













面試官上來就問MySQL事務,瑟瑟發抖...
原創【51CTO.com原創稿件】關于學習這件事情寧可花點時間系統學習,也不要東一榔頭西一棒槌,都說學習最好的方式就是系統的學習,希望看完本文會讓你對 MySQL 事物有一定的理解,數據庫版本為 8.0。
圖片來自 Pexels
什么是事物
事物是獨立的工作單元,在這個獨立工作單元中所有操作要么全部成功,要么全部失敗。
也就是說如果有任何一條語句因為崩潰或者其它原因導致執行失敗,那么未執行的語句都不會再執行,已經執行的語句會進行回滾操作,這個過程被稱之為事物。
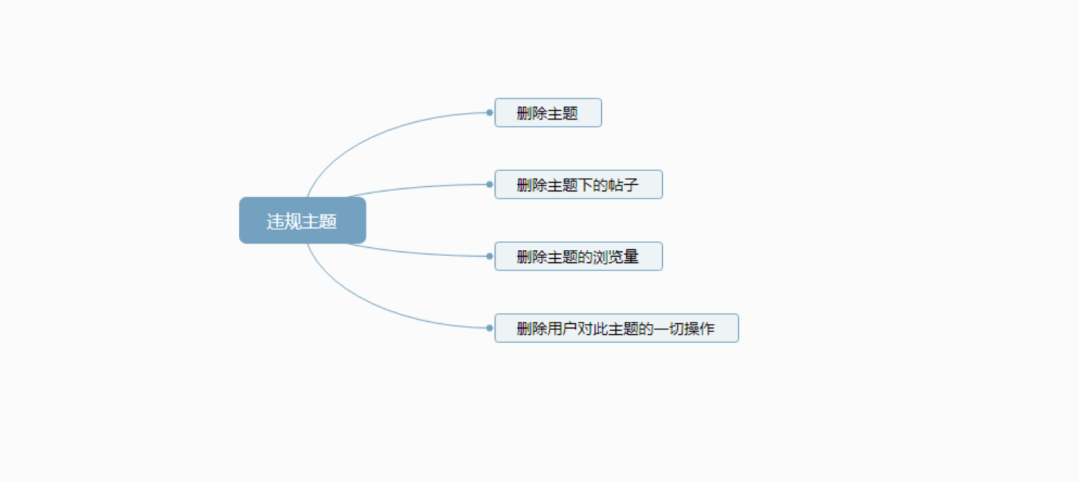
例:最近在寫一個論壇系統,當發布的主題被其它用戶舉報后,后臺會對舉報內容進行審核。
一經審核為違規主題,則進行刪除主題的操作,但不僅僅要刪除主題還要刪除主題下的帖子、瀏覽量,關于這個主題的一切信息都需要進行清理。
刪除流程如下,用上邊概念來說,以下執行的四個流程,每個流程都必須成功否則事務回滾返回刪除失敗。
假設執行到了第三步后 SQL 執行失敗了,那么第一二步都會進行回滾,第四步則不會在執行。
事物四大特征
事物的四大特征:
- 原子性
- 一致性
- 隔離性
- 持久性
①原子性
事物中所有操作要么全部成功,要么全部失敗,不會存在一部分成功,一部分失敗。
這個概念也是事物最核心的特性,事物概念本身就是使用原子性進行定義的。
原子性的實現是基于回滾日志實現(undo log),當事物需要回滾時就會調用回滾日志進行 SQL 語句回滾操作,實現數據還原。
②一致性
一致性,字面意思就是前后一致唄!在數據庫中不管進行任何操作,都是從一個一致性轉移到另一個一致性。
當事物結束后,數據庫的完整性約束不被破壞。當你了解完事物的四大特征之后就會發現,都是保證數據一致性為最終目標存在的。
