看完這篇,再也不怕面試官問我線程池了
本文轉載自微信公眾號「牧小農」,作者牧小農。轉載本文請聯系牧小農公眾號。
一、為什么需要線程池
在實際使用中,線程是很占用系統資源的,如果對線程管理不完善的話很容易導致系統問題。因此,在大多數并發框架中都會使用線程池來管理線程,使用線程池管理線程主要有如下好處:
- 1、使用線程池可以重復利用已有的線程繼續執行任務,避免線程在創建和銷毀時造成的消耗
- 2、由于沒有線程創建和銷毀時的消耗,可以提高系統響應速度
- 3、通過線程可以對線程進行合理的管理,根據系統的承受能力調整可運行線程數量的大小等
二、工作原理
流程圖:
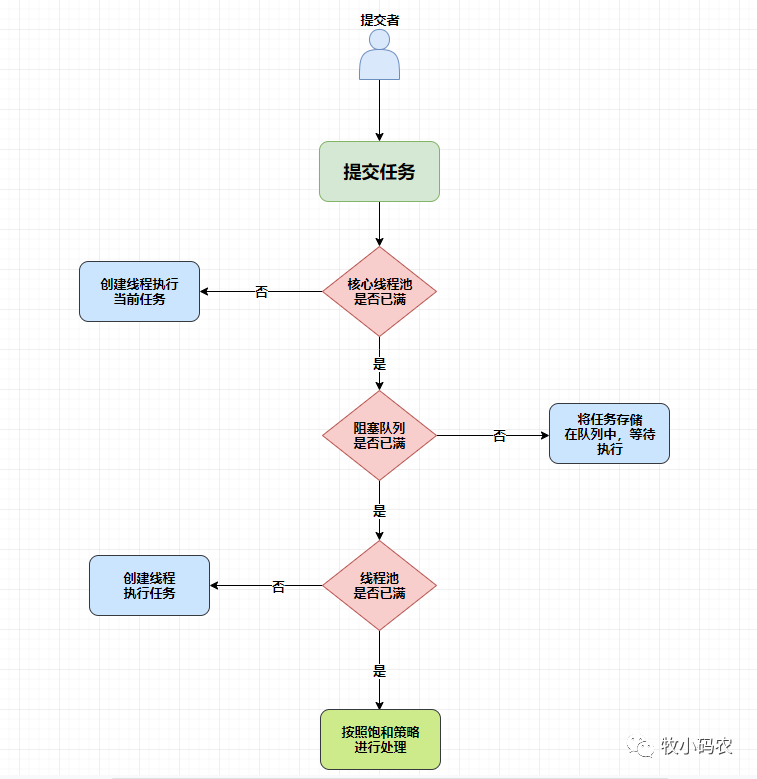
線程池執行所提交的任務過程:
- 1、比如我們設置核心線程池的數量為30個,不管有沒有用戶連接,我們總是保證30個連接,這個就是核心線程數,這里的核心線程數不一定是30你可以根據你的需求、業務和并發訪問量來設置,先判斷線程池中核心線程池所有的線程是否都在執行任務,如果不是,則新創建一個線程執行剛提交的任務,否則,核心線程池中所有的線程都在執行任務,則進入第2步;
- 2、如果我們核心線程數的30個數量已經滿了,就需要到阻塞隊列中去查看,判斷當前阻塞隊列是否已滿,如果未滿,則將提交的任務放置在阻塞隊列中等待執行;否則,則進入第3步;
- 3、判斷線程池中所有的線程是否都在執行任務,如果沒有,則創建一個新的線程來執行任務,否則,則交給飽和策略進行處理,也叫拒絕策略,等下我們會有詳細的介紹
注意: 這里有一個核心線程數和一個線程池數量,這兩個是不同的概念,核心線程數代表我能夠維護常用的線程開銷,而線程池數量則代表我最大能夠創建的線程數,例如在我們農村每家每戶都有吃水的井,基本上有半井深的水就可以維持我們的日常生活的使用,這里的半井深的水就好比我們的核心線程數,還有一半的容量是我們井能夠容納的最大水資源了,超過了就不行,水就會漫出來,這個就類似于我們的線程池的數量,不知道這里說明大家是否能夠更好的進行理解
三、線程池的分類
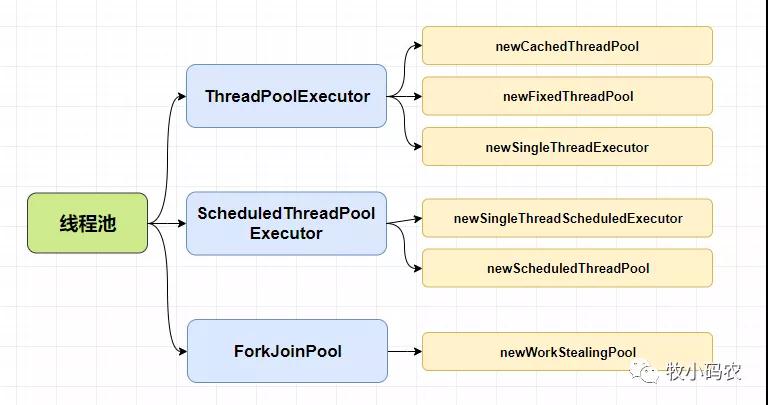
1.newCachedThreadPool: 創建一個可根據需要創建新線程的線程池,但是在以前構造的線程可用時講重用它們,并在需要時使用提供的ThreadFactory 創建新線程
特征:
(1) 線程池中的數量沒有固定,可以達到最大值(Integer.MAX_VALUE=2147483647)
(2) 線程池中的線程可進行緩存重復利用和回收(回收默認時間為1分鐘)
(3) 當線程池中,沒有可用線程,會重新創建一個線程
2.newFixedThreadPool: 創建一個可重用固定線程數的線程池,以共享的無界隊列方式來運行這些線程,在任意點,在大多數nThreads線程會處于處理任務的活動狀態。如果在所有線程處于活動狀態時提交附件任務,則在有可用線程之前,附件任務將在隊列中等待,如果在關閉前的執行期間由于失敗而導致任何線程終止,那么一個新線程將代替它執行后續的任務(如果需要)。在某個線程被顯式關閉之前,池中的線程將一直存在
特征:
(1) 線程池中的線程處于一定的量,可以很好的控制線程的并發量
(2) 線程可以重復被使用,在顯示關閉之前,都將一直存在
(3) 超過一定量的線程被提交時需在隊列中等待
3.newSingleThreadExecutor: 創建一個使用單個 worker 線程的Executor ,以無界隊列方式來運行該線程。(注意,如果因為在關閉前的執行期間出現失敗而終止了此單個線程,那么如果需要,一個新線程將代替它執行后續的任務)。可保證順序地執行各個任務,并且在任意給定的時間不會有多個線程是活動的,與其他等效的 newFixedThreadPool(1)不同,可保證無需重新配置此方法所返回的執行程序即可使用其他的線程
特征:
(1) 線程池中最多執行一個線程,之后提交的線程將會排在隊列中以此執行
4.newSingleThreadScheduledExecutor: 創建一個單線程執行程序,它可安排在給定延遲后運行命令或者定期執行
特征:
(1) 線程池中最多執行一個線程,之后提交的線程活動將會排在隊列中依次執行
(2) 可定時或者延遲執行線程活動
