面試官問我zookeeper選舉過程,我當場給他講了源碼
集群概述
zookeper 在生產環境中通常都是通過集群方式來部署的,以保證高可用, 下面是 zookeeper 官網給出的一個集群部署結構圖:
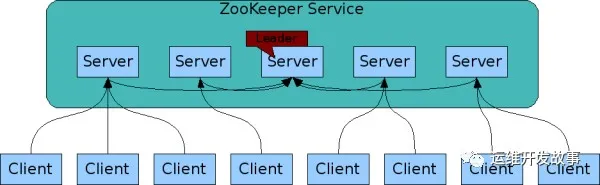
從上圖可以得出, zookeeper server 的每個節點都和主節點保持通訊的,每個節點上面都存儲有數據和日志的備份,只有當大多數節點可用集群才是可用的。本文主要是基于 zookeeper 3.8.0 講解, 主要是通過源碼的維度來分析 zookeeper 選舉過程 對于 zookeeper 的源碼編譯大家可以參考:編譯運行Zookeeper源碼
集群節點狀態
集群節點狀態定義在 QuorumPeer#ServerState 枚舉,主要是包含 LOOKING、FOLLOWING、LEADING、OBSERVING 四個狀態, 下面是定義的代碼和說明
- public enum ServerState {
- // 尋找leader狀態。當服務器處于該狀態時,它會認為當- 前集群中沒有leader,因此需要進入leader選舉狀態。
- LOOKING,
- // 跟隨者狀態。表明當前服務器角色是 follower。
- FOLLOWING,
- // 領導者狀態。表明當前服務器角色是 leader。
- LEADING,
- // 觀察者狀態。表明當前服務器角色是 observer。
- OBSERVING
- }
Leader 選舉過程
啟動和初始化
QuorumPeerMain 是 zookeeper 的啟動類, 通過 main 方法啟動
- // 不展示非核心代碼
- public static void main(String[] args) {
- QuorumPeerMain main = new QuorumPeerMain();
- main.initializeAndRun(args);
- }
- protected void initializeAndRun(String[] args) throws ConfigException, IOException, AdminServerException {
- // 集群模式啟動
- if (args.length == 1 && config.isDistributed()) {
- runFromConfig(config);
- } else {
- }
- }
- public void runFromConfig(QuorumPeerConfig config) throws IOException, AdminServerException {
- // quorumPeer 啟動
- quorumPeer.start();
- }
QuorumPeer 是一個線程實例類,當調用 start 方法過后會致性 QuorumPeer#run() 方法, 進行集群狀態的判斷最終進入是否執行選舉或者同步集群節點數據信息等一系列的操作,下面是核心代碼:
- @Override
- public void run() {
- try {
- while (running) {
- switch (getPeerState()) {
- case LOOKING:
- // 投票給自己
- setCurrentVote(makeLEStrategy().lookForLeader());
- break;
- case OBSERVING:
- setObserver(makeObserver(logFactory));
- observer.observeLeader();
- break;
- case FOLLOWING:
- setFollower(makeFollower(logFactory));
- follower.followLeader();
- break;
- case LEADING:
- setLeader(makeLeader(logFactory));
- leader.lead();
- setLeader(null);
- break;
- }
- }
- } finally {
- }
- }
進行選舉
FastLeaderElection 是選舉的核心類 ,在這個類里面有對投票和選票的處理過程
- public Vote lookForLeader() throws InterruptedException {
- // 創建一個當前選舉周期的投票箱
- Map<Long, Vote> recvset = new HashMap<Long, Vote>();
- // 創建一個投票箱。這個投票箱和recvset 不一樣。
- // 存儲當前集群中如果已經存在Leader了的投票
- Map<Long, Vote> outofelection = new HashMap<Long, Vote>();
- int notTimeout = minNotificationInterval;
- synchronized (this) {
- // 遞增本地選舉周期
- logicalclock.incrementAndGet();
- // 為自己投票
- updateProposal(getInitId(), getInitLastLoggedZxid(), getPeerEpoch());
- }
- // 廣播投票
- sendNotifications();
- SyncedLearnerTracker voteSet = null;
