













懵了!女朋友突然問我MVCC實現原理
原創【51CTO.com原創稿件】都知道事務的可重復讀級別實現原理是使用 MVCC 實現的,那么你對 MVCC 的底層實現原理知道多少呢!面試高頻點,你值得擁有。
圖片來自 Pexels
MVCC 到底是什么?
MVCC 即多版本控制器,其特點就是在同一時間,不同事務可以讀取到不同版本的數據,從而去解決臟讀和不可重復讀的問題。
這樣的解釋你看了不下幾十遍了吧!但是你真的理解什么是多版本控制器嗎?
①生活案例:搬家
最近小 Q 跟自己的女朋友需要搬到新家,由于出小區的的時候需要支付當月的物業費。于是小 Q 跟自己的女朋友同時登陸了小區提供的物業繳費系統。
②悲觀并發控制
假設小 Q 正在查當月需要繳納的費用是多少,然后進行支付的時候,此時小 Q 查詢的這條數據是已經被鎖定的。
那么小 Q 女朋友是無法訪問該數據的,直至小 Q 支付完成或者退出系統將悲觀鎖釋放,小 Q 的女朋友才可以查詢到數據。
悲觀鎖保證在同一時間只能有一個線程訪問,默認數據在訪問的時候會產生沖突,然后在整個過程都加上了鎖。
這樣的系統對于站在程序員的角度看就是毫無用戶體驗感,如果多個人需要同時訪問一條信息,只能在一臺設備上看嘍!
③樂觀并發控制
在小 Q 查看物業費欠費情況,并且支付的同時,小 Q 的女朋友也可以訪問到該數據。
樂觀鎖認為即使在并發環境下,也不會產生沖突問題,所以不會去做加鎖操作。而是在數據提交的時候進行檢測,如果發現有沖突則返回沖突信息。
小結:Innodb 的 MVCC 機制就是樂觀鎖的一種體現,讀不加鎖,讀寫不沖突,在不加鎖的情況下能讓多個事務進行并發讀寫,并且解決讀寫沖突問題,極大的提高系統的并發性。
悲觀鎖、樂觀鎖
鎖按照粒度分為表鎖、行鎖、頁鎖;按照使用方式分為共享鎖、排它鎖;根據思想分為樂觀鎖、悲觀鎖。
無論是樂觀鎖、悲觀鎖都只是一種思想而已,并不是實際的鎖機制,這點一定要清楚。
①悲觀鎖(悲觀并發控制)
悲觀鎖實際為悲觀并發控制,縮寫 PCC。
悲觀鎖持消極態度,認為每一次訪問數據時,總是會發生沖突,因此,每次訪問必須先鎖住數據,完成訪問后在釋放鎖。
保證在同一時間只有單個線程可以訪問,實現數據的排它性。同時悲觀鎖使用數據庫自身的鎖機制實現,可以解決讀-寫,寫-寫的沖突。
那么在什么場景下可以使用悲觀鎖呢?悲觀鎖適用于在寫多讀少的并發環境下使用,雖然并發效率不高,但是保證了數據的安全性。
②樂觀鎖(樂觀并發控制)
跟悲觀鎖一樣,樂觀鎖實際為樂觀并發控制,縮寫為OCC。
樂觀鎖相對于悲觀鎖而言,認為即使在并發環境下,外界對數據的操作不會產生沖突,所以不會去加鎖,而是會在提交更新的時候才會正式的對數據的沖突與否進行檢測。
如果發現沖突,要么再重試一次,要么切換為悲觀的策略。樂觀并發控制要解決的是數據庫并發場景下的寫-寫沖突,指用無鎖的方式去解決。
MVCC 解決了哪些問題
在事務并發的情況下會產生以下問題:
- 臟讀:讀取其他事務未提交的數據。
- 不可重復讀:一個事務在讀取一條數據時,由于另一個事務修改了這條數據,導致前后讀取的數據不一致。
- 幻讀:一個事務先讀取了某個范圍的數量,同時另一個事務新增了這個范圍的數據,再次讀取發現倆次得到的結果不一致。