5.newScheduledThreadPool: 創建一個線程池,它可安排在給定延遲后運行命令或者定期的執行
特征:
(1) 線程池中具有執行數量的線程,即便是空線程也將保留
(2) 可定時或者延遲執行線程活動
6.newWorkStealingPool: 創建一個帶并行級別的線程池,并行級別決定了同一時刻最多有多少個線程在執行,如不傳并行級別參數,將默認為當前系統的CPU個數
我們可以在開發工具中搜索一個叫Executors的類,在里面我們可以看到我們上面所有的使用方法
四、ThreadPoolExecutor
線程工具類——Task :
- public class Task implements Runnable{
- @Override
- public void run() {
- try {
- //休眠1秒
- Thread.sleep(1000);
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- //輸出線程名
- System.out.println(Thread.currentThread().getName()+"-------running");
- }
- }
4.1 newCachedThreadPool
源碼實現:
- public static ExecutorService newCachedThreadPool() {
- return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
- 60L, TimeUnit.SECONDS,
- new SynchronousQueue<Runnable>());
- }
案例:
- public class CacheThreadPoolDemo {
- public static void main(String[] args) {
- ExecutorService executorService = Executors.newCachedThreadPool();
- for (int i = 0; i < 20; i++) {
- //提交任務
- executorService.execute(new Task());
- }
- //啟動有序關閉,其中先前提交的任務將被執行,但不會接受任何新任務
- executorService.shutdown();
- }
- }
結果輸出:
從開始到結束我們總共輸出了20個(pool-1-thread-1到pool-1-thread-20)線程
- pool-1-thread-2-------running
- pool-1-thread-6-------running
- pool-1-thread-1-------running
- pool-1-thread-3-------running
- pool-1-thread-5-------running
- pool-1-thread-4-------running
- pool-1-thread-7-------running
- pool-1-thread-11-------running
- pool-1-thread-9-------running
- pool-1-thread-10-------running
- pool-1-thread-17-------running
- pool-1-thread-15-------running
- pool-1-thread-18-------running
- pool-1-thread-16-------running
- pool-1-thread-8-------running
- pool-1-thread-20-------running
- pool-1-thread-13-------running
- pool-1-thread-19-------running
- pool-1-thread-14-------running
- pool-1-thread-12-------running
4.2 newFixedThreadPool
源碼實現:
- public static ExecutorService newFixedThreadPool(int nThreads) {
- return new ThreadPoolExecutor(nThreads, nThreads,
- 0L, TimeUnit.MILLISECONDS,
- new LinkedBlockingQueue<Runnable>());
- }
案例:
- public class FixedThreadPoolDemo {
- public static void main(String[] args) {
- //創建線程池,最多允許五個線程執行
- ExecutorService executorService = Executors.newFixedThreadPool(5);
- for (int i = 0; i < 20; i++) {
- //提交任務
- executorService.execute(new Task());
- }
- //啟動有序關閉,其中先前提交的任務將被執行,但不會接受任何新任務
- executorService.shutdown();
- }
- }
輸出結果:
我們可以看到其中的線程是每五個(pool-1-thread-1到pool-1-thread-5)一執行,在當前執行的線程運行中,最多允許五個線程進行執行
- pool-1-thread-4-------running
- pool-1-thread-2-------running
- pool-1-thread-1-------running
- pool-1-thread-3-------running
- pool-1-thread-5-------running
- pool-1-thread-4-------running
- pool-1-thread-5-------running
- pool-1-thread-3-------running
- pool-1-thread-2-------running
- pool-1-thread-1-------running
- pool-1-thread-4-------running
- pool-1-thread-2-------running
- pool-1-thread-1-------running
- pool-1-thread-3-------running
- pool-1-thread-5-------running
- pool-1-thread-4-------running
- pool-1-thread-5-------running
- pool-1-thread-2-------running
- pool-1-thread-1-------running
- pool-1-thread-3-------running
4.3 newSingleThreadExecutor
源碼實現:
- public static ExecutorService newSingleThreadExecutor() {
- return new FinalizableDelegatedExecutorService
- (new ThreadPoolExecutor(1, 1,
- 0L, TimeUnit.MILLISECONDS,
- new LinkedBlockingQueue<Runnable>()));
- }
案例:
- public class SingleThreadPoolDemo {
- public static void main(String[] args) {
- ExecutorService executorService = Executors.newSingleThreadExecutor();
- for (int i = 0; i < 20; i++) {
- //提交任務
- executorService.execute(new Task());
- }
- //啟動有序關閉,其中先前提交的任務將被執行,但不會接受任何新任務
- executorService.shutdown();
- }
- }
結果輸出:
我們可以看到每次都是線程1輸出結果
- pool-1-thread-1-------running
- pool-1-thread-1-------running
- pool-1-thread-1-------running