在學習事物的過程中大家看到最多的案例就是轉賬,假設用戶 A 與用戶 B 余額共計 1000,那么不管怎么轉倆人的余額自始至終也就只有 1000。
③隔離性
保證事物執行盡可能的不受其它事物影響,這個是隔離級別可以自行設置,在 innodb 中默認的隔離級別為可重復讀(Repeatable Read)。
這種隔離級別有可能造成的問題就是出現幻讀,但是使用間隙鎖可以解決幻讀問題。
學習了隔離性你需要知道原子性和持久性是針對單個事物,而隔離性是針對事物與事物之間的關系。
④持久性
持久性是指當事物提交之后,數據的狀態就是永久的,不會因為系統崩潰而丟失。事物持久性是基于重做日志(redo log)實現的。
事物并發會出現的問題
①臟讀
讀取了另一個事物沒有提交的數據。
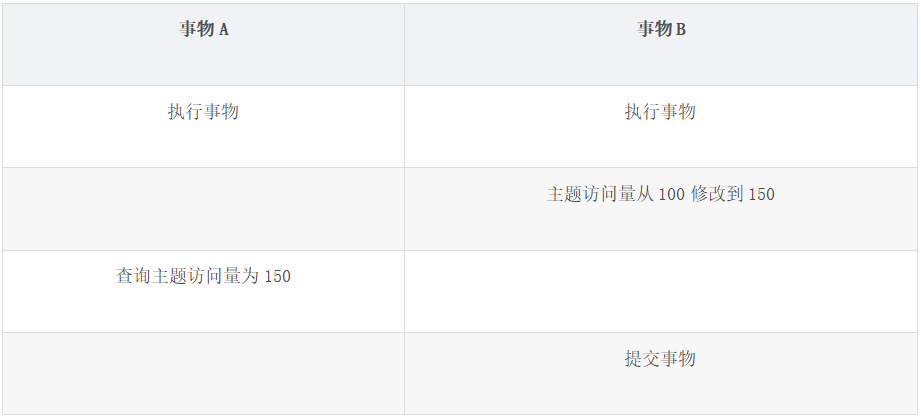
以上表為例,事物 A 讀取主題訪問量時讀取到了事物B沒有提交的數據 150。
如果事物 B 失敗進行回滾,那么修改后的值還是會回到 100。然而事物 A 獲取的數據是修改后的數據,這就有問題了。
②不可重復讀
事物讀取同一個數據,返回結果先后不一致問題。
上表格中,事物 A 在先后獲取主題訪問量時,返回的數據不一致。也就是說在事物 A 執行的過程中,訪問量被其它事物修改,那么事物 A 查詢到的結果就是不可靠的。
臟讀與不可重復讀的區別:臟讀讀取的是另一個事物沒有提交的數據,而不可重復讀讀取的是另一個事物已經提交的數據。
③幻讀
事物按照范圍查詢,倆次返回結果不同。
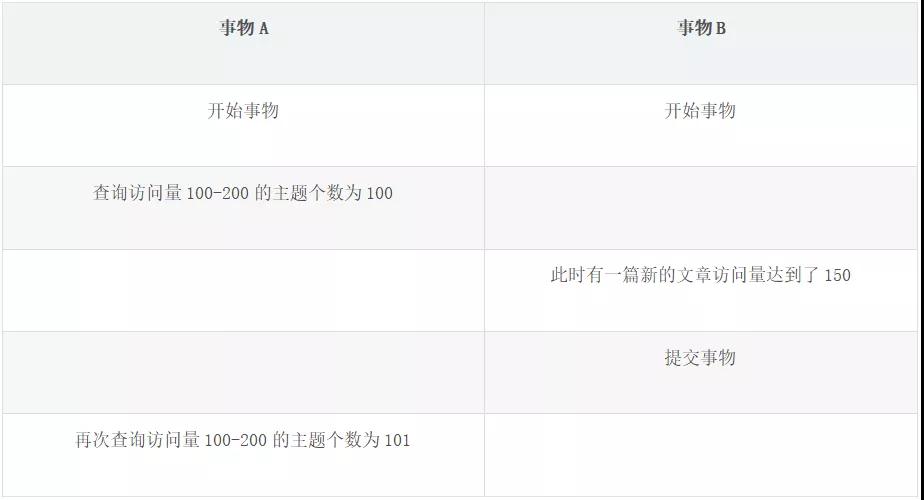
以上表為例,當對 100-200 訪問量的主題做統計時,第一次找到了 100 個,第二次找到了 101 個。
④區別
臟讀讀取的是另一個事物沒有提交的數據,而不可重復讀讀取的是另一個事物已經提交的數據。
