













面試官問我平時寫的Bug的存儲位置
本文轉載自微信公眾號「大魚仙人」,作者大魚 。轉載本文請聯系大魚仙人公眾號。
說到寫bug,我們每天都在用Java實現著各種需求,我們實現的Java程序每天都運行在每個機器的虛擬機上,但是你了解你寫的代碼的具體存儲位置嗎
說實話,這個東西,在我剛開始學Java的時候,我聽到JVM虛擬機這個名詞的時候,我的感覺是這個樣子的(慚愧
你們肯定也會有些疑問吧,平時寫的代碼每一部分都是存儲在哪里的?是的,沒錯,我的內心就像拖著下巴的那位,除了,模樣,emmm...
雖然現在也不是多么的精通,但是比之前好太多了,不是涉及很底層的東西也算是了解一些,當然真要是問我各種涉及細節,毫不謙虛的說,以我的水平,我可能只會阿巴阿巴(逃
如果大家對更深入的JVM感興趣,可以和JVM大神R大這種多去溝通溝通
是的,沒錯,其實我這個文章算是掃盲文章,但是在掃盲文章的基礎上說的更細一點,更多一點,我也會給大家拋出一些面試官愛問的問題,并且幫大家解答,所以大家請盡情讀下去,肯定會讓你有所收獲
大家覺得不錯的點個關注,大家一起探討、一起學習、一起進步
JVM內存結構
JVM內存布局,先給大家上個圖
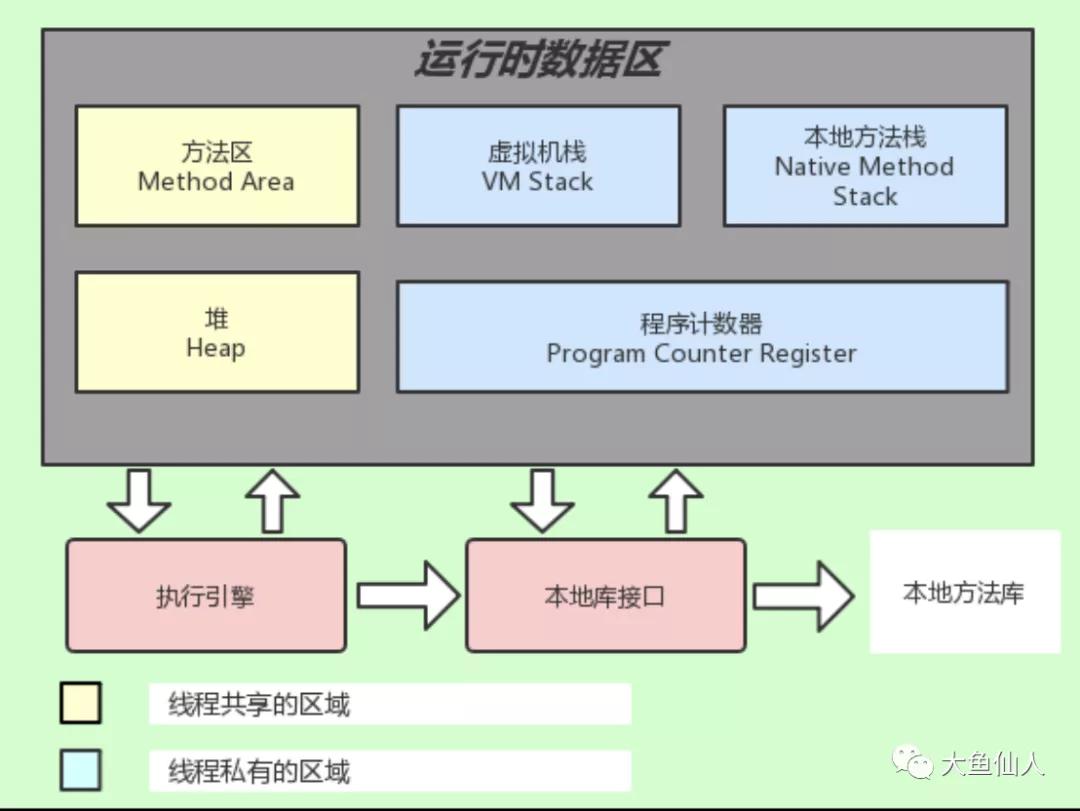
如果你是讀過JVM文章的養魚仔的話,那你肯定看過上面類似的圖,我在給大家放一張,大家在熟悉一遍,看過的回一下,沒看過的混個臉熟
JVM內存主要分為堆、虛擬機棧、本地方法棧、方法區、程序計數器等,堆是虛擬機內存占據最大的一部分,堆的目的就是盛放大量的對象實例的;虛擬機棧對應的是方法的執行過程,本地方法棧是用來調用本地方法的執行過程;方法區就是用來存儲存儲類信息、常量、靜態變量的數據,是線程共享的數據;程序計數器,就是存儲著線程下一條將要執行的指令
每個區域都有其特定的功能,就像是一個企業,一個工作室,每個人發揮著自己的長處,各司其職
走著吧,各位養魚仔(我是魚),一起來瞧瞧每一部分的具體的細節以及面試官愛問的問題
虛擬機堆
Java堆是垃圾收集器管理的主要地方,因此很多的時候也被稱為GC堆,Java堆還可以分為年輕代和老年代,年輕代又可以分為Eden空間、From Survivor空間、To Survivor空間,默認是8:1:1的比例
根據Java虛擬機規范的規定,Java堆可以處于物理上不連續的內存空間中,只要邏輯上是連續的即可,就像我們的磁盤空間一樣
在實現時,既可以實現成固定大小的,也可以是可擴展的,不過當前主流的虛擬機都是按照可擴展來實現的(通過-Xmx和-Xms控制);如果在堆中沒有內存完成實例分配,并且堆也無法再擴展時,將會拋出OutOfMemoryError異常。