- pool-1-thread-1-------running
- pool-1-thread-1-------running
- pool-1-thread-1-------running
- pool-1-thread-1-------running
- pool-1-thread-1-------running
- pool-1-thread-1-------running
- pool-1-thread-1-------running
- pool-1-thread-1-------running
- pool-1-thread-1-------running
- pool-1-thread-1-------running
- pool-1-thread-1-------running
- pool-1-thread-1-------running
- pool-1-thread-1-------running
- pool-1-thread-1-------running
- pool-1-thread-1-------running
- pool-1-thread-1-------running
- pool-1-thread-1-------running
五、ScheduledThreadPoolExecutor
5.1 newScheduledThreadPool
案例:
- public static void main(String[] args) {
- ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(3);
- // for (int i = 0; i < 20; i++) {
- System.out.println(System.currentTimeMillis());
- scheduledExecutorService.schedule(new Runnable() {
- @Override
- public void run() {
- System.out.println("延遲三秒執行");
- System.out.println(System.currentTimeMillis());
- }
- },3, TimeUnit.SECONDS);
- // }
- scheduledExecutorService.shutdown();
- }
- }
輸出結果:
- 1606744468814
- 延遲三秒執行
- 1606744471815
5.2 newSingleThreadScheduledExecutor
案例:
- public static void main(String[] args) {
- ScheduledExecutorService scheduledExecutorService = Executors.newSingleThreadScheduledExecutor();
- scheduledExecutorService.scheduleAtFixedRate(new Runnable() {
- int i = 1;
- @Override
- public void run() {
- System.out.println(i);
- i++;
- }
- },0,1, TimeUnit.SECONDS);
- // scheduledExecutorService.shutdown();
- }
輸出結果:
- 1
- 2
- 3
- 4
- 5
六、線程池的生命周期
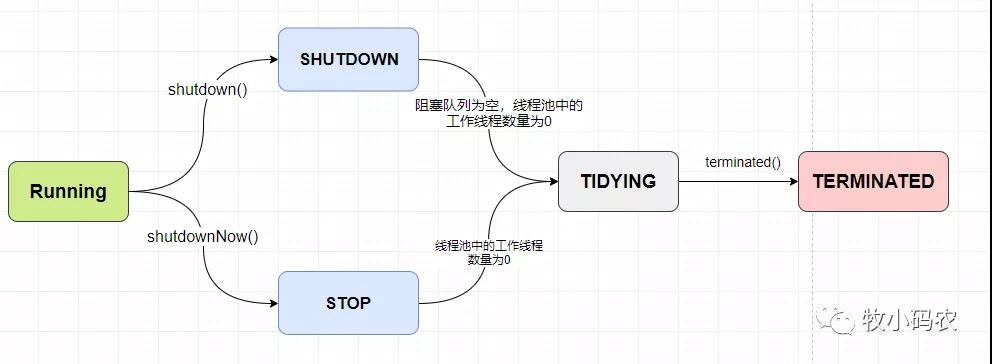
一般來說線程池只有兩種狀態,一種是Running,一種是TERMINATED,圖中間的都是過渡狀態
Running:能接受新提交的任務,并且也能處理阻塞隊列中的任務
SHUTDOWN:關閉狀態,不再接受新提交的任務,但卻可以繼續處理阻塞隊列中已保存的任務
STOP:不能接受新任務,也不處理隊列中的任務,會中斷正在處理任務的線程
TIDYING:如果所有的任務都已終止了,workerCount(有效線程數)為0.線程池進入該狀態后會調用terminated()方法進入TERMINATED狀態