- // 如果當前服務器的狀態為Looking,和stop參數為false,那么進行選舉
- while ((self.getPeerState() == ServerState.LOOKING) && (!stop)) {
- if (n.electionEpoch > logicalclock.get()) {
- logicalclock.set(n.electionEpoch);
- recvset.clear();
- // totalOrderPredicate 投票 PK
- if (totalOrderPredicate(n.leader, n.zxid, n.peerEpoch, getInitId(), getInitLastLoggedZxid(), getPeerEpoch())) {
- updateProposal(n.leader, n.zxid, n.peerEpoch);
- } else {
- updateProposal(getInitId(), getInitLastLoggedZxid(), getPeerEpoch());
- }
- sendNotifications();
- } else if (totalOrderPredicate(n.leader, n.zxid, n.peerEpoch, proposedLeader, proposedZxid, proposedEpoch)) {
- updateProposal(n.leader, n.zxid, n.peerEpoch);
- sendNotifications();
- }
- // 監聽通信層接收的投票
- Notification n = recvqueue.poll(notTimeout, TimeUnit.MILLISECONDS);
- // 放入投票箱
- recvset.put(n.sid, new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch));
- // 過半邏輯
- voteSet = getVoteTracker(recvset, new Vote(proposedLeader, proposedZxid, logicalclock.get(), proposedEpoch));
- }
- }
totalOrderPredicate 主要是選票 PK 的邏輯,我們再來看看代碼:
- protected boolean totalOrderPredicate(long newId, long newZxid, long newEpoch, long curId, long curZxid, long curEpoch) {
- if (self.getQuorumVerifier().getWeight(newId) == 0) {
- return false;
- }
- return ((newEpoch > curEpoch)
- || ((newEpoch == curEpoch)
- && ((newZxid > curZxid)
- || ((newZxid == curZxid)
- && (newId > curId)))));
- }
選舉過程是這個樣子的 ,其實官方也給出了注釋:
- 先比較選舉的屆數,屆數高的說明是最新一屆,勝出
- 再比較zxid,也就是看誰的數據最新,最新的勝出
- 最后比較serverid,這是配置文件指定的,節點id大者勝出 選舉完成后通過 sendNotifications(); 通知其他的節點。
過程總結
前面我粗略的講解 zookeeper 從啟動過程在到選舉,選舉結果同步的,以及如何進行投票的選舉結果確認過程,但是 zookeeper 作為一個高性能、高可靠的分布式協調中間件,在很多設計的細節也是非常的優秀的。
投票過程
通常情況下,在投票的過程中 zxid 越大越有可能成為 leader 主要是由于 zxid 越大該節點的數據越多,這樣的話就可以減少數據的同步過程中節點事務的撤銷和日志文件同步的比較過程,以提升性能。下面是 5 個 zookeeper 節點選舉的過程。
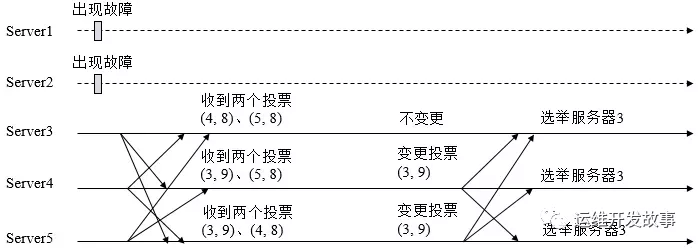
注: (sid, zxid), 當前場景為 server1 ,server2 出現故障 , server3 的 zxid = 9 , server4 和 server5 的 zxid 為 8. 進行兩輪選舉,最終選出 sever3 為 leader 節點
多層網絡架構
在前面的分析過程中我省略了 Zookeeper 節點之間通訊的 NIO 操作, 這部分簡單來講 zookeeper 將他們劃分為傳輸層和業務層。通過 SendWorker、RecvWorker 處理網絡層數據包, WorkerSender 和 WorkerReceiver 處理業務層的數據。
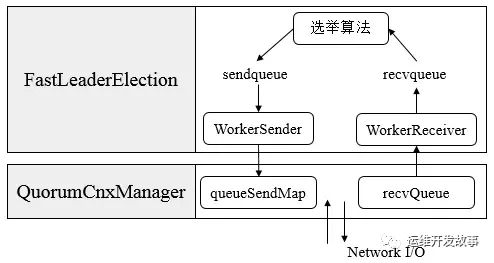
這里會涉及到多線程操作,zookeeper 在源碼中也給出了大量的日志信息,對于初學者有一定的難度,對此大家可以參考下面的 Zookeeper 選舉源碼流程 這部分的流程圖來輔助分析。
Leader 選舉源碼流程
結合上面的梳理,我對 zookeeper 啟動和選舉的流程做了一個比較詳細的梳理。大家可以結合 zookeeper 源碼來理解。
參考文檔
- apache zookeeper 官網
- Zookeeper的領導者選舉機制解析
- 理解Zookeeper的Leader選舉過程