自監督學習簡介以及在三大領域中現狀
近幾年,通過監督學習進行的深度學習也取得了巨大的成功。從圖像分類到語言翻譯,它們的性能一直在提高。然而在一些領域(例如罕見疾病的醫療數據集)中,收集大型標記數據集是昂貴且不可能的。這些類型的數據集為自監督算法提供了充足的機會,以進一步提高預測模型的性能。
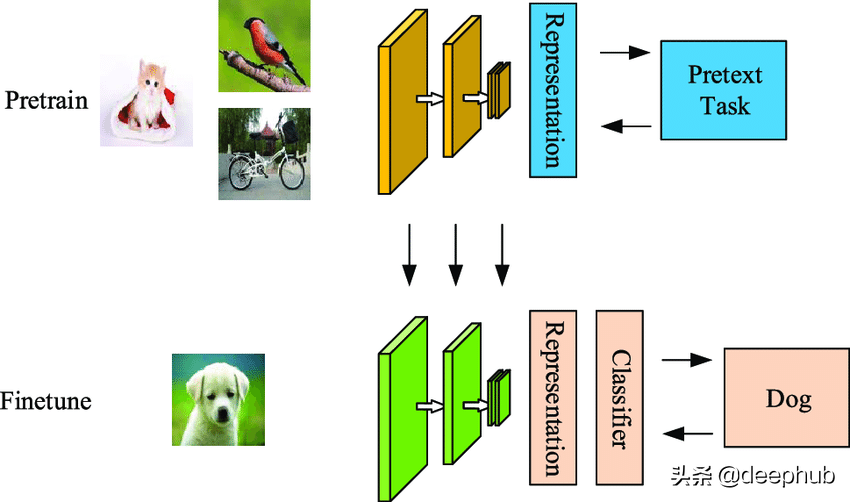
自監督學習旨在從未標記的數據中學習信息表示。在這種情況下,標記數據集比未標記數據集相對小。自監督學習使用這些未標記的數據并執行前置任務(pretext tasks )和對比學習。
Jeremey Howard 在一篇關于自監督學習的優秀文章中將監督學習定義為兩個階段:“我們用于預訓練的任務被稱為前置任務。我們隨后用于微調的任務稱為下游任務”。自監督學習的例子包括未來詞預測、掩碼詞預測修復、著色和超分辨率。
計算機視覺的自監督學習
自監督學習方法依賴于數據的空間和語義結構。 對于圖像,空間結構學習是極其重要的。 包括旋轉、拼接和著色在內的不同技術被用作從圖像中學習表征的前置任務。 對于著色,將灰度照片作為輸入并生成照片的彩色版本。 zhang等人的論文[1] 解釋了產生生動逼真的著色的著色過程。

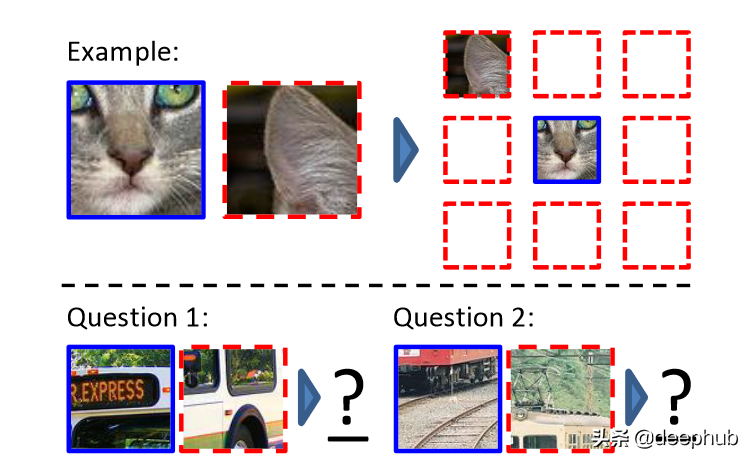
另一種廣泛用于計算機視覺自監督學習的方法是放置圖像塊。 一個例子包括 Doersch 等人的論文 [2]。 在這項工作中,提供了一個大型未標記的圖像數據集,并從中提取了隨機的圖像塊對。 在初始步驟之后,卷積神經網絡預測第二個圖像塊相對于第一個圖像塊的位置。 圖 2 說明了該過程。
還有其他不同的方法用于自監督學習,包括修復和判斷分類錯誤的圖像。 如果對此主題感興趣,請查看參考文獻 [3]。 它提供了有關上述主題的文獻綜述。
自然語言處理的自監督學習
在自然語言處理任務中,自監督學習方法是最常見的。Word2Vec論文中的“連續詞袋”方法是自監督學習最著名的例子。
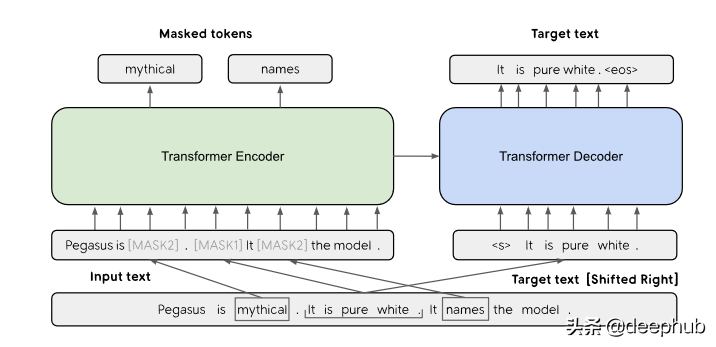