MVCC 在 Innodb 存儲引擎的實現主要是為了提高數據庫并發能力,用更好的方式去處理讀–寫沖突,同時做到不加鎖、非阻塞并發讀寫。
但是 MVCC 可以解決臟讀,不可重復讀,MVCC 使用快照讀解決了部分幻讀問題,但是在修改時還是使用的當前讀,所以還是存在幻讀問題,幻讀的問題最終就是使用間隙鎖解決。
當前讀、快照讀
在了解 MVCC 是如何解決事務并發帶來的問題之前,需要先明白倆個概念,當前讀、快照讀。
①當前讀
給讀操作加上共享鎖、排它鎖,DML 操作加上排它鎖,這些操作就是當前讀。
共享鎖、排它鎖也被稱之為讀鎖、寫鎖。共享鎖與共享鎖是共存的,但是如果要修改、添加、刪除時,必須等到共享鎖釋放才可進行操作。
因為在 Innodb 存儲引擎中,DML 操作都會隱式添加排它鎖。所以說當前讀所讀取的記錄就是最新的記錄,讀取數據時加上鎖,保證其他事務不能修改當前記錄。
②快照讀
如果你看到這里就默認你對隔離級別有一定的了解哈!快照讀的前提是隔離級別不是串行級別,串行級別的快照讀會退化成當前讀。
快照讀的出現旨在提高事務并發性,其實現基于本文的主角 MVCC 即多版本控制器。
MVCC 可以認為就是行鎖的一個變種,但是它在很多情況下避免了加鎖操作。所以說快照讀讀取的數據有可能不是最新的,而是之前版本的數據。
為什么要提到快照讀呢!因為在 read-view 就是通過快照讀生成的,為了防止后文概念模糊,所以在這里進行說明。
③如何區分當前讀、快照讀
不加鎖的簡單的 select 都屬于快照讀:
- select id name user where id = 1;
與之對應的則是當前讀,給 select 加上共享鎖、排它鎖:
- select id name from user where id = 1 lock in share mode;
- select id name from user where id = 1 for update;
MVCC 實現三大要素
終于來到本文最終要的部分了,前邊的敘述都是為了原理這一塊做的鋪墊。
在這之前需要知道 MVCC 只在 REPEATABLE READ(可重復讀) 和 READ COMMITTED(已讀提交)這倆種隔離級別下適用。
MVCC 實現原理是由倆個隱式字段、undo 日志、Read view 來實現的。
①隱式字段
在 Innodb 存儲引擎中,在有聚簇索引的情況下每一行記錄中都會隱藏倆個字段,如果沒有聚簇索引則還有一個 6byte 的隱藏主鍵。
這倆個隱藏列一個記錄的是何時被創建的,一個記錄的是什么時候被刪除。這里不要理解為是記錄的是時間,存儲的是事務 ID。
倆個隱式字段為 DB_TRX_ID,DB_ROLL_PTR,沒有聚簇索引還會有 DB_ROW_ID 這個字段:
- DB_TRX_ID:記錄創建這條記錄上次修改他的事務 ID。
- DB_ROLL_PTR:回滾指針,指向這條記錄的上一個版本。
隱式字段實際還有一個 delete flag 隱藏字段,即記錄被更新或刪除,這里的刪除并不代表真的刪除,而是將這條記錄的 delete flag 改為 true(這里埋下一個伏筆,數據庫的刪除是真的刪除嗎?)