TERMINATED:在terminated()方法執行完成后進入該狀態,默認terminated()方法中什么也沒有做
七、線程池的創建
7.1 Executors 源碼
- public ThreadPoolExecutor(int corePoolSize,
- int maximumPoolSize,
- long keepAliveTime,
- TimeUnit unit,
- BlockingQueue<Runnable> workQueue,
- ThreadFactory threadFactory,
- RejectedExecutionHandler handler)
7.2 參數說明
corePoolSize:核心線程池的大小
maximumPoolSize:線程池能創建線程的最大個數
keepAliveTime:空閑線程存活時間
unit:時間單位,為keepAliveTime指定時間單位
workQueue:阻塞隊列,用于保存任務的阻塞隊列
threadFactory:創建線程的工程類
handler:飽和策略(拒絕策略)
八、阻塞隊列
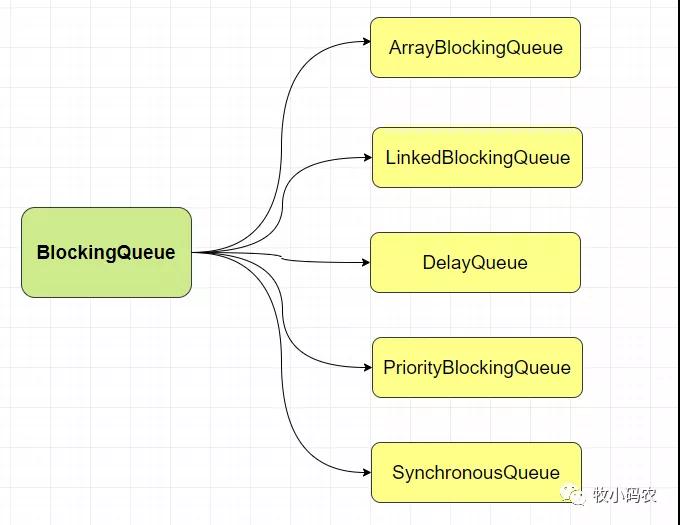
ArrayBlockingQueue:
基于數組的阻塞隊列實現,在ArrayBlockingQueue內部,維護了一個定長數組,以便緩存隊列中的數據對象,這是-個常用的阻塞隊列,除了一個定長數組外,ArrayBlockingQueue內部還保存著兩個整形變量,分別標識著隊列的頭部和尾部在數組中的位置。
ArrayBlockingQueue在生產者放入數據和消費者獲取數據,都是共用同一個鎖對象,由此也意味著兩者無法真正并行運行,這點尤其不同于LinkedBlockingQueue;按照實現原理來分析,ArrayBlockingQueue完全可以采用分離鎖,從而實現生產者和消費者操作的完全并行運行。Doug Lea之所以沒這樣去做,也許是因為ArrayBlockingQueue的數據寫入和獲取操作已經足夠輕巧,以至于引入獨立的鎖機制,除了給代碼帶來額外的復雜性外,其在性能上完全占不到任何便宜。
ArrayBlockingQueue和LinkedBlockingQueue間還有一個明顯的不同之處在于,前者在插入或刪除元素時不會產生或銷毀任何額外的對象實例,而后者則會生成一個額外的Node對象。這在長時間內需要高效并發地處理大批量數據的系統中,其對于GC的影響還是存在一定的區別。而在創建ArrayBlockingQueue時,我們還可以控制對象的內部鎖是否采用公平鎖,默認采用非公平鎖。
LinkedBlockingQueue:
基于鏈表的阻塞隊列,同ArrayListBlockingQueue類似,其內部也維持著一個數據緩沖隊列(該隊列由一個鏈表構成),當生產者往隊列中放入一個數據時,隊列會從生產者手中獲取數據,并緩存在隊列內部,而生產者立即返回;只有當隊列緩沖區達到最大值緩存容量時( LinkedBlockingQueue可以通過構造函數指定該值),才會阻塞生產者隊列,直到消費者從隊列中消費掉─份數據,生產者線程會被喚醒,反之對打于消費者這端的處理也基于同樣的原理。而
LinkedBlockingQueue之所以能夠高效的處理并發數據,還因為其對于生產者端和消費者端分別采用了獨立的鎖來控制數據同步,這也意味著在高并發的情況下生產者和消費者可以并行地操作隊列中的數據,以此來提高整個隊列的并發性能。
DelayQueue:
DelayQueue中的元素只有當其指定的延遲時間到了,才能夠從隊列中獲取到該元素。DelayQueue是一個沒有大小限制的隊列,因此往隊列中插入數據的操作(生產者)永遠不會被阻塞,而只有獲取數據的操作(消費者)才會被阻塞。
使用場景︰
DelayQueue使用場景較少,但都相當巧妙,常見的例子比如使用一個DelayQueue來管理一個超時未響應的連接隊列。
PriorityBlockingQueue:
基于優先級的阻塞隊列(優先級的判斷通過構造函數傳入的Compator對象來決定),但需要注意的是
PriorityBlockingQueue并不會阻塞數據生產者,而只會在沒有可消費的數據時,阻塞數據的消費者。因此使用的時候要特別注意,生產者生產數據的速度絕對不能快于消費者消費數據的速度,否則時間一長,會最終耗盡所有的可用堆內存空間。在實現PriorityBlockingQueue時,內部控制線程同步的鎖采用的是公平鎖。