打斷一下,Java堆的區域都是線程共享的嗎?
當你聽到這個問題的時候,你首先想到的是什么呢?
let me tell you,面試官其實問這個的時候就是在看你對堆的了解程度,你只知道是用來放對象實例的,那面試官對你表現覺得不算非常滿意;但是如果你知道TLAB,并且知道它的原理和問題,那面試官就會覺得:這小伙子不一般,我得再多深入了解了解,可以考慮當我的好助手
首先,你得肯定回答,沒錯,堆是全局共享的,但是會存在一些問題,那就是多個線程在堆上同時申請空間,如果在并發的場景中,兩個線程先后把對象引用指向了同一個內存區域,那可能就會出現問題;為了解決這個問題呢,就得進行同步控制,說到同步控制,就會影響到效率
就拿Hotspot來舉例子,它的解決方案是每個線程在堆中都預先分配一小塊內存,然后再給對象分配內存的時候,先在這塊“私有內存”進行分配,這塊用完之后再去分配新的“私有內存”,這就是TLAB分配
你也看到了,我加引號了,它并不是真正意義上的私有,而是表面上的私有;它是從堆內存劃分出來的,有了TLAB技術,堆內存并不是完完全全的線程共享,每個線程在初始化的時候都會去內存中申請一塊TLAB
切記:并不是TLAB區域的內存其它線程完全無法訪問,其它線程也是可以讀取的,只不過無法在這個區域分配內存而已
說到這的時候,也給面試官一個眼神,說明我的干貨還沒完,我還能繼續吹
難道TLAB很完美嗎?所謂,金無足赤人無完人,肯定有他的問題所在
我們知道TLAB是線程特有的,它的內存區域不是很大,所以會出現一些不夠用的情況,比如一個線程的TLAB的空間有100KB,其中已經使用了80KB,如果還需要再分配一個30KB的對象,則無法直接在TLAB上分配了,這種情況有兩種解決辦法
- 直接在堆中分配
- 廢棄當前TLAB,重新申請TLAB空間再次進行內存分配
其實兩種各有利弊,第一種的缺點就是存在一種極端情況,TLAB只剩下1KB,就會導致后續的分配可能大多數對象都需要直接在堆中分配;第二種的就是可能會出現頻繁的廢棄TLAB、頻繁申請TLAB的情況
為了解決這兩個方案存在的問題,虛擬機定義了一個refill_waste的值,這個值可以翻譯為“最大浪費空間”。當請求分配的內存大于refill_waste的時候,會選擇在堆內存中分配。若小于refill_waste值,則會廢棄當前TLAB,重新創建TLAB進行對象內存分配
那你剛剛說的,幾乎所有對象實例都存儲在這里,是還有例外嗎?能詳細解釋下嗎?