②undo log(回滾日志)
之前對 undo log 的作用只提到了回滾操作實現原子性,現在需要知道的另一個作用就是實現 MVCC 多版本控制器。
undo log 細分為倆種:
- insert 時產生的 undo log、update
- delete 時產生的 undo log
在 Innodb 中 insert 產生的 undo log 在提交事務之后就會被刪除,因為新插入的數據沒有歷史版本,所以無需維護 undo log。
update 和 delete 操作產生的 undo log 都屬于一種類型,在事務回滾時需要,而且在快照讀時也需要,則需要維護多個版本信息。
只有在快照讀和事務回滾不涉及該日志時,對應的日志才會被 purge 線程統一刪除。
purge 線程會清理 undo log 的歷史版本,同樣也會清理 del flag 標記的記錄。
寫到這里關于 undo log 在 MVCC 中的作用估計還是蒙圈的。
undo log 在 MVCC 中的作用:undo log 保存的是一個版本鏈,也就是使用 DB_ROLL_PTR 這個字段來連接的。當數據庫執行一個 select 語句時會產生一致性視圖 read view。
那么這個 read view 是由在查詢時所有未提交事務 ID 組成的數組,數組中最小的事務 ID 為 min_id 和已創建的最大事務 ID 為 max_id 組成,查詢的數據結果需要跟 read-view 做比較從而得到快照結果。
所以說 undo log 在 MVCC 中的作用就是為了根據存儲的事務 ID 做比較,從而得到快照結果。
③undo log 底層實現
假設一開始的數據為下圖:
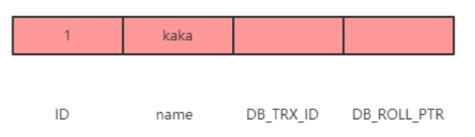
此時執行了一條更新的 SQL 語句:
- update user set name = 'niuniu where id = 1'
那么 undo log 的記錄就會發生變化,也就是說當執行一條更新語句時會把之前的原有數據拷貝到 undo log 日志中。
同時你可以看見最新的一條記錄在末尾處連接了一條線,也就是說 DB_ROLL_PTR 記錄的就是存放在 undo log 日志的指針地址。
最終有可能需要通過指針來找到歷史數據:
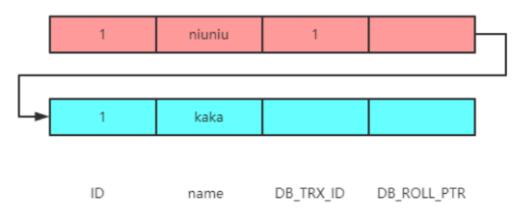
④read-view
當執行 SQL 語句查詢時會產生一致性視圖,也就是 read-view,它是由查詢的那一時間所有未提交事務 ID 組成的數組,和已經創建的最大事務 ID 組成的。
在這個數組中最小的事務 ID 被稱之為 min_id,最大事務 ID 被稱之為 max_id,查詢的數據結果要根據 read-view 做對比從而得到快照結果。
于是就產生了以下的對比規則,這個規則就是使用當前的記錄的 trx_id 跟 read-view 進行對比,對比規則如下。
⑤版本鏈對比規則
如果落在 trx_id
如果落在 trx_id>max_id,表示此版本是由將來啟動的事務生成的,是肯定不可見的。
如果落在 min_id<=trx_id<=max_id 會存在倆種情況:
- 如果 row 的 trx_id 在數組中,表示此版本是由還沒提交的事務生成的,不可見,但是當前自己的事務是可見的。
- 如果 row 的 trx_id 不在數組中,表明是提交的事務生成了該版本,可見。
在這里還有一個特殊情況那就是對于已經刪除的數據,在之前的 undo log 日志講述時說了 update 和 delete 是同一種類型的 undo log,同樣也可以認為 delete 就是 update 的特殊情況。
當刪除一條數據時會將版本鏈上最新的數據復制一份,然后將 trx_id 修改為刪除時的 trx_id,同時在該記錄的頭信息中存在一個 delete flag 標記,將這個標記寫上 true,用來表示當前記錄已經刪除。
在查詢時按照版本鏈的規則查到對應的記錄,如果 delete flag 標記位為 true,意味著數據已經被刪除,則不返回數據。
如果你對這里的 read-view 的生成和版本鏈對比規則不懂,不要著急,也不要在這里浪費時間,請繼續往下看,我會使用一個簡單的案例和一個復雜的案例給大家重現上述的規則。
MVCC 底層原理
案例一
下圖是準備的素材,這里應該都理解 select 返回的結果為 niuniu,即事務 102 修改后的結果:

在上圖中可以看到有三個事務在進行。事務 ID 為 100、101 是修改的其他表,只有事務 ID 為 102 修改的需要查詢的這張表。
接下來看看 select 這一列查詢返回的結果是不是就是事務 ID 為 102 修改的結果。
此時生成的 read-view 為 [100,101],102,那么現在就可以返回去看一下 read-view 規則,在這里事務 ID100 就是 min_id,事務 ID102 就是 max_id。
這個 select 語句返回結果肯定是 niuniu。那么接下來看一下在 MVCC 中是如何查找數據的。
當前版本鏈:
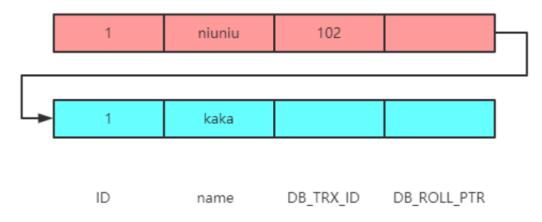
那么就會拿著這個 trx_id 為 102 進行比對,會發現這個 102 就是 max_id,然后你再看一下版本鏈的對比規則中第三種情況。
如果落在 min_id<=trx_id<=max_id 會存在倆種情況。此時信息就已經非常明確了,事務 ID102 是沒有在數組中的,所以表示這個版本是已經提交的事務生成的,那么就是可見的唄!
