













ICCV 2021 | 基于生成數據的人臉識別
本文轉自雷鋒網,如需轉載請至雷鋒網官網申請授權。
本文是對發表于計算機視覺領域頂級會議ICCV 2021的論文“SynFace: Face Recognition with Synthetic Data” (基于生成數據的人臉識別)的解讀。

該論文由于京東探索研究院聯合悉尼大學以及騰訊數據平臺部完成,針對當前用來訓練人臉識別模型的真實人臉數據存在隱私權限、標簽噪聲和長尾分布等問題,提出利用生成仿真的人臉數據來代替真實數據去對人臉模型進行訓練。文中通過引入Identity Mixup以及Domain Mixup極大地縮小了生成數據訓練得到的模型與真實數據得到模型的準確率差距,并且系統性的分析了訓練數據中各種特性對識別準確率的影響。
論文鏈接:https://arxiv.org/abs/2108.07960
1
研究背景
近年來,人臉識別任務取得了巨大進展,其中大規模人臉訓練數據集扮演了非常重要的角色。但是由于近期來越發被重視的隱私問題,即人臉訓練數據集的使用需要得到該數據集所包含的所有人的授權同意,部分大規模的數據集[1]已經從其官網下架,無法再訪問。另外這類從互聯網上收集而來的數據集,還存在標簽噪聲以及長尾分布(即各個類別所包含的樣本數量差距很大)等問題,如若沒有妥善地去設計網絡結構或者損失函數,那么必然帶來識別準確率的下降。再者這些數據沒有人臉具體特性的標注(如表情,姿態,光照條件等),故而使得我們無法去系統性地分析這些因素在人臉識別里面的具體影響。
2
探索分析
為了解決上述問題,我們準備引入生成數據代替真實數據來進行人臉識別模型的訓練。近些年來,基于GAN[2]的生成模型發展十分迅猛,其生成得到的人臉圖片在某些場景下已經可以做到以假亂真的效果,參見圖1。

圖1:第一行為真實人臉,第二行則是生成人臉
