













全球超大的公開人臉數據集 | 清華大學&芯翌科技聯合發布
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
人臉識別領域,中國隊再次傳來捷報。
全球最大規模人臉數據集發布。
首次包含數百萬ID和數億圖片。

這就是由芯翌科技與清華大學自動化系智能視覺實驗室合作,所推出的 WebFace 260M,相關研究已被CVPR 2021接收。
并且,基于其所清洗的數據集 WebFace42M,在最具挑戰IJBC測試集上,也已經達到了SOTA水平。
而它所帶來的“全球之最”還不止于此。
以這項數據集為基礎,芯翌科技在最新一期的NIST-FRVT榜單上,戴口罩人臉識別評測中斬獲世界第一。
全球之最的人臉數據集,長什么樣?
WebFace260M這個數據集,是完全基于全球互聯網公開人臉數據。
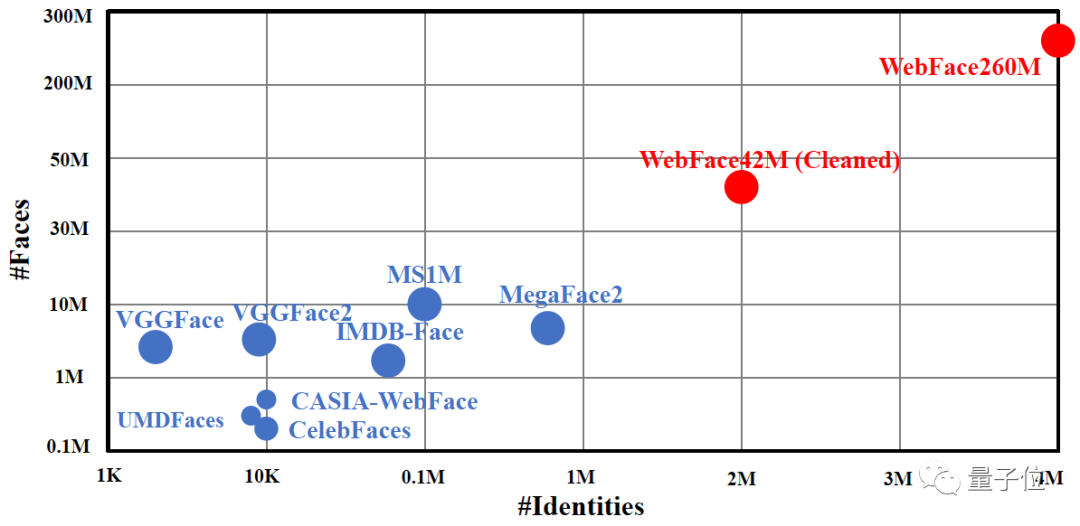
它的問世,一舉打破了此前人臉數據集的規模:
不僅規模最大,也是首次在人臉ID數目和圖片數,分別達到了400萬和2.6億的規模。