幻讀和不可重復讀都是讀取了另一條已經提交的事務(這點與臟讀不同),所不同的是不可重復讀查詢的都是同一個數據項,而幻讀針對的是一批數據整體(比如數據的個數)。
針對以上的三個問題,產生了四種隔離級別。在第二節中對隔離性進行了簡單的概念解釋,實際上的隔離性是很復雜的。
在 MySQL 中定義了四種隔離級別,分別為:
- 未提交讀 (Read Uncommitted):倆個事物同時運行,有一個事物修改了數據,但未提交,另一個事物是可以讀取到沒有提交的數據。這種情況被稱之為臟讀。
- 提交讀(Read committed):一個事物在未提交之前,所做的任何操作其它事物不可見。這種隔離級別也被稱之為不可重復讀。因為會存在倆次同樣的查詢,返回的數據可能會得到不一樣的結果。
- 可重復讀(Repeatable Read):這種隔離級別解決了臟讀問題,但是還是存在幻讀問題,這種隔離界別在 MySQL 的 innodb 引擎中是默認級別。MySQL 在解決幻讀問題使用間隙鎖來解決幻讀問題。
- 可串行化 (Serializable):這種級別是最高的,強制事物進行串行執行,解決了可重復讀的幻讀問題。
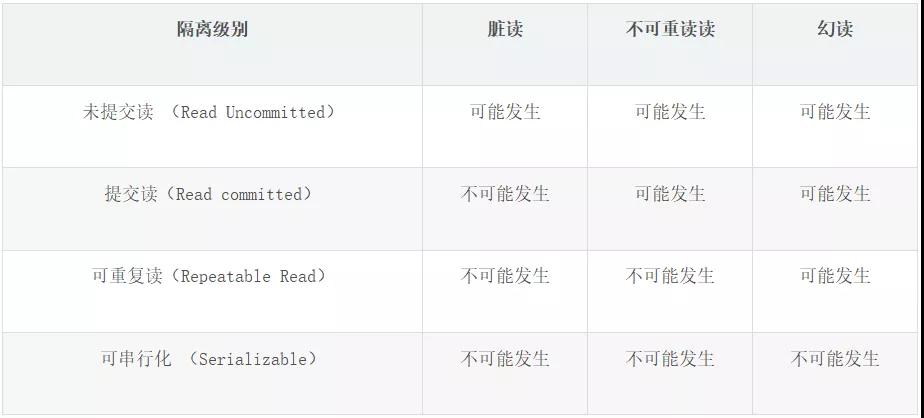
對于隔離級別,級別越高并發就越低,而級別越低會引發臟讀、不可重復讀、幻讀的問題。
因此在 MySQL 中使用可重復讀(Repeatable Read)作為默認級別。
作為默認級別是如何解決并處理相應問題的呢?那么針對這一問題,是一個難啃的骨頭,我將在下一期 MVCC 文章專門來介紹這塊。
事物日志以及事物異常如何應對
在 Innodb 中事物的日志分為倆種,回滾日志、重做日志。
先來看一下倆個日志的存放位置吧!MySQL 的版本號為 8.0。