是的,親愛的面試官,Java對象實例和數組元素不一定都是在堆上分配內存,滿足特定的條件的時候,它們可以在棧上分配內存
面試官微微一笑,什么情況呢?
親愛的面試官,是這樣子的,JVM中的Java JIT編譯器有兩個優化,叫做逃逸分析和標量替換;
逃逸分析,聽著有點意思,逃,誰逃,什么時候逃,往哪里逃?
中文維基上對逃逸分析的描述挺準確的,摘錄如下:
在編譯程序優化理論中,逃逸分析是一種確定指針動態范圍的方法——分析在程序的哪些地方可以訪問到指針。當一個變量(或對象)在子程序中被分配時,一個指向變量的指針可能逃逸到其它執行線程中,或是返回到調用者子程序。
大魚白話文版本:
一個子程序分配了一個對象并且返回了該對象的指針,那么這個對象在整個程序中被訪問的地方無法確定,任何調用這個子程序的都可以拿到這個對象的位置,并且調用這個對象,遂,對象逃之;
若指針存儲在全局變量或者其它數據結構中,全局變量也可以在子程序之外被訪問到,遂,對象逃之;
若未逃之,則可將方法變量和對象分配到棧上,方法執行完之后自動銷毀,不需要垃圾回收的介入,提高系統的性能
簡潔版:
逃逸分析通過分析對象引用的作用域,來決定對象的分配地方(堆 or 棧)
我們一起來看個例子
- public StringBuilder getBuilder1(String a, String b) {
- StringBuilder builder = new StringBuilder(a);
- builder.append(b);
- // builder通過方法返回值逃逸到外部
- return builder;
- }
- public String getBuilder2(String a, String b) {
- StringBuilder builder = new StringBuilder(a);
- builder.append(b);
- // builder范圍維持在方法內部,未逃逸
- return builder.toString();
getBuilder1中的builder對象會通過方法返回值逃逸到方法的外部,而反觀getBuilder2中的builder對象則不會溢出去,作用域只會在方法內部,toString方法會new一個String用來返回,所以沒有逃逸
如果把堆內存限制得小一點(比如加上-Xms10m -Xmx10m),關閉逃逸分析還會造成頻繁的GC,開啟逃逸分析就沒有這種情況,說明逃逸分析確實降低了堆內存的壓力
逃逸分析了之后,就可以直接降低堆內存的壓力嗎?(你剛剛說的那個標量替換是什么)
但是,逃逸分析只是棧上內存分配的前提,接下來還需要進行標量替換才能真正實現。標量替換用話不太好說明,直接來看例子吧,形象生動
- public static void main(String[] args) throws Exception {
- long start = System.currentTimeMillis();
- for (int i = 0; i < 10000; i++) {
- allocate();
- }
- System.out.println((System.currentTimeMillis() - start) + " ms");
- Thread.sleep(10000);
- }
- public static void allocate() {
- MyObject myObject = new MyObject(2019, 2019.0);
- }
- public static class MyObject {
- int a;
- double b;
- MyObject(int a, double b) {
- this.a = a;
- this.b = b;
- }
- }
標量,就是指JVM中無法再細分的數據,比如int、long、reference等。相對地,能夠再細分的數據叫做聚合量
Java虛擬機中的原始數據類型(int,long等數值類型以及reference類型等)都不能再進一步分解,它們就可以稱為標量。相對的,如果一個數據可以繼續分解,那它稱為聚合量,Java中最典型的聚合量是對象
如果逃逸分析證明一個對象不會被外部訪問,并且這個對象是可分解的,那程序真正執行的時候將可能不創建這個對象,而改為直接創建它的若干個被這個方法使用到的成員變量來代替。拆散后的變量便可以被單獨分析與優化,可以各自分別在棧幀或寄存器上分配空間,原本的對象就無需整體分配空間了
仍然考慮上面的例子,MyObject就是一個聚合量,因為它由兩個標量a、b組成。通過逃逸分析,JVM會發現myObject沒有逃逸出allocate()方法的作用域,標量替換過程就會將myObject直接拆解成a和b,也就是變成了:
- static void allocate() {
- int a = 2019;
- double b = 2019.0;
- }
可見,對象的分配完全被消滅了,而int、double都是基本數據類型,直接在棧上分配就可以了。所以,在對象不逃逸出作用域并且能夠分解為純標量表示時,對象就可以在棧上分配
除了這些之后,你還知道哪些優化嗎?
emmm,先思索一下(即使知道,也要稍加思考!
除此之外,JVM還有一個同步消除(鎖消除):鎖消除是Java虛擬機在JIT編譯是,通過對運行上下文的掃描,去除不可能存在共享資源競爭的鎖,通過鎖消除,可以節省毫無意義的請求鎖時間。
鎖消除基于分析逃逸基礎之上,開啟鎖消除必須開啟逃逸分析
線程同步本身比較耗,如果確定一個對象不會逃逸出線程,無法被其它線程訪問到,那該對象的讀寫就不會存在競爭,對這個變量的同步措施就可以消除掉。單線程中是沒有鎖競爭。(鎖和鎖塊內的對象不會逃逸出線程就可以把這個同步塊取消)
- public synchronized String append(String str1, String str2) {
- StringBuffer sBuf = new StringBuffer();
- // append方法是同步操作
- sBuf.append(str1);
- sBuf.append(str2);
- return sBuf.toString();
- }
從源碼中可以看出,append方法用了synchronized關鍵詞,它是線程安全的。但我們可能僅在線程內部把StringBuffer當作局部變量使用
這時我們可以通過編譯器將其優化,將鎖消除,前提是java必須運行在server模式,server模式會比client模式作更多的優化,同時必須開啟逃逸分析
說一說剛剛說的這些的參數嗎
我個乖乖兔,這我哪記得,不過得虧我昨天剛讀了大魚的文章,順便學習了下
逃逸分析:-XX:+DoEscapeAnalysis開啟逃逸分析(jdk1.8默認開啟,其它版本未測試);-XX:-DoEscapeAnalysis 關閉逃逸分析
同步消除:-XX:+EliminateLocks開啟鎖消除(jdk1.8默認開啟,其它版本未測試);-XX:-EliminateLocks 關閉鎖消除
標量替換:-XX:+EliminateAllocations開啟標量替換(jdk1.8默認開啟,其它版本未測試);-XX:-EliminateAllocations 關閉標量替換
那你平時是用哪些參數優化內存的?
一般我個人接觸到的有兩類參數:內存調整參數、垃圾收集器調整參數
內存調整參數:-Xmx堆內存最大值;-Xms堆內存最小值;-Xmn堆新生代的大小;-Xss設置線程棧的大小;-XX:NewRatio指定堆中的老年代和新生代的大小比例, 不過使用CMS收集器的時候這個參數會失效
關于方法區的參數,在JDK8之前,用-XX:PermSize和-XX:MaxPermSize來分別設置方法區的最小值和最大值;JDK8以及之后不再使用這個參數來設置方法區了,改為-XX:MeatspaceSize和-XX:MaxMetaspaceSize來設置方法區的大小了,Max參數主要就是防止某些情況導致Metaspace無限的使用本地內存,若超過設定值就會觸發Full GC,所以需要根據系統內存大小來動態的改變此值
垃圾收集器的調整參數我就不舉例子了,垃圾收集器調整參數就是設置JVM的垃圾收集器或者調整收集器的一些優化參數,說實話大魚也不沒那么了解,這種參數我一般都是用到的時候去查資料,也沒啥必要了解那么細,專業人員除外