此外,研究人員還提出了基于自訓練全自動迭代的清洗流程 (Cleaning Automatically by Self-Training, CAST)。這種方法的靈感來自于對互聯網人臉數據的觀察和分析。
WebFace260M數據提供了粗糙的分類,可以基于此作為清洗算法的初始結構。另外,研究人員發現,在大規模含噪聲人臉數據清洗中,嵌入特征顯得十分重要,而這個特征可以通過同時迭代數據和模型得到增強。因此,整個清洗流程如下圖所示:
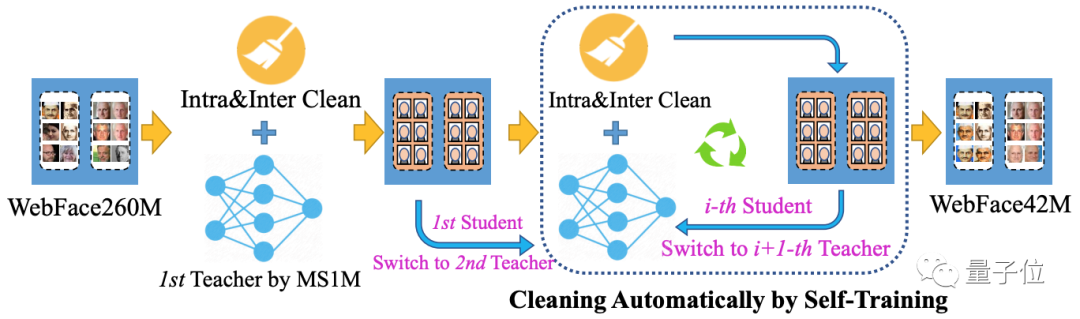
- 首先,利用名為MS1M的公開數據集訓練一個“教師模型”,并對原始WebFace260M進行清洗。
- 其次,利用一個“學生模型”,在上一步清洗過的圖像上進行訓練。
- 最后,讓“學生模型”切換為“教師模型”,并進行迭代,直到獲得高質量的WebFace42M。
通過這種方式,在對WebFace260M進行清洗操作后,便得到了WebFace42M。
據介紹,它是目前全球規模最大、可直接用于訓練的干凈人臉數據集:
包含200萬ID、4200萬圖片。
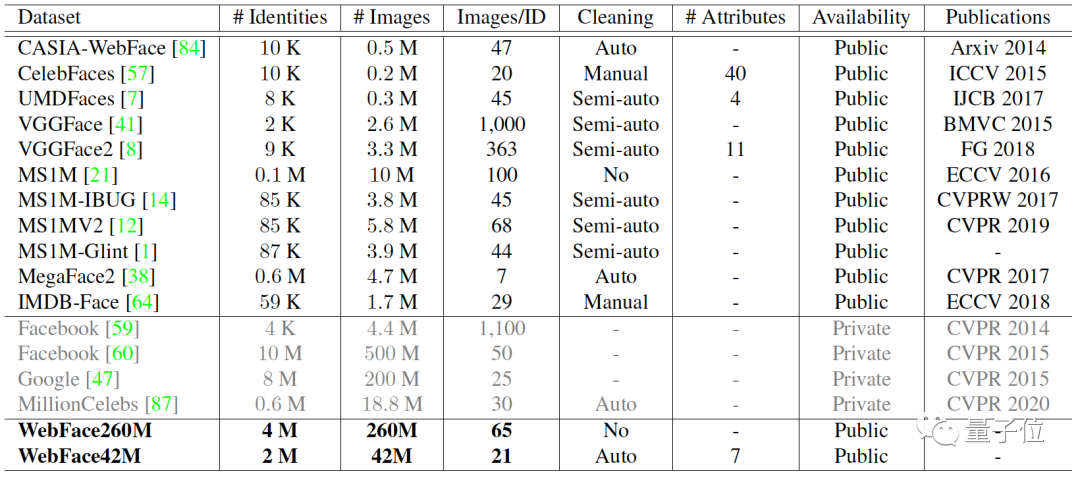
關于WebFace260M和WebFace42M的“世界之最”,一張表格的數據對比,便可一目了然:
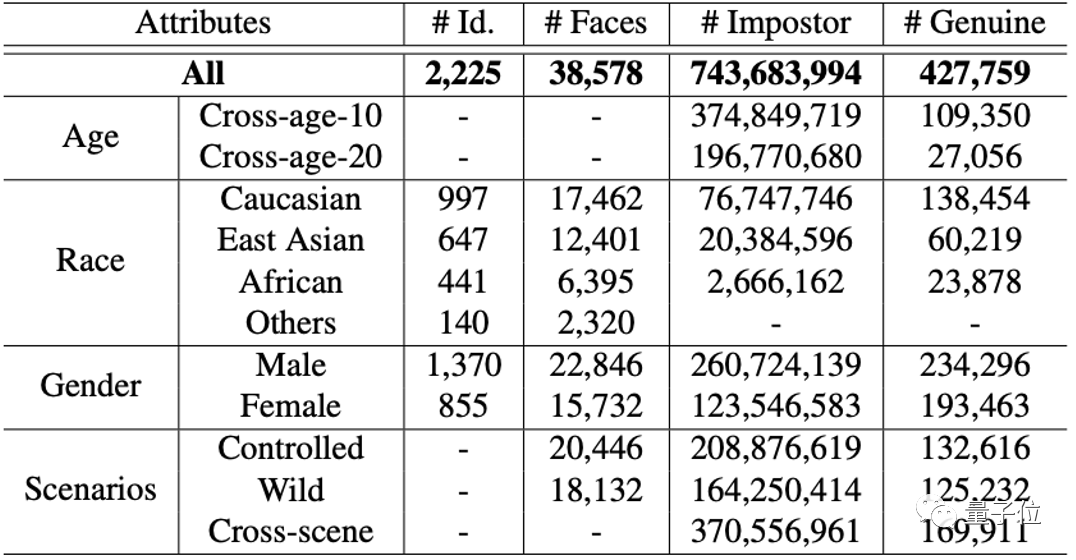
同時,針對目前人臉識別的評測問題,研究人員發布了更貼近實際應用的“時間受限人臉識別評測準則”-FRUITS (Face Recognition Under Inference Time conStraint),和分布更廣泛、更具挑戰性、分類更細致的人臉測試集,這將推動人臉識別評測更靠近真實場景。
同時,研究人員將持續維護、迭代和升級該測試集以及評測系統,持續助力行業技術發展。
這樣的數據集,好用嗎?
對于這個問題,答案是肯定,而且是得到了非常專業的實踐和認可的那種。
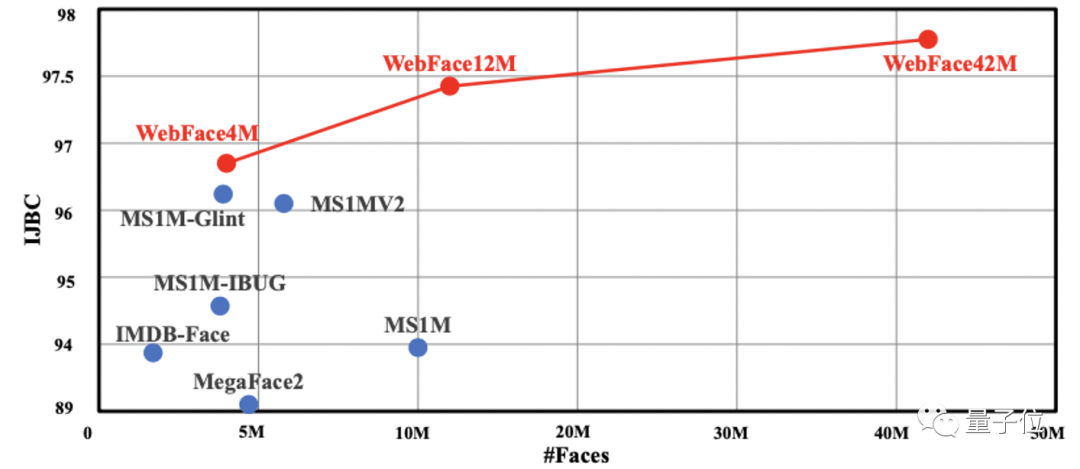
以WebFace42M為例,它能夠在目前公開的、最具挑戰性的IJBC測試集上,達到新的SOTA,相對錯誤率還降低了40%。
除此之外,有一個叫做NIST-FRVT的比賽,是由美國國家標準與技術研究院主辦,素來有著“人臉識別黃金賽事”的別稱。
因為它具有測評集非對外公開、提交頻率嚴格限制、計算時間嚴格限制等諸多嚴苛要求,所以可以稱得上是全球標準最嚴、最具權威的人臉識別算法評測。
那么當WebFace42M的數據,遇到如此棘手的賽事,又會擦出怎樣的火花呢?
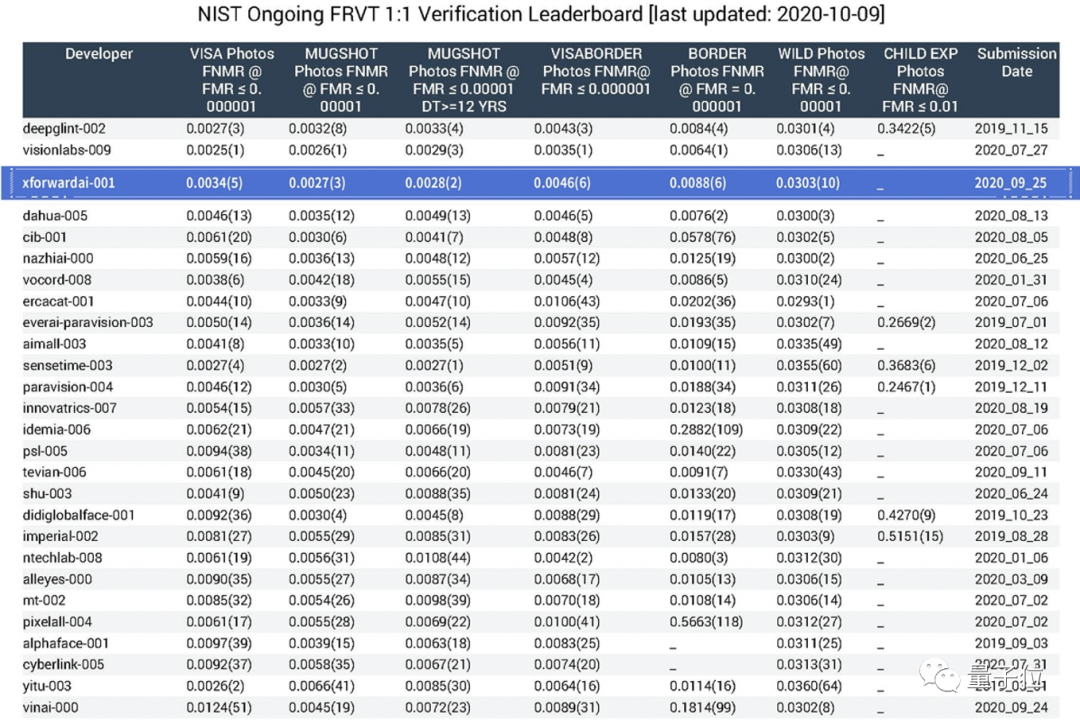
早在去年10月份,僅用WebFace42M的數據,芯翌科技便在NIST-FRVT的榜單上取得了前三名的成績。
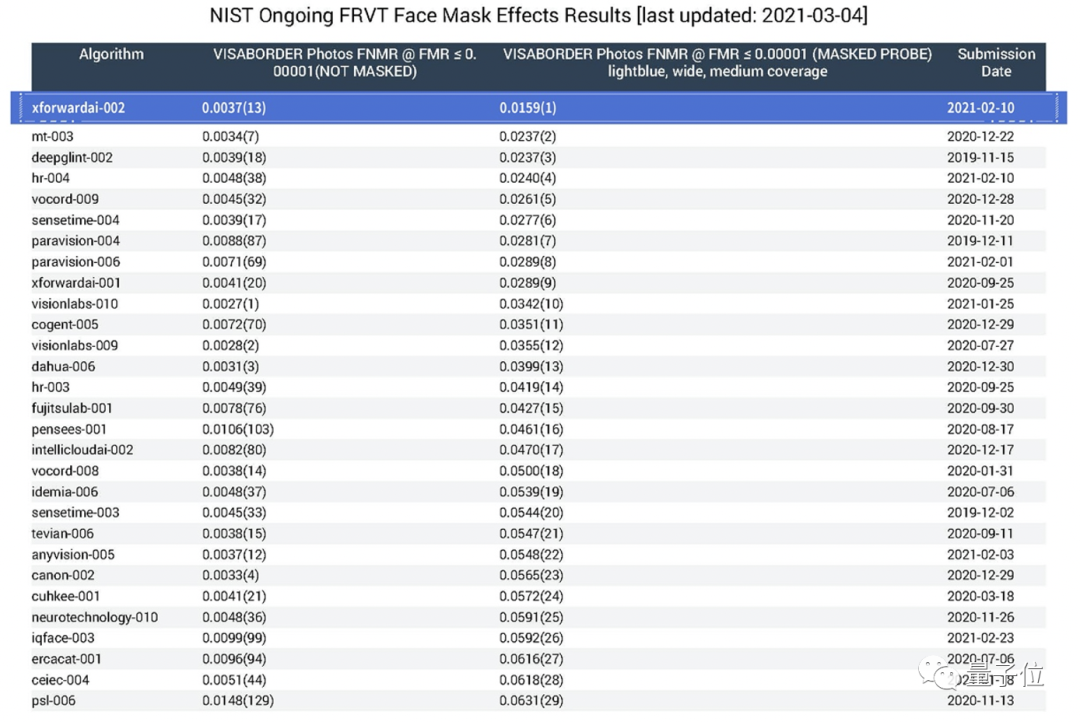
而在剛剛最新一期的NIST-FRVT榜單上,以WebFace42M為基礎,在“戴口罩人臉識別評測”中又一次創造了“世界之最”——奪得比賽冠軍。
而且從數據中不難看出,與第二名的成績可以說是兩個量級。
除此之外,在1:1人臉識別評測中,也取得了綜合排名世界前三的成績。
為什么要做這樣的數據集?
人臉識別,這項技術可以說是真的火。
火到已經步入人們日常生活,打卡、開門禁、解鎖手機等等,都成了它大展拳腳的地方。
也正因如此,學術、工業界的科研工作者,在人臉識別的精度和速度上,形成了競相追逐的狀態。
而據研究表明,人臉數據集對于上述的影響是最大的。特別是在目前以深度學習為核心的人工智能研發模式下,軟件開發會逐漸從傳統的軟件1.0,過渡到以數據為核心的“數據即代碼,模型即軟件”的軟件2.0時代。
然而在數據集這塊,目前的現狀卻是:
公開數據規模和實際人臉識別系統所需數據規模,差距過大。
怎么說?
例如在WebFace260M發布之前,公開的數據規模都是較小,此前規模最大的就是MegaFace2和MS1M。
MegaFace2擁有67.2萬ID和470萬圖片,MS1M擁有10萬 ID和1000萬圖片。
如此規模的公開數據,對于科研人員來說,是遠遠無法滿足實際人臉識別系統的數據需求。
同時這也只是限制人臉識別技術發展的瓶頸之一,評測準則和測試集也是重要因素。
目前公開的人臉識別評測集,包括LFW、CFP、AgeDB、RFW、MegaFace、IJB系列等,在精度上基本已經比較飽和。
同時,還存在不同場景下表現不夠細致的情況。
因此,WebFace260M和WebFace42M以及相關Benchmark的推出,在一定程度上可以說是拉近了公開數據集規模與實際應用產業界的這條鴻溝,進一步推動以深度學習為核心的人臉識別相關技術的進步,促進智能化行業的繁榮發展。
而比起規模的上突破,更大的意義應該在于“科技向善”、“數據生態”。
經過過去幾年的發展,人臉識別以及人工智能技術取得了巨大的進步,也產生了顯著的社會經濟價值,但是也出現了很多由于技術發展帶來的社會問題。
團隊希望通過這個數據集的建立和相關工作,和產業界以及社會各界一起,構建人臉識別測試和應用標準,規范人臉識別應用市場,治理人臉識別應用亂象,科技向善,凸顯人工智能技術的價值和溫度。
更進一步來講,在現今數字經濟和智能化高速發展的當下,數字資源已然成為像水、電一樣的必需品;同時又像石油一般的寶貴,需要有規劃地去生產、使用、分享和交易等。
但現在目前的狀況是,國內外普遍對此的重視程度不夠,具體而言包括行業規范不標準、分享程度不足,也沒有長期的規劃,由此便反過來抑制了數字經濟和智能化的發展進程。
目前國家層面非常鼓勵和重視數據集的創新和規范,清華大學和芯翌科技的研究人員也積極響應國家的號召和政策的要求,希望和國家、政府機構、學術界以及產業界一起,打造智能化時代開放、共享、安全的數據生態。
網站地址:
https://www.face-benchmark.org
論文地址:
https://arxiv.org/abs/2103.04098




