毫無疑問查詢會返回 niuniu 這個值,先通過這個簡單的案例讓你對版本鏈有一個簡單的理解,接下來將使用一個比較繁瑣的案例再來跟大家演示一遍。
案例二
本例要求知道 select 的第二次查詢結果。深黑色字體。同樣是在 kaka 那一條記錄的基礎上。
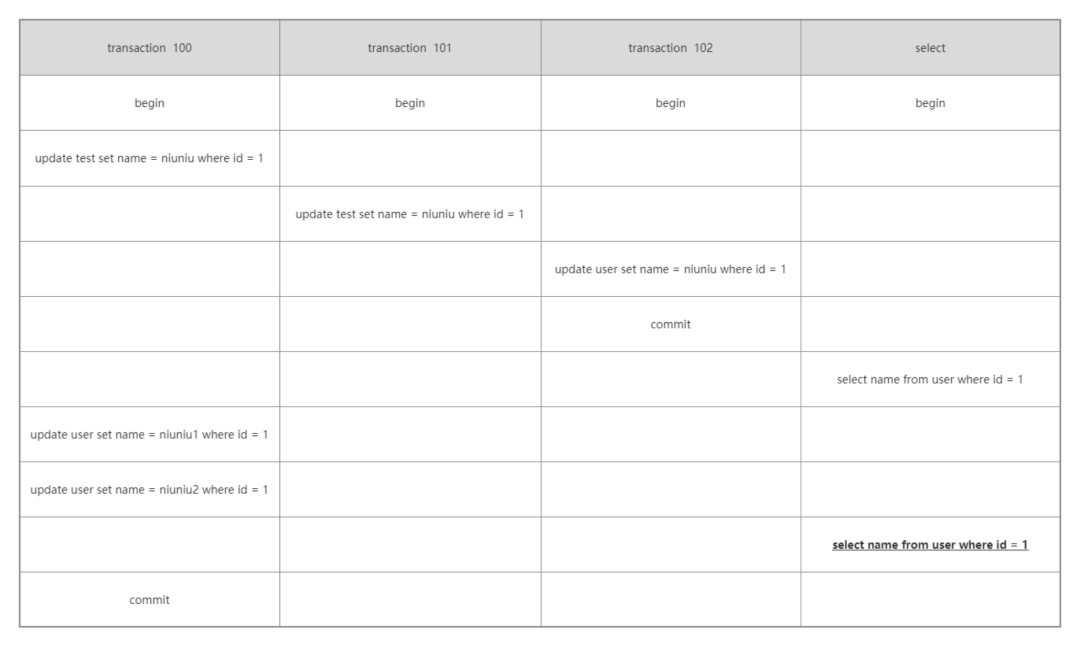
當事務 ID100 倆次更新后,版本鏈也會改變,此時的版本鏈如下圖。紅色部分為最新數據,藍色數據為 undo log 的版本鏈數據。

對于此時生成的 read-view 你會有什么疑問,在 RR 級別也就是可重復讀的隔離級別下。
當在一個事務下執行查詢時,所有的 read-view 都是沿用的第一條查詢語句生成的。
那此時的 read-view 也就是[100,101],102。
看一下底層查找步驟:
- 當前數據的事務 ID 為 100
- 根據規則會落在 min_id<=trx_id<=max_id 這個區間