在 Linux 下的 MySQL 事物日志存放在 /var/lib/mysql 這個位置中:
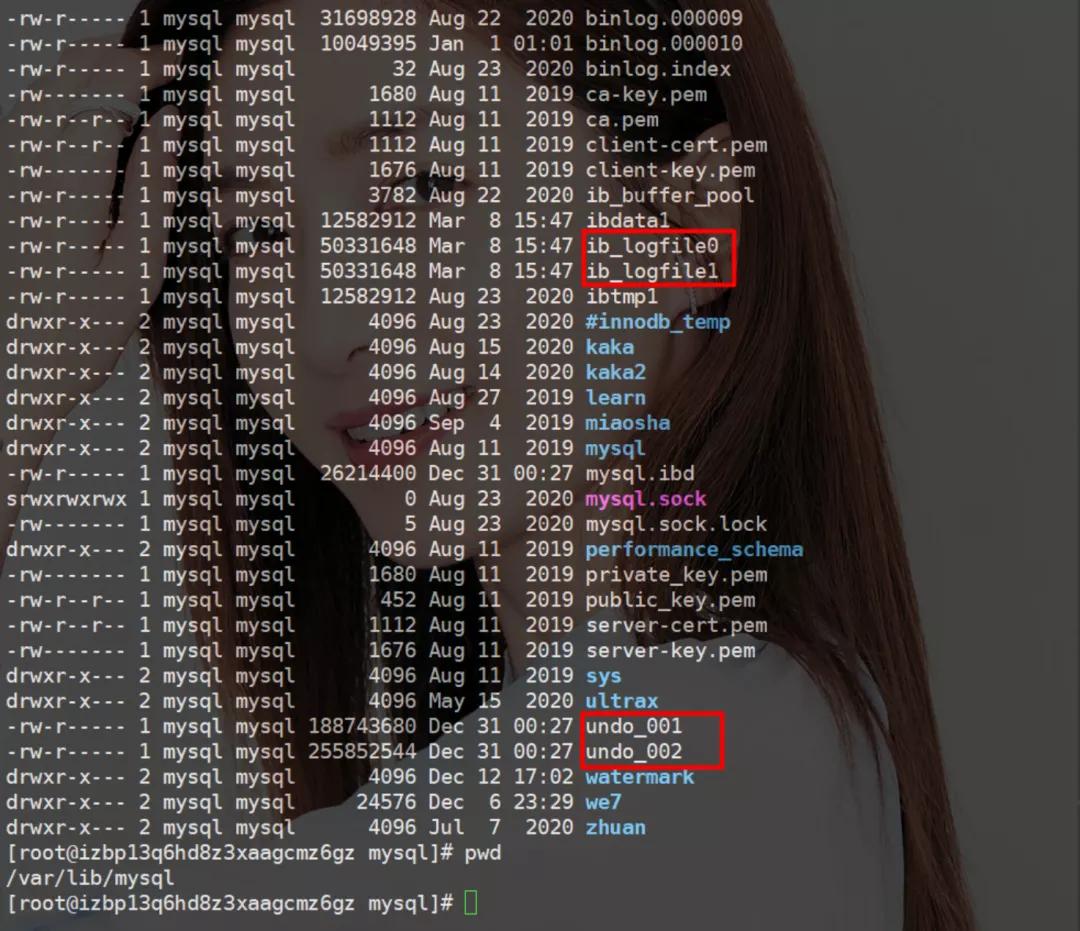
從上圖中可以看到分別為 ib_logfile、undo_ 倆個文件:
- ib_logfile 文件為重做日志
- undo_ 文件為回滾日志
在這里估計有點小伙伴會有點迷糊這個回滾日志。那是因為在 MySQL 5.6 默認回滾日志沒有進行獨立表空間存儲,而是存放到了 ibdata 文件中。
獨立表空間存儲從 MySQL 5.6 后就已經支持了,但是需要自行配置。
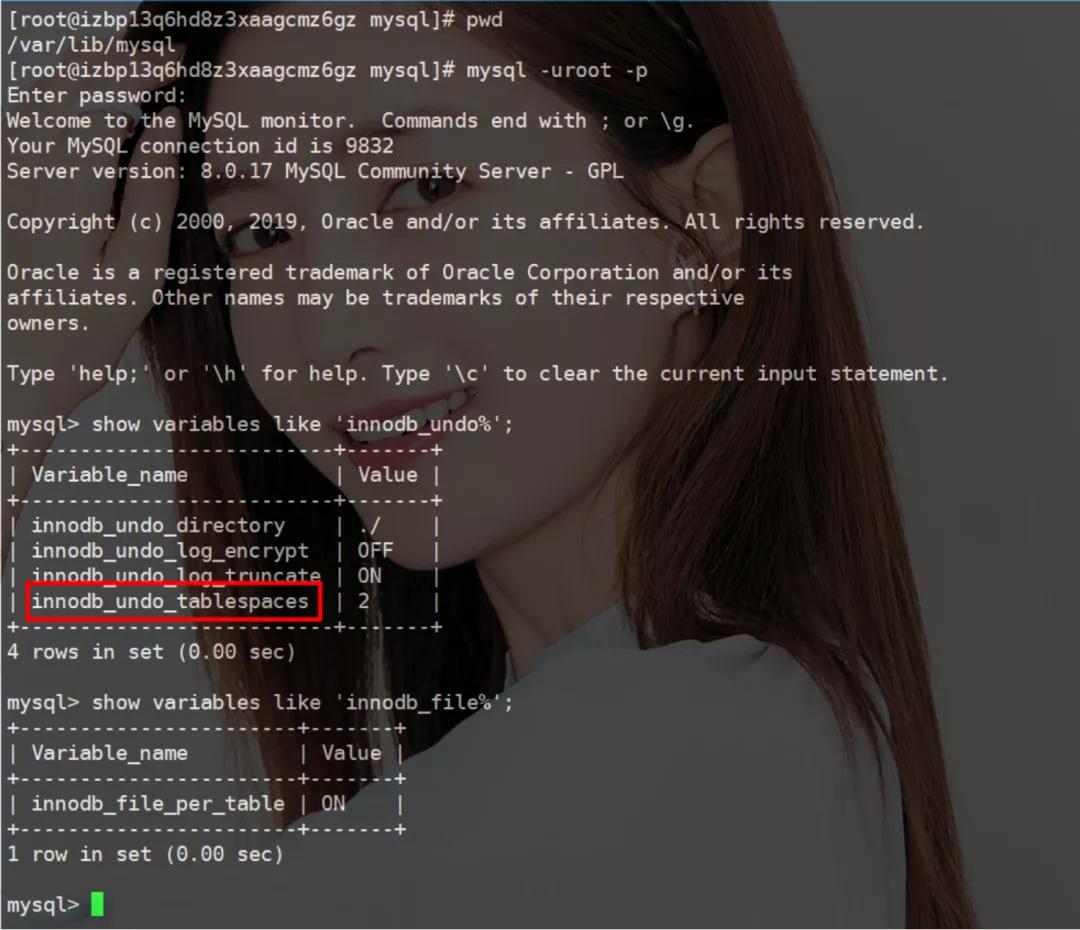
在 MySQL 8.0 是由 innodb_undo_tablespaces 這個參數來設置回滾日志獨立空間個數,這個參數的范圍為 0-128。
默認值為 0 表示不開啟獨立的回滾日志,且回滾日志存儲在 ibdata 文件中。
這個參數是在初始化數據庫時指定的,實例一旦創建這個參數是不能改動的。
如果設置的 innodb_undo_tablespaces 值大于實例創建時的個數,則會啟動失敗。
①重做日志(redo log)(持久性實現原理)
事物的持久性就是通過重做日志來實現的。
當提交事物之后,并不是直接修改數據庫的數據的,而是先保證將相關的操作記錄到 redo 日志中。
數據庫會根據相應的機制將內存的中的臟頁數據刷新到磁盤中。
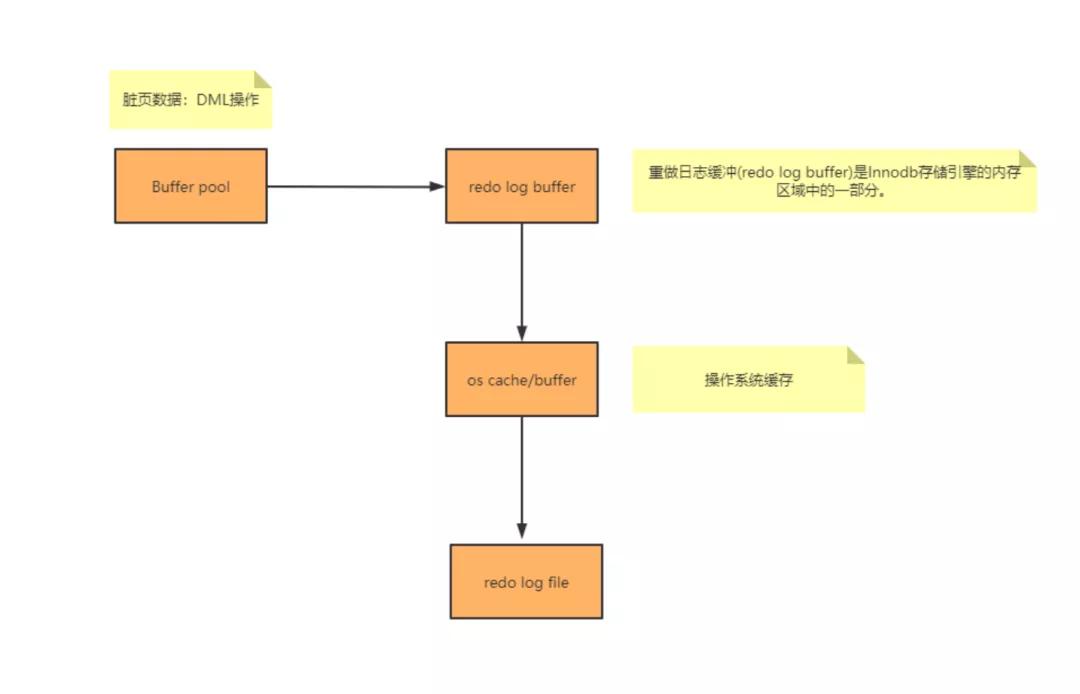
上圖是一個簡單的重做日志寫入流程。
在上圖中提到倆個陌生概念,Buffer pool、redo log buffer,這個倆個都是 Innodb 存儲引擎的內存區域的一部分。
而 redo log file 是位于磁盤位置。也就說當有 DML(insert、update、delete)操作時,數據會先寫入 Buffer pool,然后在寫到重做日志緩沖區。