類似地,還有其他不同的用于自監督學習的方法,包括相鄰詞預測、相鄰句子預測、自回歸語言建模和掩碼語言建模。 掩碼語言建模公式已在 BERT、RoBERTa 和 ALBERT 論文中使用。
文本自監督學習的最新例子包括 Zhang 等人的論文 [4]。 作者提出了一種間隔句生成機制。 該機制用于總結摘要的下游任務。
表格數據的自監督學習
對圖像和文本的自監督學習一直在進步。但現有的自監督方法對表格數據無效。表格數據沒有空間關系或語義結構,因此現有的依賴空間和語義結構的技術是沒有用的。
大多數表格數據都涉及分類特征,而這些特征不具有有意義的凸組合。即使對于連續變量,也不能保證數據流形是凸的。但是這一挑戰為研究人員提供了一個新的研究方向。我將簡要說明在這方面所做的一些工作。
Vincent 等人所做的工作 [5] 提出了一種去噪自動編碼器的機制。前置任務是從損壞的樣本中恢復原始樣本。在另一篇論文中,Pathak 等人 [6] 提出了一種上下文編碼器,從損壞的樣本和掩碼向量中重建原始樣本。
Tabnet [7] 和 TaBERT [8] 的研究也是朝著自監督學習的漸進式工作。在這兩項研究中,前置任務是恢復損壞的表格數據。 TabNet 專注于注意力機制,并在每一步選擇特征進行推理,TABERT 則是學習自然語言句子和半結構化表格的表示。
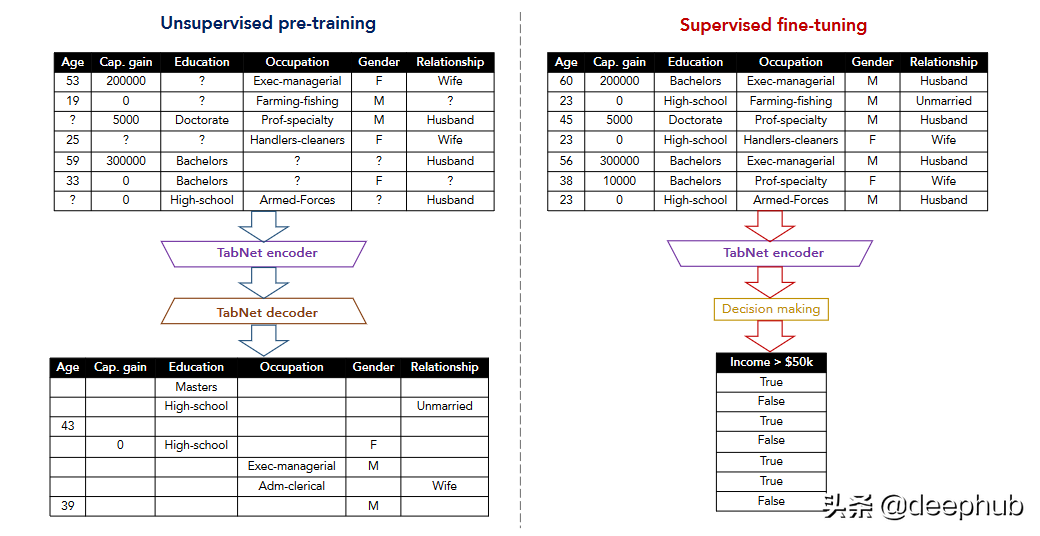
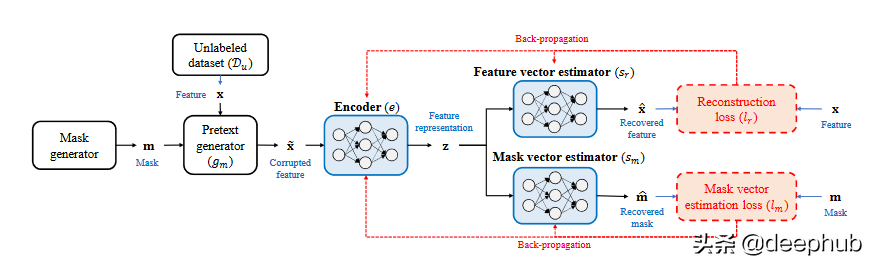
最近的一項工作 (VIME) [9] 提出了一種新的前置任務,可以使用一種新的損壞樣本生成技術來恢復掩碼向量和原始樣本。 作者還提出了一種新的表格數據增強機制,可以結合對比學習來擴展表格數據的監督學習。 這里的輸入樣本是從未標記的數據集生成的”。
總結
自監督學習是深度學習的新常態。 圖像和文本數據的自監督學習技術令人驚嘆,因為它們分別依賴于空間和順序相關性。 但是,表格數據中沒有通用的相關結構。 這使得表格數據的自監督學習更具挑戰性。