- 并且當前行的事務 ID100 是在 read-view 的數組中的,表示此時的事務還沒有提交則不可見
- 繼續在版本鏈中往下尋找,此時找到的事務 ID 還是 100,跟上述流程一致
- 通過查找版本鏈,將發現事務 ID 為 102
- 102 是 read-view 的 max_id,同樣也會落在 min_id<=trx_id<=max_id 這個區間,但是跟之前不同的是,事務 102 是沒有在數組中的,表示這個版本事務已經提交了所以是可見的
- 最后返回的是 niuniu
案例三
為了讓大家體會一下可重復讀級別生成的 read-view 是根據在同一事務中第一條快照讀產生的,再來看一個案例。
此時的事務 ID101 也再對數據更新兩次,然后在進行查詢看一下會返回什么值:
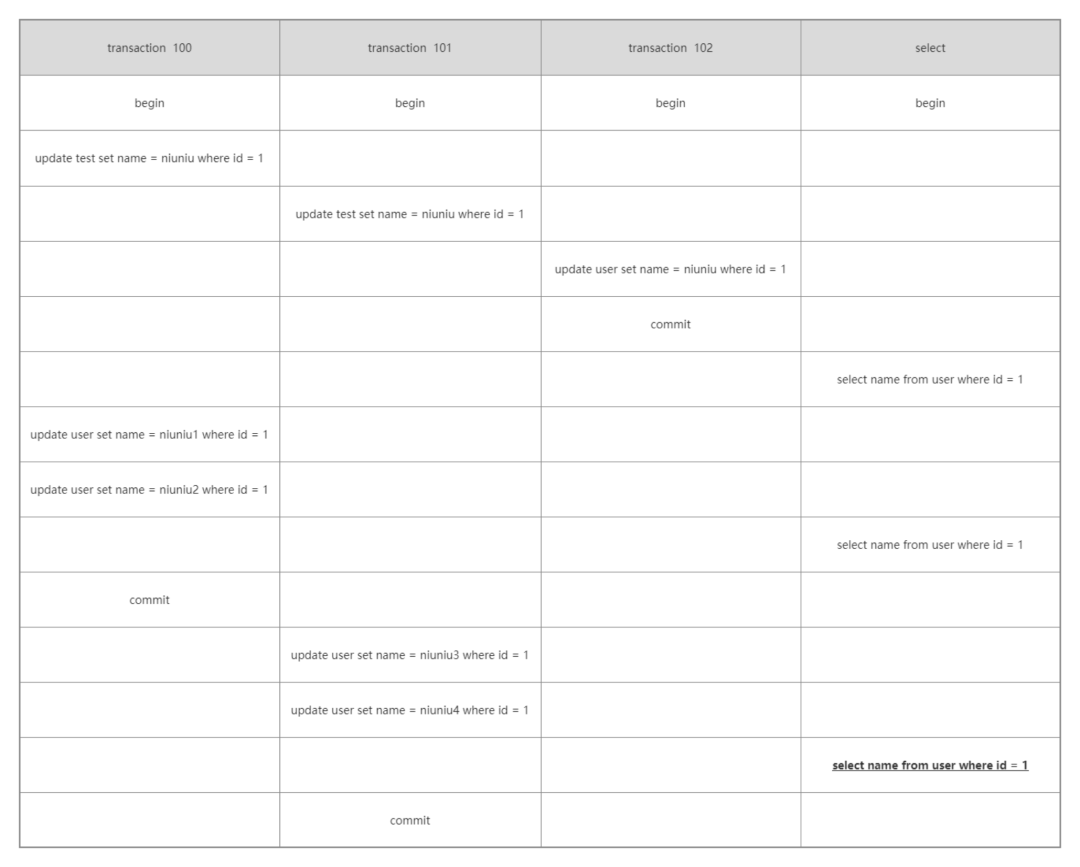
經過案例一、案例二的熟悉,現在對 undo log 的版本鏈和對比規則已經有了一定的了解了吧!