為了能進一步控制生成人臉的各種特性(如身份,表情,姿態和光照條件),我們采用了DiscoFaceGAN[3]作為基本的生成模型,先與真實數據訓練得到的模型進行對比分析。RealFace和SynFace分別代表利用真實和生成數據訓練所得到的模型,然后在真實以及生成的測試集上進行評估,結果參見表1。

表1:對真實以及生成數據訓練得到模型進行交叉領域的評估結果
由實驗結果我們可以發現,兩者之間識別準確率的差距是由于真實數據與生成數據兩種不同領域的差異造成。通過進一步觀察生成的人臉,我們發現同一類(即同一個人)中的樣本人臉差異性較小,即類內距離較小。我們利用MDS[4]可視化了真實數據與生成數據的深度特征,參見圖2中綠色五邊形以及青色三角形。顯而易見,生成數據的類內距離明顯小于真實數據。
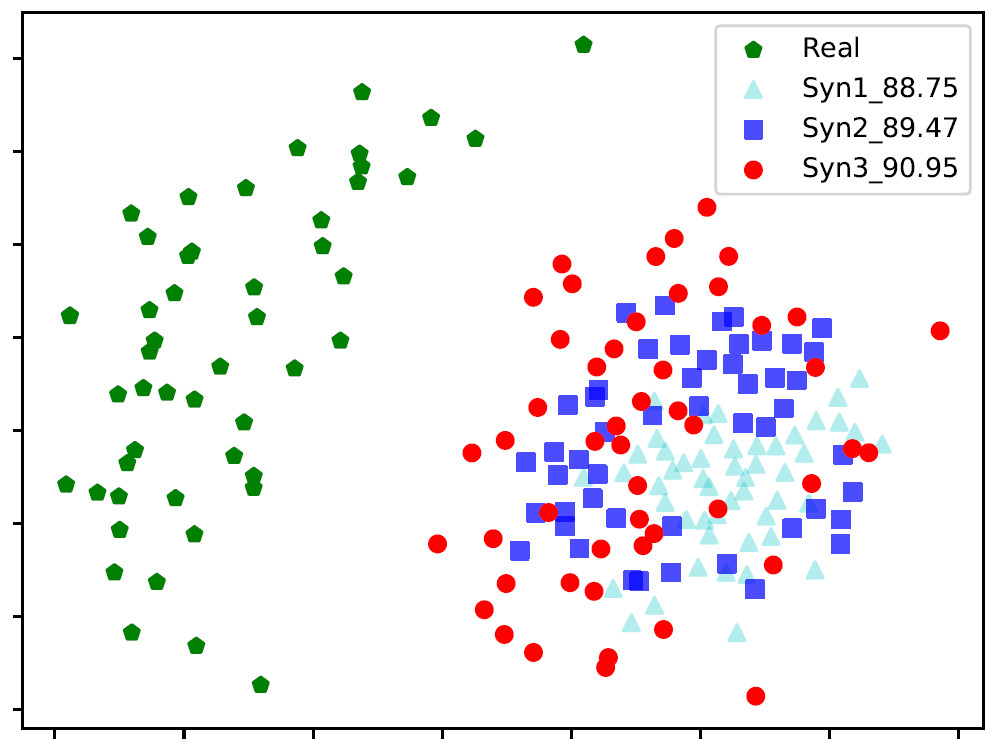
圖2:真實數據以及三類不同生成數據的深度特征可視化
3
方法介紹
Identity Mixup (身份混合)
為了增大生成數據的類內距離,受到Mixup[5]的啟發,我們在生成人臉模型的身份系數空間引入mixup,即Identity Mixup (IM),得到Mixup Face Generator。對于兩個身份系數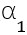 和
和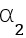 ,我們得到其中間態(內插值)作為一個新身份系數,其對應的標簽也隨之線性改變,參見公式1。另外我們通過可視化發現,如此得到的新身份系數同樣能夠生成高質量的人臉圖片,而且其身份信息隨著權重系數的變化,逐漸從一個身份變化到另一個身份,參見圖3。
,我們得到其中間態(內插值)作為一個新身份系數,其對應的標簽也隨之線性改變,參見公式1。另外我們通過可視化發現,如此得到的新身份系數同樣能夠生成高質量的人臉圖片,而且其身份信息隨著權重系數的變化,逐漸從一個身份變化到另一個身份,參見圖3。
