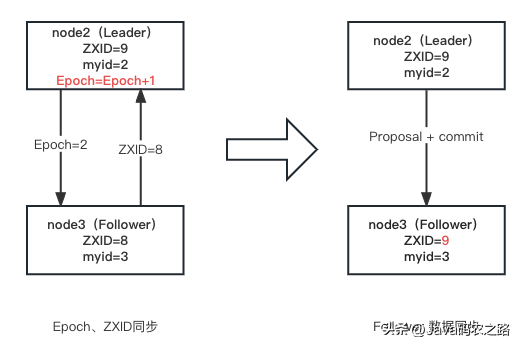
- 在選舉為 Leader 后,node2 將自身的 Epoch 進行自增并發送給 Follower,Follower進行更新并將自己的ZXID同步給 Leader 。每次選舉 Leader 后 Epoch 會+1,這樣,當老的 Leader 重新連接到集群后,會對比其日志中 epoch 編號與 leader 此時的 epoch 編號:對于 epoch 更小的那部分日志,就舍棄掉。
- Leader 根據 ZXID 的差異進行同步。上圖 Leader 會將 Follower 未提交的事務以提案進行逐條發送和提交給 Follower ,Follower 收到提案和提交請求后進行同步。
老 Leader 恢復
當老的 Leader 恢復后要加入集群中,其過程如下:

- node1 發起投票,node2、node3 響應自己的角色和投票,通過 node2 的響應,可以知道 node2 為 Leader ,并且通過兩者的投票可以確定 node2 為 Leader ,因此自己成為 Follower。
- 在選舉為 Leader 后 將自身的 Epoch 進行自增并發送給 Follower,Follower進行更新并將自己的ZXID同步給 Leader。
- Leader 根據 ZXID 的差異進行同步。上圖 ZXID無差異,所以無需同步。
Raft算法
Raft 算法按照我的理解是和ZAB協議相似,兩者相同的概念可能名詞不同,比如:ZAB 中的 Epoch 和 Raft 的 Term 概念相同;實現方式大體相似,細節不同,比如:數據同步都是通過 Leader 節點進行提案,不同的是 Raft 通過狀態達到一致、Leader 選舉方式相似,發起投票時都會投自己一票,實現上 Raft 通過兩個 timeout 控制選舉。這里我就不多廢話了,大家可以通過Raft算法動態演示更容易理解。
總結
所以為什么有這么多的一致性定義呢?之間有什么關系?
我覺得還是場景,首先ACID、CAP、BASE都是理論,ACID是專注于事務、CAP理論作用在集群副本場景、BASE理論應用最終一致性場景。
而2PC、3PC則是對于事務完整性的具體解決方案,Paxos、ZAB、Raft更傾向于集群副本一致性的解決方案。