案例三就不在那么詳細的說明了,此時的版本鏈如下:
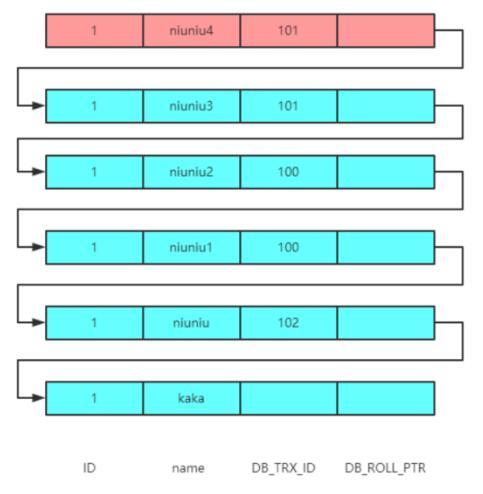
此時的 read-view 依然為[100,101],102。
那么首先會根據事務 101 去版本鏈對比,事務 101 和事務 100 都會落在 min_id<=trx_id<=max_id 這個區間,并且還都在數組中,所以數據是不可見的。
那么繼續往版本鏈中尋找就會到事務 102,這個是最大的事務 ID 并且不在數組中,所以是可見的。
于是最終的返回結果還是 niuniu。
案例四
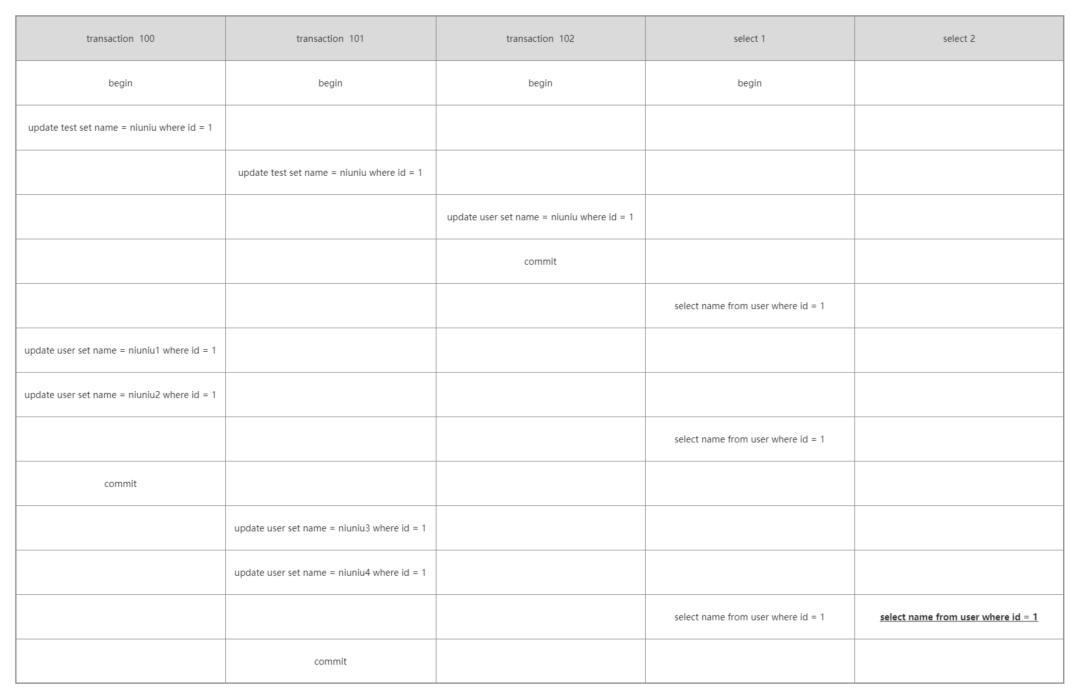
可以看到個案例三的圖不同的是新增了一個查詢語句,那么假設這兩條語句執行的時間都是一致的,它們返回的結果會相同嗎?