你剛剛說了堆內存中有個8:1:1,出于什么考慮這樣設計的呢
有的對象朝生夕死,有的對象可能會活很久很久,有的對象很小,有的對象可能會很大,每個對象的特點不一樣,分配的堆內存地方不一樣,也就對應著不同的回收策略以及垃圾回收器,年輕代就是存放那種使用完就立馬回收的對象,而老年代則用來存放那些長期駐留在內存中的對象
其實說白了,就是根據多種對象的特點來設計出多種了回收策略,而對于整塊內存使用一種回收策略是不友好的,所以根據對象的特點來將堆內存拆分開,然后對于每塊內存采用不同的回收策略
虛擬機棧和本地內存棧
Java虛擬機棧屬于線程私有的,生命周期和線程相同;虛擬機棧是Java方法執行的內存模型,描述的方法的執行過程;每個方法被執行的時候都會同時創建一個棧幀結構,用于存儲局部變量表、操作數棧、動態鏈接、方法出口等信息,棧里面會包含很多的
棧幀,可以認為每一個方法的調用直到執行完成對應這一個棧幀的入棧和出棧的過程
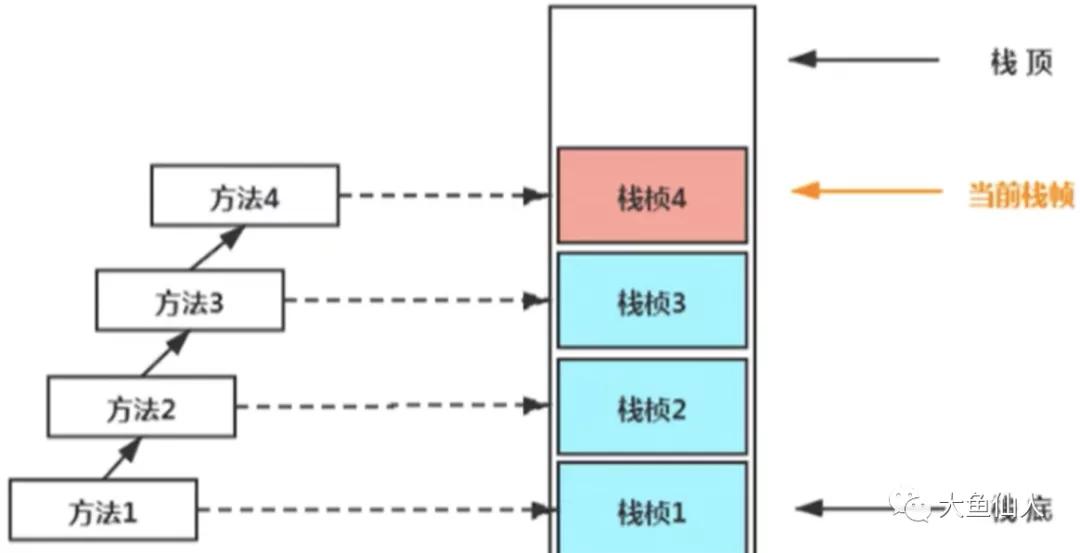
虛擬機棧的棧幀里面都包含什么呢?
主要是包含局部變量表、操作數棧、動態鏈接、方法出口這些,接著我們來看下每一部分的作用
這些大家不需要死記硬背的哦,需要大家理解記憶,最重要的是理解每一部分的作用,下面可能第一次接觸的會比較枯燥,keep
局部變量表:存放了編譯期可知的各種基本數據類型、對象引用(reference類型,它不等同于對象本身,它可能是一個指向對象起始地址的引用指針,也可能指向一個代表對象的句柄或者其他與此對象相關的位置)。
操作數棧:一個后進先出的操作數棧,主要用于保存計算過程的中間結果,同時作為計算過程中變量臨時的存儲空間。
操作數棧就是JVM執行引擎的一個工作區,當一個方法剛開始執行的時候,一個新的棧幀也會隨之被創建出來,這個方法的操作數棧是空的。每一個操作數棧都會擁有一個明確的棧深度用于存儲數值,其所需的最大深度在編譯期就定義好了,保存在方法的Code屬性中,為maxstack的值。
動態鏈接:在Java源文件被編譯到字節碼文件中時,所有的變量和方法引用都作為符號引用(symbolic Reference)保存在class文件的常量池里。比如:描述一個方法調用了另外的其他方法時,就是通過常量池中指向方法的符號引用來表示的,那么動態鏈接的作用就是為了將這些符號引用轉換為調用方法的直接引用。
方法出口:存放調用該方法的pc寄存器的值。一個方法的結束,有兩種方式:正常執行完成、出現未處理的異常,非正常退出
無論通過哪種方式退出,在方法退出后都返回到該方法被調用的位置。方法正常退出時,調用者的pc計數器的值作為返回地址,即調用該方法的指令的下一條指令的地址。而通過異常退出的,返回地址是要通過異常表來確定,棧幀中一般不會保存這部分信息。
棧的深度問題
在Java虛擬機規范中,對這個區域規定了兩種異常狀況:
如果線程請求的棧深度大于虛擬機所允許的深度,將拋出StackOverflowError異常;如果虛擬機棧可以動態擴展(當前大部分的Java虛擬機都可動態擴展,只不過Java虛擬機規范中也允許固定長度的虛擬機棧),當擴展時無法申請到足夠的內存時會拋出OutOfMemoryError異常。
那本地方法棧是干什么的?