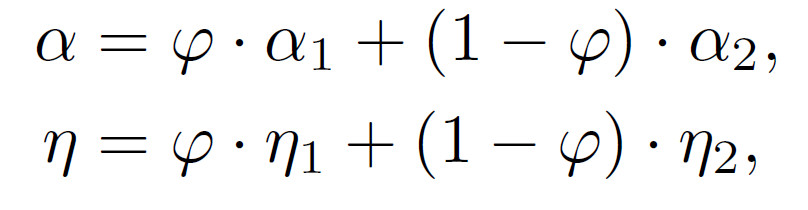
公式1:身份系數空間的mixup

圖3:身份隨著Identity Mixup的權重的改變而平滑過渡
為了驗證IM能夠增大生成人臉數據的類內距離,我們可視化了三種不同程度(通過系數調節)IM后生成人臉的特征(參見圖2)。我們可以看到從青色三角形到藍色正方形,再到紅色圓圈,它們的類內距離是逐漸增大的,相應的準確率也從88.75到89.47再到90.95,充分說明了IM能夠增大類內距離從而來提高識別準確率。另外從表2也可以看到,加入IM后,識別準確率從88.98大幅度提升至91.97。后續的圖5圖6以及表3的實驗結果也同樣證明了IM的有效性。
Domain Mixup (領域混合)
為了進一步縮小用生成數據訓練得到模型與真實數據得到模型之間的準確率差距,我們引入了Domain Mixup(DM)作為一種通用的domain adaptation(領域適應)的方法來緩解。具體來說,我們僅利用一小部分帶有標注的真實數據加上大規模的生成數據,通過DM的方式來訓練模型,DM具體數學形式參見公式2,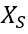 和
和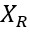 分別代表生成和真實的人臉圖片,其對應的標簽也隨之線性改變。
分別代表生成和真實的人臉圖片,其對應的標簽也隨之線性改變。
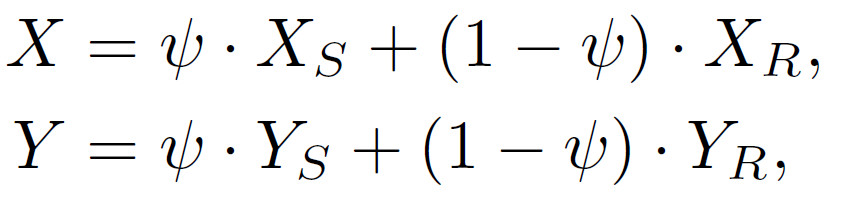
公式2:領域空間的mixup
于是我們利用DM來混合真實與生成數據來進行模型訓練,與只用真實數據訓練模型得到的對比結果如表2. 可以觀察得到,我們引入的DM能夠極大且穩定地提升在各種不同設置下的準確率。
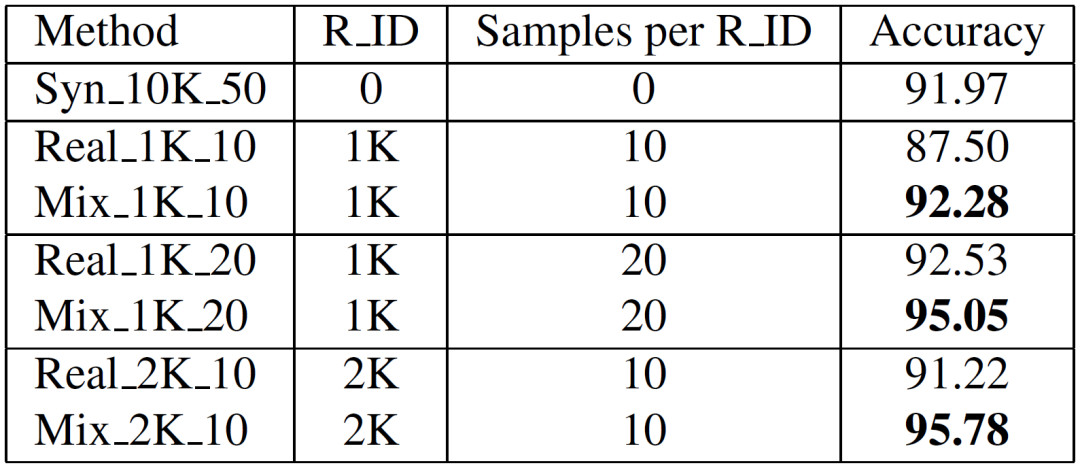
表2:利用真實數據以及混合數據訓練得到模型的準確率
比如最后一組實驗中,95.78相較于91.22的提升非常大。我們推測這是由于混合小部分真實數據能夠給生成數據帶來真實世界的外觀信息比如模糊和光照等,如此一來縮小了兩個領域的差異,進而提升了準確率。如果我們繼續增加真實數據到2K_20,那么準確率可以從95.78進一步提升至97.65。整體流程圖包括Identity Mixup以及Domain Mixup可參見圖4.
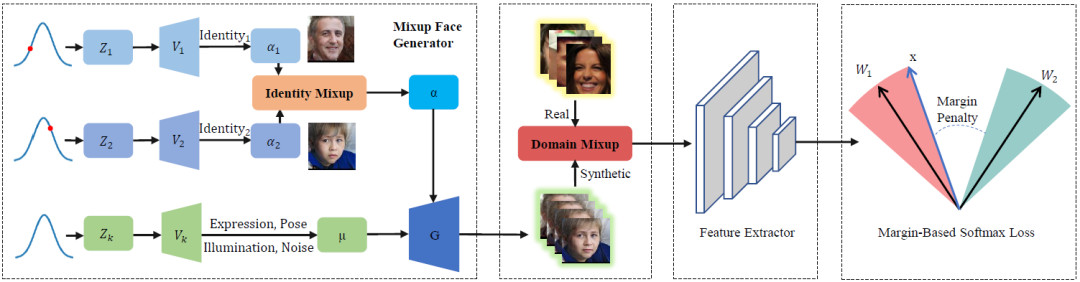
圖4:整個框架流程圖
4
實驗分析
利用我們得到的Mixup Face Generator,我們可以控制生成人臉的數量,身份,表情,姿態以及光照,故而接下來我們來系統性地分析這些因素在人臉識別任務中的具體影響。
首先我們來分析長尾分布的問題,由于真實人臉數據基本都是從互聯網上收集而來,導致某些類(人)擁有大量樣本,某些類則只有少數幾個樣本,這樣不平衡的分布訓練得到的模型性能較差。我們控制生成數據每個類別樣本數量來模擬這一問題,如圖5, 2K_UB1到2K_UB2再到2K_50,它們的分布越來越平衡,可以看出它們對應的準確率也是逐步上升。通過控制生成數據的類別樣本數量,我們可以天然地避免長尾分布帶來的問題。此外通過引入Identity Mixup (IM),所有的設置都得到了大幅度的提升。
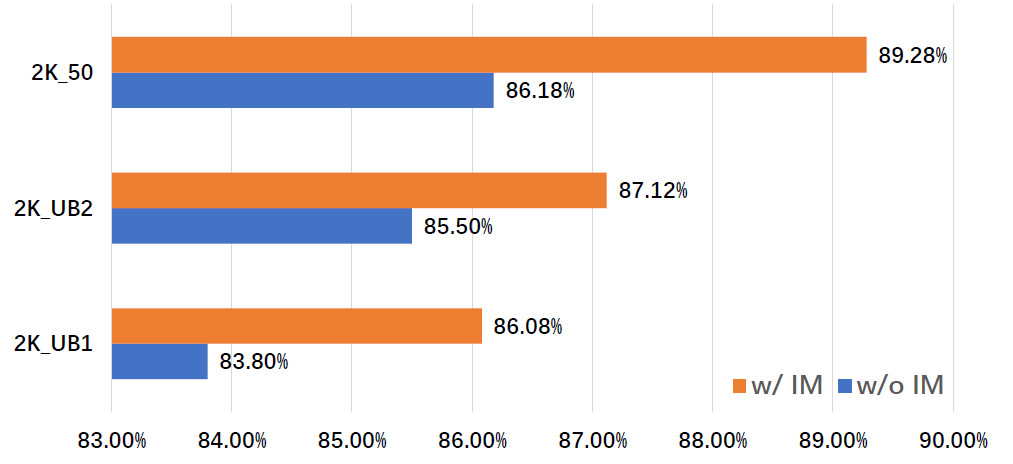
圖5:長尾分布問題
然后我們再來探索生成數據集的寬度(即類別數量)和深度(即類內樣本數量)對識別準確率的影響,參見表3. 可以看到隨著深度和寬度的增加,準確率都是逐步上升的。但是深度在達到20之后,準確率就開始出現飽和。另外我們通過觀察(a)(e)可以看到,它們具有相同數量的總樣本(50K),但是(a)極大地超過了(e),差距為4.37,說明了寬度相比深度承擔了更重要的角色。另外通過引入Identity Mixup (IM),我們可以看到所有的設置都得到了很大地提升,再次說明了IM的有效性。
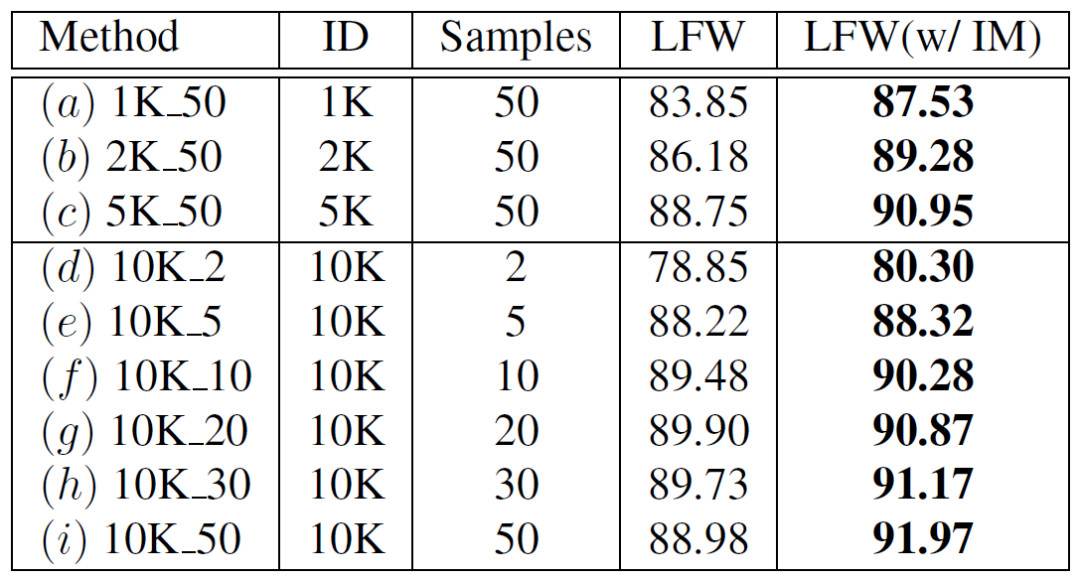
表3:生成數據集的寬度以及深度探索
最后我們分析了生成人臉各個特性(即表情,姿態和光照)的影響,我們通過保持其他特性不變,只改變當前探索的特性。比如Expression就是該類內保持其他姿態和光照等不變,只變化表情得到的生成數據,它們訓練得到的模型準確率參見圖6. 可以看到什么都不變(Non)和只變表情取得了最差的結果,這是因為這里生成的表情種類十分有限,基本上是微笑,故而可以等價成什么都不變。改變姿態和光照取得了巨大提升,這可能是因為測試數據集中的姿態和光照變化非常大的緣故。同樣地,引入IM帶來了穩定的提升,并且都達到了相似的準確率。潛在的原因是IM可以被視作為一種很強的數據增強,減少了各個特性對最終準確率的影響。
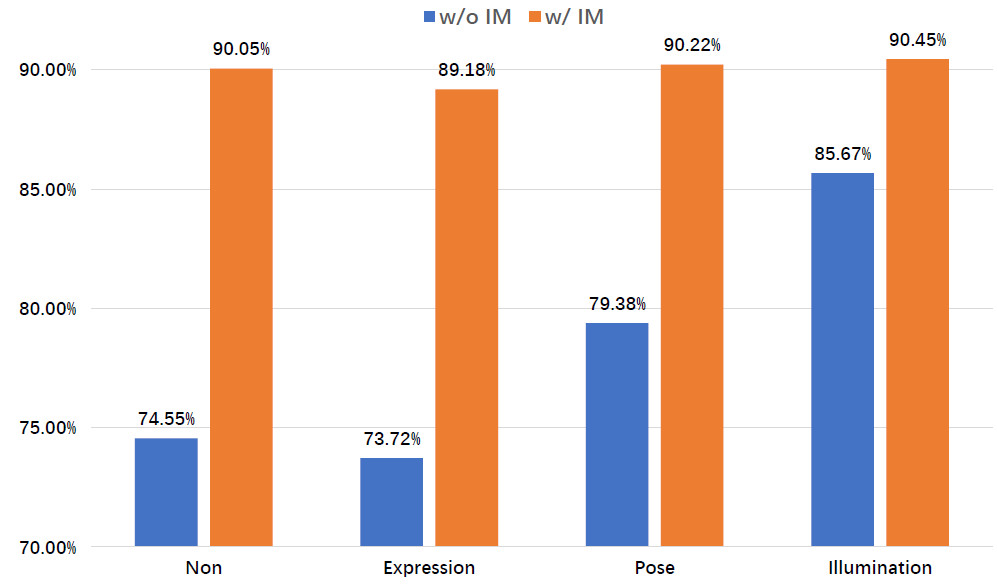
圖6:生成人臉不同特性的對比實驗
5
結語
在本文中我們探索了如何利用生成仿真的人臉數據來有效地訓練人臉識別模型。通過相關實驗結果對比分析,我們提出Identity Mixup來增加生成數據的類內距離,并引入Domain Mixup進一步縮小生成數據與真實數據的領域差異,兩者皆大幅度地提升了識別準確率,極大地縮小了與真實數據訓練所得到模型的差距。此外我們對于人臉的不同特性進行了系統性分析,揭示了訓練數據集的深度與寬度對于最終識別率都有很大影響,隨著兩者的增加,識別率也會隨之上升,但是飽和情況會先出現在深度維度,即說明寬度更為重要。再者就是豐富姿態和光照的變化能使得生成數據更加接近真實數據,從而大幅度提升識別率。更多實驗結果分析還請參見原論文。



