案例三查詢到的值為 niuniu:
其實現在版本鏈跟案例三也是一致的:
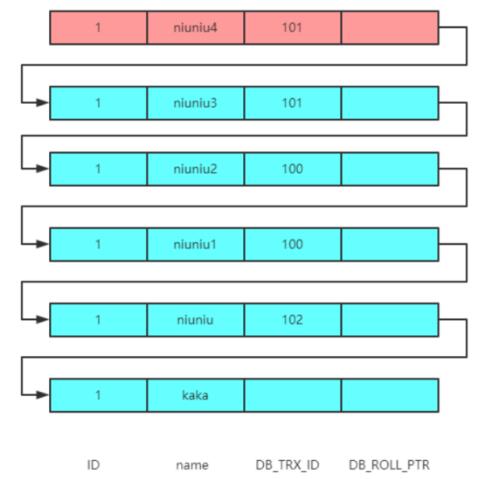
那么來理一下尋找過程:
- 首先這里的 read-view 發生了變化,此時的 read-view 為[101],102。
- 拿著當前的事務 ID101 跟版本鏈規則進行對比,落盤在 min_id<=trx_id<=max_id,并且在數組中,則數據不可見。
- 然后進入版本鏈,找到下一個數據的事務 ID,還是 101,與上一個一致。
- 接下來是事務 ID100。
- 事務 ID100 是落在 trx_id
- 所以最終返回結果為 niuniu2。
小結:在同一個事務中進行查詢,會沿用第一次查詢語句生成的 read-view(前提是隔離級別是在可重復讀)。
通過以上的四個案例,在版本鏈尋找過程中,可以總結出一個小技巧:
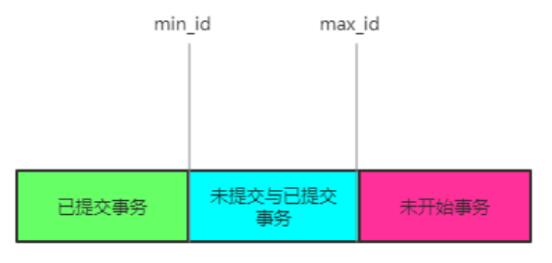
根據這個小技巧你可以很快的得知此版本是否可見:
- 如果當前的事務 ID 在綠色部分,是已經提交事務,則數據可見。
- 如果當前的事務 ID 在藍色部分,會有兩種情況,如果當前事務 ID 在 read-view 數組內,是沒有提交的事務不可見,如果不在數組內數據可見。
- 如果落在紅色部分,則不考慮,對于未來的事情不去想即可。
總結
閱讀本文后,在面試過程中極大可能會遇到的問題就是聊聊你對 MVCC 的認識。
本文內容從淺到深,從什么是 MVCC 到 MVCC 的底層實現,一步一步地陳述了 MVCC 的實現原理。
本文簡單總結:
- MVCC 在不加鎖的情況下解決了臟讀、不可重復讀和快照讀下的幻讀問題,一定不要認為幻讀完全是 MVCC 解決的。
- 對當前讀、快照讀理解,簡單點說加鎖就是當前讀,不加鎖的就是快照讀。
- MVCC 實現的三大要素:兩個隱式字段、回滾日志、read-view。
- 兩個隱式字段:DB_TRX_ID:記錄創建這條記錄最后一次修改該記錄的事務ID;DB_ROLL_PTR:回滾指針,指向這條記錄的上一個版本。
- undo log 在更新數據時會產生版本鏈,是 read-view 獲取數據的前提。
- read-view 當 SQL 執行查詢語句時產生的,是由為提交的事務 ID 組成的數組和創建的最大事務 ID 組成的。
- 版本鏈規則看第六節的小結即可。
作者:咔咔
編輯:陶家龍
征稿:有投稿、尋求報道意向技術人請添加小編微信 gordonlonglong

【51CTO原創稿件,合作站點轉載請注明原文作者和出處為51CTO.com】




