重做日志緩沖區會根據刷盤機制來進行寫入重做日志中。
這個機制的設置參數為 innodb_flush_log_at_trx_commit,參數分別為 0,1,2。
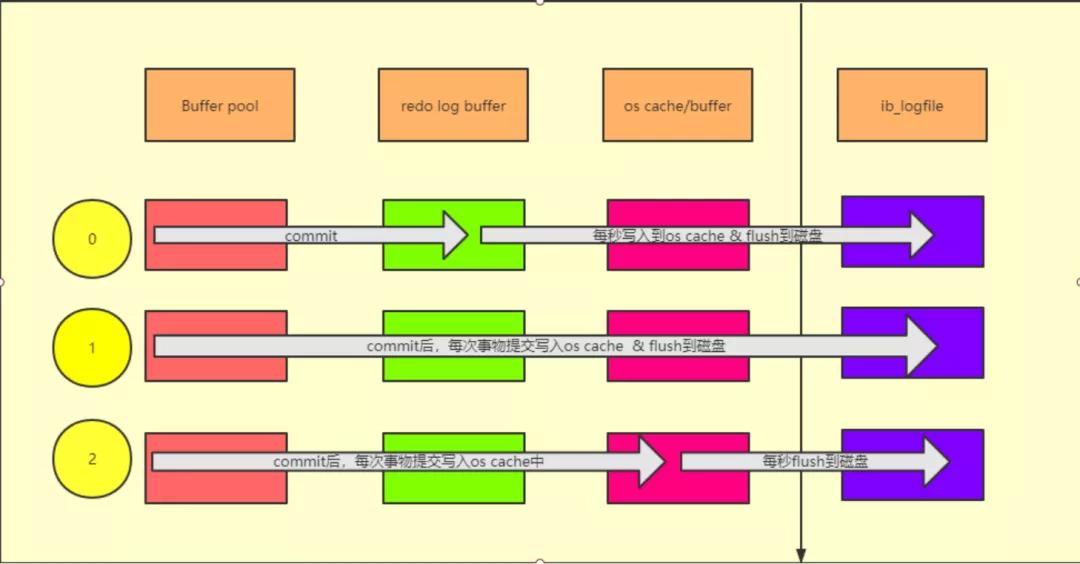
上圖即為重做日志的寫入策略:
- 當這個參數的值為 0 的時,提交事務之后,會把數據存放到 redo log buffer 中,然后每秒將數據寫進磁盤文件。
- 當這個參數的值為 1 的時,提交事務之后,就必須把 redo log buffer 從內存刷入到磁盤文件里去,只要事務提交成功,那么 redo log 就必然在磁盤里了。
- 當這個參數的值為 2 的情況,提交事務之后,把 redo log buffer 日志寫入磁盤文件對應的 os cache 緩存里去,而不是直接進入磁盤文件,1 秒后才會把 os cache 里的數據寫入到磁盤文件里去。
②服務器異常停止對事物如何應對(事物寫入過程)
事物寫入過程如下:
- 當參數為 0 時,前一秒的日志都保存在日志緩沖區,也就是內存上,如果機器宕掉,可能丟失 1 秒的事務數據。
- 當參數為 1 時,數據庫對 IO 的要求就非常高了,如果底層的硬件提供的 IOPS 比較差,那么 MySQL 數據庫的并發很快就會由于硬件 IO 的問題而無法提升。
- 當參數為 2 時,數據是直接寫進了 os cache 緩存,這部分屬于操作系統部分,如果操作系統部分損壞或者斷電的情況會丟失 1 秒內的事物數據,這種策略相對于第一種就安全了很多,并且對 IO 要求也沒有那么高。
小結:
- 關于性能:0>2>1
- 關于安全:1>2>0
根據以上結論,所以說在 MySQL 數據庫中,刷盤策略默認值為 1,保證事物提交之后,數據絕對不會丟失。