SynchronousQueue:
一種無緩沖的等待隊列,類似于無中介的直接交易,有點像原始社會中的生產者和消費者,生產者拿著產品去集市銷售給產品的最終消費者,而消費者必須親自去集市找到所要商品的直接生產者,如果一方沒有找到合適的目標,那么對不起,大家都在集市等待。相對于有緩沖的BlockingQueue來說,少了一個中間經銷商的環節(緩沖區),如果有經銷商,生產者直接把產品批發給經銷商,而無需在意經銷商最終會將這些產品賣給那些消費者,由于經銷商可以庫存一部分商品,因此相對于直接交易模式,總體來說采用中間經銷商的模式會吞吐量高一些(可以批量買賣)﹔但另一方面,又因為經銷商的引入,使得產品從生產者到消費者中間增加了額外的交易環節,單個產品的及時響應性能可能會降低。
聲明一個SynchronousQueue有兩種不同的方式,它們之間有著不太一樣的行為。公平模式和非公平模式的區別:如果采用公平模式:SynchronousQueue會采用公平鎖,并配合一個FIFO隊列來阻塞多余的生產者和消費者,從而體系整體的公平策略;
但如果是非公平模式 ( SynchronousQueue默認) : SynchronousQueue采用非公平鎖,同時配合一個LIFO隊列來管理多余的生產者和消費者,而后一種模式,如果生產者和消費者的處理速度有差距,則很容易出現饑渴的情況,即可能有某些生產者或者是消費者的數據永遠都得不到處理。
注意:
arrayblockingqueue和linkedblockqueue的區別:1.隊列中鎖的實現不同
1、ArrayBlockingQueue實現的隊列中的鎖是沒有分離的,即生產和消費用的是同一個鎖;
LinkedBlockingQueue實現的隊列中的鎖是分離的,即生產用的是putLock,消費是takeLock2.隊列大小初始化方式不同
2、ArrayBlockingQueue實現的隊列中必須指定隊列的大小;
LinkedBlockingQueue實現的隊列中可以不指定隊列的大小,但是默認是Integer.MAX_VALUE
九、拒絕策略
ThreadPoolExecutor.AbortPolicy(系統默認):丟棄任務并拋出RejectedExecutionException異常,讓你感知到任務被拒絕了,我們可以根據業務邏輯選擇重試或者放棄提交等策略
ThreadPoolExecutor.DiscardPolicy: 也是丟棄任務,但是不拋出異常,相對而言存在一定的風險,因為我們提交的時候根本不知道這個任務會被丟棄,可能造成數據丟失。
ThreadPoolExecutor.DiscardOldestPolicy: 丟棄隊列最前面的任務,然后重新嘗試執行任務(重復此過程),通常是存活時間最長的任務,它也存在一定的數據丟失風險
ThreadPoolExecutor.CallerRunsPolicy: 由調用線程處理該任務
十、execute()和submit()方法
10.1 execute方法執行邏輯
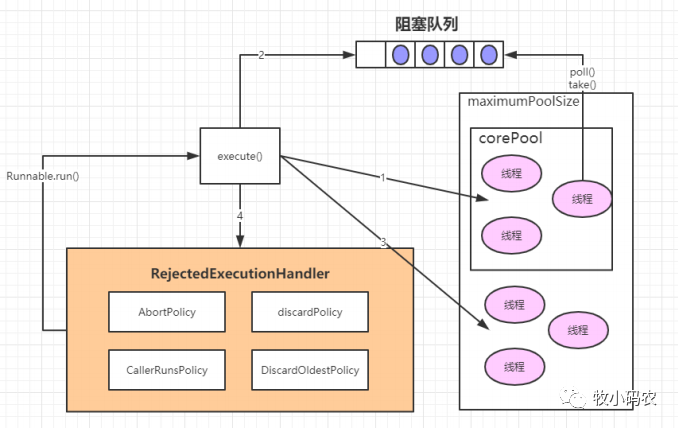
- 如果當前運行的線程少于corePoolSize,則會創建新的線程來執行新的任務;
- 如果運行的線程個數等于或者大于corePoolSize,則會將提交的任務存放到阻塞隊列workQueue中;
- 如果當前workQueue隊列已滿的話,則會創建新的線程來執行任務;
- 如果線程個數已經超過了maximumPoolSize,則會使用飽和策略RejectedExecutionHandler來進行處理
10.2 Submit
submit是基方法Executor.execute(Runnable)的延伸,通過創建并返回一個Future類對象可用于取消執行和/或等待完成。
十一、線程池的關閉
- 關閉線程池,可以通過shutdown和shutdownNow兩個方法
- 原理:遍歷線程池中的所有線程,然后依次中斷
- 1、shutdownNow首先將線程池的狀態設置為STOP,然后嘗試停止所有的正在執行和未執行任務的線程,并返回等待執行任務的列表;
- 2、shutdown只是將線程池的狀態設置為SHUTDOWN狀態,然后中斷所有沒有正在執行任務的線程