一文讀懂監督學習、無監督學習、半監督學習、強化學習這四種深度學習方式

一般說來,訓練深度學習網絡的方式主要有四種:監督、無監督、半監督和強化學習。在接下來的文章中,計算機視覺戰隊將逐個解釋這些方法背后所蘊含的理論知識。除此之外,計算機視覺戰隊將分享文獻中經常碰到的術語,并提供與數學相關的更多資源。
監督學習(Supervised Learning)
監督學習是使用已知正確答案的示例來訓練網絡的。想象一下,我們可以訓練一個網絡,讓其從照片庫中(其中包含你父母的照片)識別出你父母的照片。以下就是我們在這個假設場景中所要采取的步驟。
步驟1:數據集的創建和分類
首先,我們要瀏覽你的照片(數據集),確定所有有你父母的照片,并對其進行標注,從而開始此過程。然后我們將把整堆照片分成兩堆。我們將使用第一堆來訓練網絡(訓練數據),而通過第二堆來查看模型在選擇我們父母照片操作上的準確程度(驗證數據)。
等到數據集準備就緒后,我們就會將照片提供給模型。在數學上,我們的目標就是在深度網絡中找到一個函數,這個函數的輸入是一張照片,而當你的父母不在照片中時,其輸出為0,否則輸出為1。
此步驟通常稱為 分類任務 。在這種情況下,我們進行的通常是一個結果為yes or no的訓練,但事實是,監督學習也可以用于輸出一組值,而不僅僅是0或1。例如,我們可以訓練一個網絡,用它來輸出一個人償還信用卡貸款的概率,那么在這種情況下,輸出值就是0到100之間的任意值。這些任務我們稱之為 回歸 。
步驟2:訓練
為了繼續該過程,模型可通過以下規則(激活函數)對每張照片進行預測,從而決定是否點亮工作中的特定節點。這個模型每次從左到右在一個層上操作——現在我們將更復雜的網絡忽略掉。當網絡為網絡中的每個節點計算好這一點后,我們將到達亮起(或未亮起)的最右邊的節點(輸出節點)。
既然我們已經知道有你父母的照片是哪些圖片,那么我們就可以告訴模型它的預測是對還是錯。然后我們會將這些信息反饋(feed back)給網絡。
該算法使用的這種反饋,就是一個量化“真實答案與模型預測有多少偏差”的函數的結果。這個函數被稱為成本函數(cost function),也稱為目標函數(objective function),效用函數(utility function)或適應度函數(fitness function)。然后,該函數的結果用于修改一個稱為 反向傳播 (backpropagation)過程中節點之間的連接強度和偏差,因為信息從結果節點“向后”傳播。
我們會為每個圖片都重復一遍此操作,而在每種情況下,算法都在盡量最小化成本函數。
其實,我們有多種數學技術可以用來驗證這個模型是正確還是錯誤的,但我們常用的是一個非常常見的方法,我們稱之為 梯度下降 (gradient descent)。Algobeans上有一個 “門外漢”理論可以很好地解釋它是如何工作的。邁克爾•尼爾森(Michael Nielsen) 用 數學知識完善 了這個方法 ,其中包括微積分和線性代數。
http://neuralnetworksanddeeplearning.com/chap2.html
步驟3:驗證
一旦我們處理了第一個堆棧中的所有照片,我們就應該準備去測試該模型。我們應充分利用好第二堆照片,并使用它們來驗證訓練有素的模型是否可以準確地挑選出含有你父母在內的照片。
我們通常會通過調整和模型相關的各種事物(超參數)來重復步驟2和3,諸如里面有多少個節點,有多少層,哪些數學函數用于決定節點是否亮起,如何在反向傳播階段積極有效地訓練權值,等等。而你可以通過瀏覽Quora上的相關介紹來理解這一點,它會給你一個很好的解釋。
步驟4:使用
最后,一旦你有了一個準確的模型,你就可以將該模型部署到你的應用程序中。你可以將模型定義為API調用,例如ParentsInPicture(photo),并且你可以從軟件中調用該方法,從而導致模型進行推理并給出相應的結果。
稍后我們將詳細介紹一下這個確切的過程,編寫一個識別名片的iPhone應用程序。
得到一個標注好的數據集可能會很難(也就是很昂貴),所以你需要確保預測的價值能夠證明獲得標記數據的成本是值得的,并且我們首先要對模型進行訓練。例如,獲得可能患有癌癥的人的標簽X射線是非常昂貴的,但是獲得產生少量假陽性和少量假陰性的準確模型的值,這種可能性顯然是非常高的。
無監督學習(Unsupervised Learning)
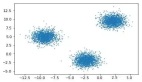
無監督學習適用于你具有數據集但無標簽的情況。無監督學習采用輸入集,并嘗試查找數據中的模式。比如,將其組織成群(聚類)或查找異常值(異常檢測)。例如:
•想像一下,如果你是一個T恤制造商,擁有一堆人的身體測量值。那么你可能就會想要有一個聚類算法,以便將這些測量組合成一組集群,從而決定你生產的XS,S,M,L和XL號襯衫該有多大。
你將在文獻中閱讀到的一些無監督的學習技術包括:
•自編碼(Autoencoding)
