CVPR2021「自監(jiān)督學(xué)習(xí)」領(lǐng)域重磅新作,只用負(fù)樣本也能學(xué)
在自監(jiān)督學(xué)習(xí)領(lǐng)域,基于contrastive learning(對比學(xué)習(xí))的思路已經(jīng)在下游分類檢測和任務(wù)中取得了明顯的優(yōu)勢。其中如何充分利用負(fù)樣本提高學(xué)習(xí)效率和學(xué)習(xí)效果一直是一個值得探索的方向,本文「第一次」提出了用對抗的思路end-to-end來直接學(xué)習(xí)負(fù)樣本,在ImageNet和下游任務(wù)均達(dá)到SOTA.
眾所周知,負(fù)樣本和正樣本是對比學(xué)習(xí)的關(guān)鍵。進(jìn)一步而言,負(fù)樣本的數(shù)量和質(zhì)量對于對比學(xué)習(xí)又是其中的重中之重。在BYOL[1]提出后,對于是否需要負(fù)樣本也引發(fā)了很多討論,本文從對抗的角度去探索負(fù)樣本,也揭示了負(fù)樣本的本質(zhì)和BYOL在去除負(fù)樣本之后仍然能夠達(dá)到非常好的效果的原因。

論文鏈接:
https://arxiv.org/abs/2011.08435
論文代碼已開源:
https://github.com/maple-research-lab/AdCo
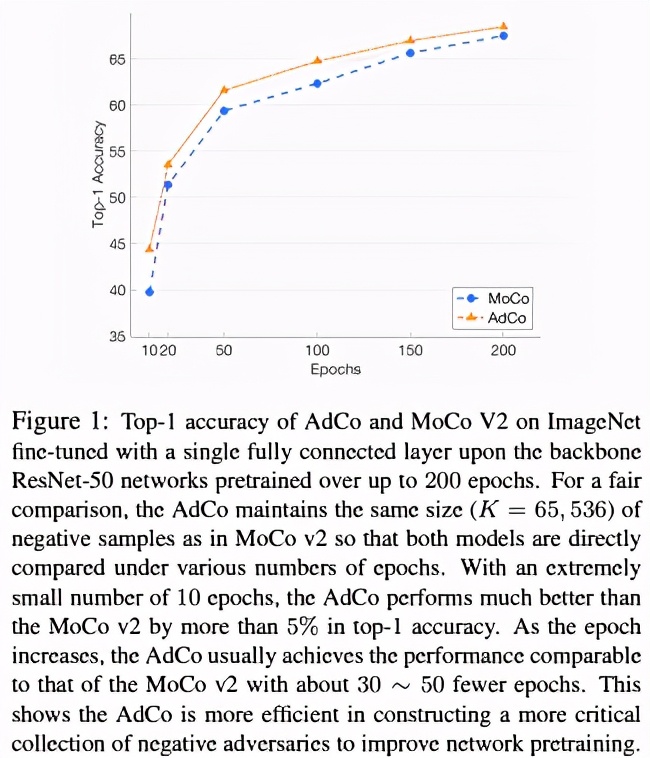
AdCo僅僅用8196個負(fù)樣本(八分之一的MoCo v2的負(fù)樣本量),就能達(dá)到與之相同的精度。同時,這些可直接訓(xùn)練的負(fù)樣本在和BYOL中Prediction MLP參數(shù)量相同的情況下依然能夠取得相似的效果。這說明了在自監(jiān)督學(xué)習(xí)時代,通過將負(fù)樣本可學(xué)習(xí)化,對比學(xué)習(xí)仍然具有學(xué)習(xí)效率高、訓(xùn)練穩(wěn)定和精度高等一系列優(yōu)勢。
目錄
1、要不要負(fù)樣本?
2、AdCo vs. BYOL
3、新思路:Adversarial Contrast: 對抗對比學(xué)習(xí)
4、實驗結(jié)果
1、 要不要負(fù)樣本?