③回滾日志(undo log)(原子性實現原理)
回滾日志保證了事物的原子性。回滾日志相對重做日志來說沒有那么復雜的流程。
當事物對數據庫進行修改時,Innodb 引擎不僅會記錄 redo log 日志,還會記錄 undo log 日志。
如果事物失敗,或者執行了 rollback,為了保證事物的原子性,就必須利用 undo log 日志來進行回滾操作。
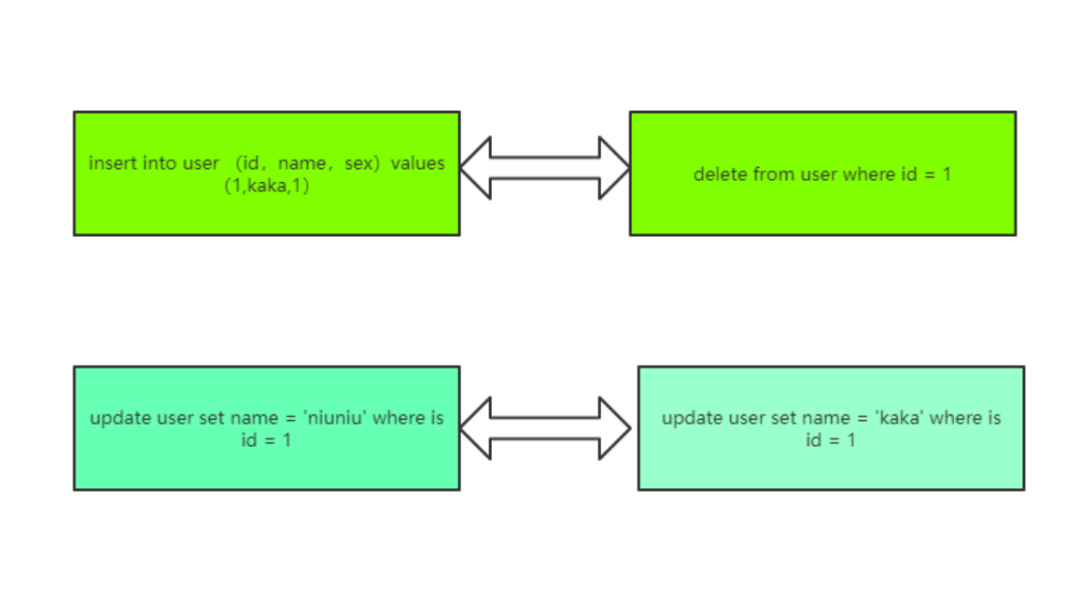
回滾日志的存儲形式如下:在 undo log 日志文件,事物中使用的每條 insert 都對應了一條 delete,每條 update 也都對應一條相反的 update 語句。
注意:系統發生宕機或者數據庫進程直接被殺死。當用戶再次啟動數據庫進程時,還能夠立刻通過查詢回滾日志將之前未完成的事物進程回滾。
這也就需要回滾日志必須先于數據持久化到磁盤上,是需要先寫日志后寫數據庫的主要原因。回滾日志不僅僅可以保證事物的原子性,還是實現 mvcc 的重要因素。
以上就是關于事物的倆大日志,重做日志、回滾日志的理解。
鎖機制
鎖在 MySQL 中是是非常重要的一部分,鎖對 MySQL 數據訪問并發有著舉足輕重的作用。
所以說鎖的內容以及細節是十分繁瑣的,本節只是對 Innodb 鎖的一個大概整理。
MySQL中有三類鎖,分別為行鎖、表鎖、頁鎖。首先需要明確的是這三類鎖是是歸屬于那種存儲引擎的:
- 行鎖:Innodb 存儲引擎
- 表鎖:Myisam、MEMORY 存儲引擎
- 頁鎖:BDB 存儲引擎
①行鎖
行鎖又分為共享鎖、排它鎖,也被稱之為讀鎖、寫鎖,Innodb 存儲引擎的默認鎖。
共享鎖(S):假設一個事物對數據 A 加了共享鎖(S),則這個事物只能讀 A 的數據。