本地方法棧(Native Method Stacks)與虛擬機棧所發揮的作用是非常相似的,其區別不過是虛擬機棧為虛擬機執行Java方法(也就是字節碼)服務,而本地方法棧則是為虛擬機使用到的Native方法服務。
虛擬機規范中對本地方法棧中的方法使用的語言、使用方式與數據結構并沒有強制規定,因此具體的虛擬機可以自由實現它。甚至有的虛擬機(譬如Sun HotSpot虛擬機)直接就把本地方法棧和虛擬機棧合二為一。與虛擬機棧一樣,本地方法棧區域也會拋出StackOverflowError和OutOfMemoryError異常。
Java虛擬機棧于管理Java方法的調用,而本地方法棧(Native Method Stack)用于管理本地方法的調用。本地方法棧,也是線程私有的。
方法區
方法區(Method Area)與Java堆一樣,是各個線程共享的內存區域,它用于存儲已被虛擬機加載的類信息、常量、靜態變量、即時編譯器編譯后的代碼等數據。
方法區在原來被習慣性的稱之為永久代,但是在JDK1.8中永久代已經不存在了,存儲的類信息、編譯之后的代碼數據都移到了元空間,而元空間并沒有在堆中,而是直接占用的本地內存
元空間和永久代本質是類似的,其實都是對JVM規范中的方法區的實現,元空間并不在虛擬機中,而是使用本地內存。因此,默認情況下,元空間的大小僅受本地內存限制
程序計數器
程序計數器啊,聽名字其實就知道了,主要作用就是計數的,但是這里的計數并不是計算數量,而是記下一條的字節碼指令
程序計數器占一小塊內存空間,就是當前線程的執行的字節碼的行號指示器,字節碼解釋器工作時就是通過改變這個計數器的值來選取下一條需要執行的字節碼指令,分支、循環、跳轉、異常處理、線程恢復等基礎功能都需要依賴這個計數器來完成。
那程序計數器是線程私有還是公有?
相信聰明的養魚仔肯定已經猜到了,當然是私有的嘞
Java虛擬機多線程是通過線程輪流切換并分配處理器執行時間的方式來實現的,在任何一個確定的時刻,一個處理器(對于多核處理器來說是一個內核)只會執行一條線程中的指令。因此,為了線程切換后能恢復到正確的執行位置,每條線程都需要有一個獨立的程序計數器,各條線程之間的計數器互不影響,獨立存儲,我們稱這類內存區域為“線程私有”的內存。
如果線程正在執行的是一個Java方法,這個計數器記錄的是正在執行的虛擬機字節碼指令的地址,如果正在執行的是Natvie方法,這個計數器值則為空(Undefined)。此內存區域是唯一一個在Java虛擬機規范中沒有規定任何OutOfMemoryError情況的區域。
我愛總結
好了,今天就先聊到這了,天也不早了,你早點回家休息吧,好好準備準備明天下午來繼續下一輪面試吧
好的,尊敬的面試官(逃
回到家之后我就拿出我的小本本一頓總結,跟著大魚一起來看看吧,養魚仔們
- 堆:線程共享,主要用于分配實例對象,但由于逃逸分析的存在也不是完全在堆上分配,可能在棧上分配;逃逸分析是個基礎,標量替換和鎖消除正是基礎逃逸分析的優化;堆中還有個TLAB分配,屬于線程私有,但又不是完全意義上的私有
- 棧:線程私有,虛擬機棧主要是用于Java方法的執行,每個棧幀對應一個方法的入棧和出棧,包含局部變量、操作數棧、動態鏈接和方法出口這些;本地方法棧則是用于執行本地方法的
- 方法區:線程共享,存放加載的類信息、常量、靜態變量以及即時編譯器編譯之后的代碼
- 程序計數器:線程私有,存放每個線程接下來要執行的指令



