去年DeepMind提出的無監(jiān)督模型BYOL[1]的一個突出特點是去掉了負(fù)樣本,在討論AdCo前,一個很核心的問題就是在自監(jiān)督時代,我們究竟要不要負(fù)樣本?
首先,從比較純粹的實用主義角度來說,MoCo V2[2]這類基于負(fù)樣本的對比學(xué)習(xí)方法,自監(jiān)督訓(xùn)練的時間都是比BYOL較少的。這點不難理解,MoCo V2不需要基于Global Batch Normalization (BN)(GPU之間需要通訊),所以從速度來說僅僅需要BYOL約1/3的時間。
另一方面,類似MoCo V2的方法一個比較麻煩的地方是要不斷得維護(hù)一個負(fù)樣本的隊列。但是,用一組負(fù)樣本做對比學(xué)習(xí),從訓(xùn)練性能的角度來說,從前諸多的實驗來看可能更穩(wěn)定,畢竟多個負(fù)樣本的對比可以提供更多的樣本的分布信息,比BYOL只在單個圖像的兩個變換增強樣本得到的特征上做MSE從訓(xùn)練的角度來說可以更穩(wěn)定。同時memory bank維持的負(fù)樣本并不需要梯度計算,所以相關(guān)計算量可以忽略不計。
因此,我們認(rèn)為負(fù)樣本在對比學(xué)習(xí)里仍然是一個值得探索的方向。但需要解決如何提高負(fù)樣本的質(zhì)量和使用效率的問題。一個比較好的想法是我們能不能不再依賴一個被動的維護(hù)一個負(fù)樣本隊列去訓(xùn)練對比模型,而是直接通過主動學(xué)習(xí)的方法把負(fù)樣本當(dāng)作網(wǎng)絡(luò)參數(shù)的一部分去做end-to-end的訓(xùn)練?
2、 AdCo vs. BYOL
BYOL中除了global BN外,為了用一個分支得到的特征去監(jiān)督另外一個分支輸出的特征,還需要訓(xùn)練一個只存在于query分支的MLP的預(yù)測器(predictor)以達(dá)到非對稱的結(jié)構(gòu)防止訓(xùn)練collapse。
雖然BYOL的predictor里的參數(shù)不是負(fù)樣本,但某種意義上可以看作是某種包含典型樣本對應(yīng)特征的codebook,這個codebook的組合形成了對另一個分支輸出特征的預(yù)測。為了達(dá)到精確預(yù)測的目的,勢必要求這個codebook要比較diverse,能比較好的覆蓋另外一個分支輸出的特征,從而阻止collapse的可能。
從模型參數(shù)的角度來說,這個額外的 Predictor Layer 相當(dāng)于一般對比學(xué)習(xí)里用到的負(fù)樣本,只不過前者是直接通過反向傳播訓(xùn)練得到的,而后者在MoCo V2[2]和SimCLR[3]里是通過收集過去或者當(dāng)前的batch中的特征得到的。
那么,一個自然的問題就是,負(fù)樣本能夠也能像預(yù)測器一樣通過訓(xùn)練出來嗎?如果可以,就意味著對比學(xué)習(xí)中的負(fù)樣本也可以看作是模型的一部分,并且可以通過訓(xùn)練的方法得到,這就給出了一種更加直觀優(yōu)美的方法來構(gòu)造負(fù)樣本。
遺憾的是,直接去最小化contrastive loss并不能用來訓(xùn)練負(fù)樣本,因為這樣得到的是遠(yuǎn)離所有query樣本的負(fù)樣本,因此我們在AdCo中采取了對抗學(xué)習(xí)的思路。
3、 新思路:用對抗對比學(xué)習(xí)去直接訓(xùn)練負(fù)樣本!