其他事物只能再對數據 A 添加共享鎖(S),而不能添加排它鎖(X),直到這個事物釋放了數據 A 的共享鎖(S)。
這就保證了其他事物也可以讀取 A 的數據,但是在這個事物沒有釋放在 A 數據上的共享鎖(S)之前不能對 A 做任何修改。
排它鎖(X):假設一個事物對數據 A 添加了排它鎖(X),則只允許這個事物讀取和修改數據 A。
其他任何事物都不能在對數據A添加任何類型的鎖,直至這個事物釋放了數據 A 上的鎖。
排它鎖阻止其它事物獲取相同數據的共享鎖(S)、排它鎖(X),直至釋放排它鎖(X)。
特點如下:
- 只針對單一數據進行加鎖
- 開銷大
- 加鎖慢
- 會出現死鎖
- 鎖粒度最小,發生鎖沖突的概率越低,并發越高
還記得在上文中提到的事物并發帶來的問題、臟讀、不可重讀讀、幻讀。
學習到了這里,應該就明白可重復讀(Repeatable Read)如何解決臟讀、不可重讀讀了。
臟讀、和不可重復讀的解決方案很簡單,寫前加排它鎖(X),事務結束才釋放,讀前加共享鎖(S),事務結束就釋放。
②表鎖
表鎖又分為表共享讀鎖、表獨占寫鎖,也被稱之為讀鎖、寫鎖,Myisam 存儲引擎的默認鎖。
表共享讀鎖:針對同一個份數據,可以同時讀取互不影響,但不允許寫操作。
表獨占寫鎖:當寫操作沒有結束時,會阻塞所有讀和寫。
特點如下:
- 對整張表加鎖
- 開銷小
- 加鎖快
- 無死鎖
- 鎖粒度最大,發生鎖沖突的概率越大,并發越小
本文主要說明 Innodb 和 Myisam 的鎖,頁鎖不就不做詳細說明了。
③如何加鎖
表鎖:
- 隱式加鎖:默認自動加鎖釋放鎖,select 加讀鎖、update、insert、delete 加寫鎖。
- 手動加鎖:lock table tableName read;(添加讀鎖)、lock table tableName write(添加寫鎖)。