http://ufldl.stanford.edu/tutorial/unsupervised/Autoencoders/
•主成分分析(Principal components analysis)
https://www.quora.com/What-is-an-intuitive-explanation-for-PCA
•隨機森林(Random forests)
https://en.wikipedia.org/wiki/Random_forest
•K均值聚類(K-means clustering)
https://www.youtube.com/watch?v=RD0nNK51Fp8
無監督學習中最有前景的最新發展之一是Ian Goodfellow(當時在Yoshua Bengio的實驗室工作時提出)的一個想法,稱為“ 生成對抗網絡 (generative adversarial networks)”,其中我們將兩個神經網絡相互聯系:一個網絡,我們稱之為生成器,負責生成旨在嘗試欺騙另一個網絡的數據,而這個網絡,我們稱為鑒別器。這種方法實現了一些令人驚奇的結果,例如可以從文本字符串或手繪草圖生成如照片版逼真圖片的AI技術。
半監督學習(Semi-supervised Learning)
半監督學習在訓練階段結合了大量未標記的數據和少量標簽數據。與使用所有標簽數據的模型相比,使用訓練集的訓練模型在訓練時可以更為準確,而且訓練成本更低。
為什么使用未標記數據有時可以幫助模型更準確,關于這一點的體會就是:即使你不知道答案,但你也可以通過學習來知曉,有關可能的值是多少以及特定值出現的頻率。
數學愛好者的福利:如果你對半監督學習很感興趣的話,可以來閱讀這個朱小津教授的 幻燈片教程 和2008年回顧的 文獻隨筆文章 。 (我們會把這兩個共享在平臺的共享文件專欄)
強化學習(Reinforcement Learning)
強化學習是針對你再次沒有標注數據集的情況而言的,但你還是有辦法來區分是否越來越接近目標(回報函數(reward function))。經典的兒童游戲——“hotter or colder”。 ( Huckle Buckle Beanstalk 的一個變體 )是這個概念的一個很好的例證。你的任務是找到一個隱藏的目標物件,然后你的朋友會喊出你是否越來越hotter(更接近)或colder(遠離)目標物件。“Hotter/colder”就是回報函數,而算法的目標就是最大化回報函數。你可以把回報函數當做是一種延遲和稀疏的標簽數據形式:而不是在每個數據點中獲得特定的“right/wrong”答案,你會得到一個延遲的反應,而它只會提示你是否在朝著目標方向前進。
•DeepMind在Nature上發表了一篇文章,描述了一個將強化學習與深度學習結合起來的系統,該系統學會該如何去玩一套Atari視頻游戲,一些取得了巨大成功(如Breakout),而另一些就沒那么幸運了(如Montezuma’s Revenge(蒙特祖瑪的復仇))。
•Nervana團隊(現在在英特爾) 發表了一個很好的 解惑性博客文章 , 對這些技術進行了詳細介紹,大家有興趣可以閱讀一番。
https://www.nervanasys.com/demystifying-deep-reinforcement-learning/
•Russell Kaplan,Christopher Sauer和Alexander Sosa舉辦的一個非常有創意的斯坦福學生項目說明了強化學習的挑戰之一,并提出了一個聰明的解決方案。正如你在DeepMind論文中看到的那樣,算法未能學習如何去玩Montezuma’s Revenge。其原因是什么呢?正如斯坦福大學生所描述的那樣,“在稀缺回報函數的環境中,強化學習agent仍然在努力學習”。當你沒有得到足夠的“hotter”或者“colder”的提示時,你是很難找到隱藏的“鑰匙”的。斯坦福大學的學生基礎性地教導系統去了解和回應自然語言提示,例如“climb down the ladder”或“get the key”,從而使該系統成為OpenAI gym中的最高評分算法。 可以點擊 算法視頻 觀看算法演示。
(http://mp.weixinbridge.com/mp/wapredirect?url=https%3A%2F%2Fdrive.google.com%2Ffile%2Fd%2F0B2ZTvWzKa5PHSkJvQVlsb0FLYzQ%2Fview&action=appmsg_redirect&uin=Nzk3MTk3MzIw&biz=MzA5MzQwMDk4Mg==&mid=2651042109&idx=1&type=1&scene=0)
•觀看這個關于強化學習的算法,好好學習,然后像一個大boss一樣去玩超級馬里奧吧。
理查德•薩頓和安德魯•巴托寫了關于強化學習的書。你也可以點擊查看第二版草稿。 http://incompleteideas.net/sutton/book/the-book-1st.html