依據(jù)此,我們提出了AdCo對抗對比學(xué)習(xí),通過直接訓(xùn)練負(fù)樣本的方式來進(jìn)一步提高負(fù)樣本的質(zhì)量從而促進(jìn)對比學(xué)習(xí)。
1、相比于memory bank去存儲過往圖片embedding的方式,我們完全可以把負(fù)樣本作為可學(xué)習(xí)的權(quán)重來訓(xùn)練,這里的好處是我們的所有負(fù)樣本可以在每次迭代中同步更新。質(zhì)量。作為對比,MoCo V2每次只能更新當(dāng)前負(fù)樣本隊列里的很小的一部分,這導(dǎo)致了最早進(jìn)入memory bank的負(fù)樣本對于對比學(xué)習(xí)的貢獻(xiàn)相對較小。
2、當(dāng)然,更新負(fù)樣本就不能去最小化對應(yīng)的contrastive loss,而要最大化它,使得得到的負(fù)樣本更加地困難,而對訓(xùn)練representation network更有價值,這就得到了一個對抗性的對比學(xué)習(xí),對抗的雙方是負(fù)樣本和特征網(wǎng)絡(luò)。
3、通過對update負(fù)樣本的梯度進(jìn)行分析,我們發(fā)現(xiàn)這種方法具有非常明顯的物理意義。負(fù)樣本每次更新的方向都是指向當(dāng)前正樣本的一個以某個負(fù)樣本所歸屬的正樣本的后驗概率為權(quán)重,對正樣本做加權(quán)平均得到的梯度方向;
具體而言,文章中的公式(6)通過最大化對比損失函數(shù)可以給出直接訓(xùn)練負(fù)樣本的梯度:
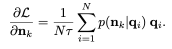
其中的條件概率是
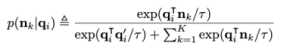