- 手動解鎖:unlock table tableName(釋放單表)、unlock table(釋放所有表)。
行鎖:
- 隱式加鎖:默認自動加鎖釋放鎖,只有 select 不會加鎖,update、insert、delete 加排它鎖。
- 手動加共享鎖:select id name from user lock in share mode。
- 手動加排它鎖:select id name form user for update。
- 解鎖:正常提交事物(commit)、事物回滾(rollback)、kill 進程。
總結
本文主要對事物的重點知識點進行解讀,內容總結。
事物四大特征實現原理:
- 原子性:使用事物日志的回滾日志(undo log)實現
- 隔離性:使用 mvcc 實現(幻讀問題除外)
- 持久性:使用事物日志的重做日志(redo log)實現
- 一致性:是事物追求的最終目標,原子性、隔離性、持久性都是為了保證數據庫一致性而存在
事物并發出現問題的區別:
- 臟讀與不可重復讀的區別:臟讀是讀取沒有提交事物的數據、不可重復讀讀取的是已提交事物的數據。
- 幻讀與不可重復讀的區別:都是讀取的已提交事物的數據(與臟讀不同),幻讀針對的是一批數據,例如個數。不可重復讀針對的是單一數據。
事物日志:
- 重做日志(redo log):實現了事物的持久性,提交事物后不是直接修改數據庫,而是保證每次事物操作讀寫入 redo log 中。并且落盤會有三種策略(詳細看四-1節)。
- 回滾日志(undo log):實現了事物的原子性,針對 DML 的操作,都會有記錄相反的 DML 操作。
作者:咔咔
編輯:陶家龍
征稿:有投稿、尋求報道意向技術人請添加小編微信 gordonlonglong
【51CTO原創稿件,合作站點轉載請注明原文作者和出處為51CTO.com】























