微軟分享超大基于Transformer架構的語言生成模型
本文轉自雷鋒網,如需轉載請至雷鋒網官網申請授權。
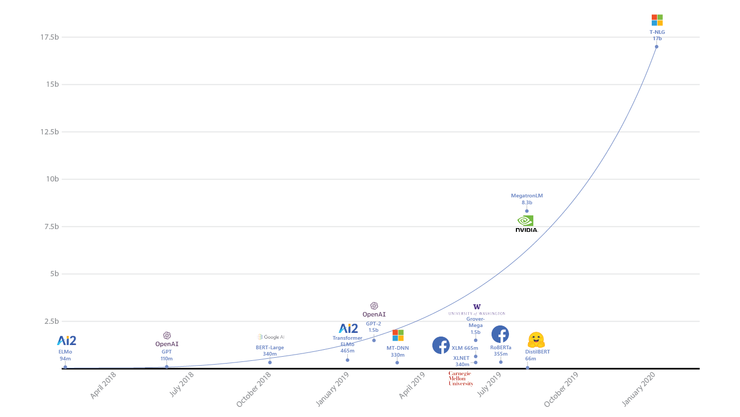
微軟 AI&Research 今天分享了有史以來最大的基于 Transformer 架構的語言生成模型 Turing NLG(下文簡稱為T-NLG),并開源了一個名為 DeepSpeed 的深度學習庫,以簡化對大型模型的分布式培訓。
基于 Transformer 的架構,意味著該模型可以生成單詞來完成開放式文本任務。除了完成未完成的句子外,它還可以生成對輸入文檔的問題和摘要的直接答案。
去年 8 月,英偉達曾宣布已訓練世界上最大的基于 Transformer 的語言模型,當時該模型使用了 83 億個參數,比 BERT 大 24 倍,比 OpenAI 的 GPT-2 大 5 倍。
而此次微軟所分享的模型,T-NLG 的參數為 170 億個,是英偉達的 Megatron(現在是第二大 Transformer 模型)的兩倍,其參數是 OpenAI 的 GPT-2 的十倍。微軟表示,T-NLG 在各種語言建模基準上均優于最新技術,并在應用于許多實際任務(包括總結和問題解答)時表現出色。
不過,像 Google 的 Meena 一樣,最初使用 GPT-2,T-NLG 最初只能在私人演示中共享。
微軟 AI 研究應用科學家 Corby Rosset 在博客文章中寫道:“除了通過匯總文檔和電子郵件來節省用戶時間之外,T-NLG 還可以通過為作者提供寫作幫助,并回答讀者可能對文檔提出的問題,由此來增強 Microsoft Office 套件的使用體驗。”
具有 Transformer 架構的語言生成模型可以預測下一個單詞。它們可用于編寫故事,以完整的句子生成答案以及總結文本。
微軟表示,他們的目標是在任何情況下都能夠像人類一樣直接,準確,流暢地做出響應:以前,問題解答和摘要系統依賴于從文檔中提取現有內容,這些內容可以作為備用答案或摘要,但它們通常看起來不自然或不連貫。使用T-NLG 這樣的自然語言生成模型,可以自然地總結或回答有關個人文檔或電子郵件主題的問題。
來自 AI 領域的專家告訴 VentureBeat,2019 年是 NLP 模型開創性的一年——使用 Transformer 架構無疑是 2019 年最大的機器學習趨勢之一,這導致了語言生成領域和 GLUE 基準測試領導者的進步,Facebook 的 RoBERTa、谷歌的 XLNet 和微軟的 MT-DNN 都紛紛加入到各類基準測試榜首的爭奪當中。
同樣是在今天,微軟還開源了一個名為 DeepSpeed 的深度學習庫。該學習庫已針對開發人員進行了優化,以提供低延遲、高吞吐量的推理。
DeepSpeed 包含零冗余優化器(ZeRO),用于大規模訓練具有 1 億個或更多參數的模型,微軟過去曾用它訓練T-NLG。
微軟表示,DeepSpeed 和 ZeRO 使得他們能夠降低模型并行度(從 16 降低到4),將每個節點的批處理大小增加四倍,并將訓練時間減少了三分之二;DeepSpeed 使用更少的 GPU 可以使大型模型的訓練效率更高。
開發人員和機器學習從業人員都可以使用 DeepSpeed 和 ZeRO,因為培訓大型網絡(例如利用 Transformer 架構的網絡)可能會很昂貴,并且可能會遇到大規模問題。
另外,Google 的 DeepMind 今天也發布了一種新的遠程內存模型 Compressive Transformer,以及一種針對書本級語言建模的新基準 PG19。