實驗發(fā)現(xiàn),在同樣的訓(xùn)練時間、minibatch大小下,AdCo的精度都會更高。這說明了,AdCo比其他的自監(jiān)督方法就有更高的訓(xùn)練效率和精度。這種提升來自對負(fù)樣本更有效的更新迭代。
4、實驗結(jié)果
相比于基于memory bank的方法,我們的模型在ImageNet分類任務(wù)上有了顯著的提升。
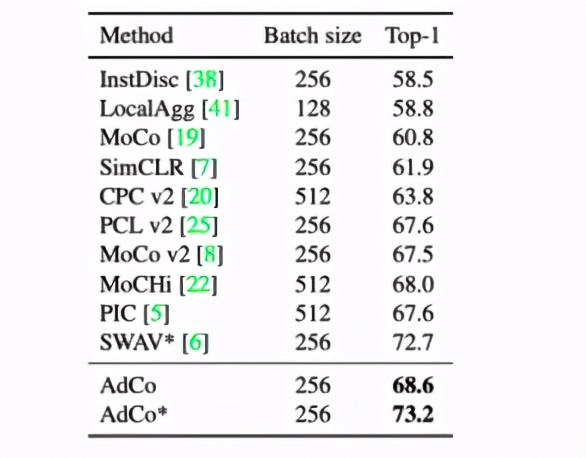
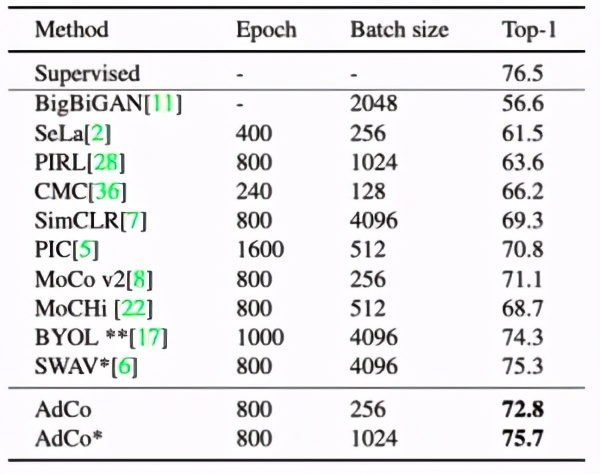
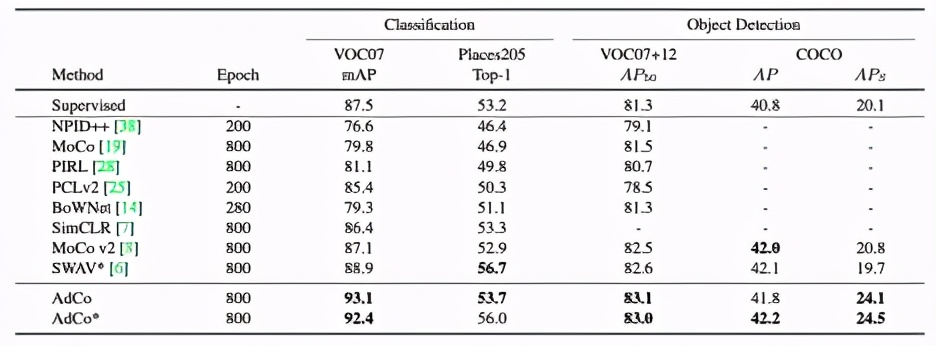
同時,在下游檢測和分類任務(wù)中,我們相比過往自監(jiān)督方法和全監(jiān)督方法都有顯著的提升:
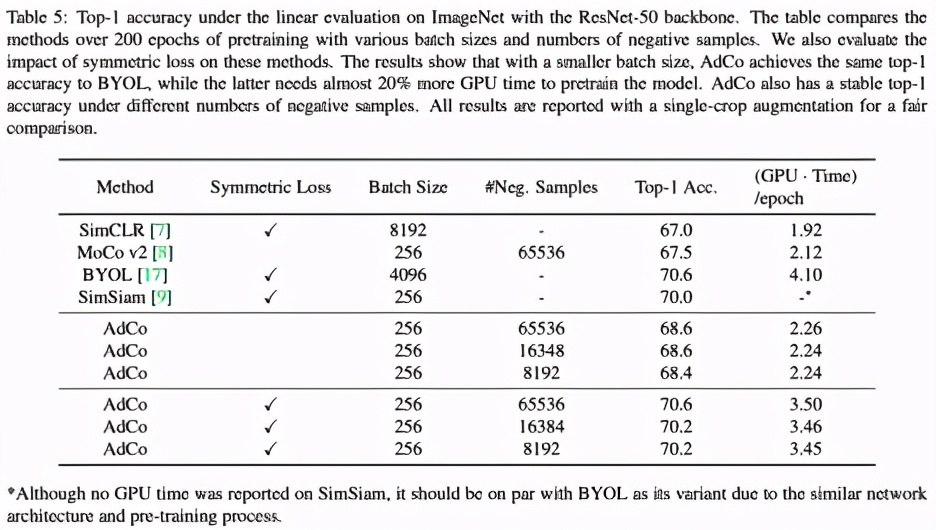
我們進(jìn)一步AdCo是否可以通過訓(xùn)練更少的負(fù)樣本來得到同樣好的無監(jiān)督預(yù)訓(xùn)練模型。答案是肯定的。
如下面的結(jié)果所展示的,只用原先1/4和1/8的樣本,在ImageNet上的top-1 accuracy幾乎沒有任何損失。這進(jìn)一步說明了,通過直接用對抗的方式訓(xùn)練負(fù)樣本,把負(fù)樣本看成是模型可訓(xùn)練參數(shù)的一部分,完全可以得到非常好的訓(xùn)練效果,而且相對于其他的模型,所用的 GPU訓(xùn)練時間也更少。
進(jìn)一步而言,我們的學(xué)習(xí)效率也顯著優(yōu)于基于memory bank的方法,以下是不同自監(jiān)督訓(xùn)練輪數(shù)下在ImageNet上的對比: