邁向現代數據平臺的兩個步驟
在構建數據科學產品時,一個重要的方面是讓您的數據可用并準備使用。您需要一個平臺將數據帶到一起,并在整個公司中服務。但是你如何發展這樣一個數據平臺?閱讀數據倉庫,數據湖泊,湖泊和數據網格時,很容易丟失。它們是如何不同的,什么應該是第一步?
不同的數據平臺解決方案
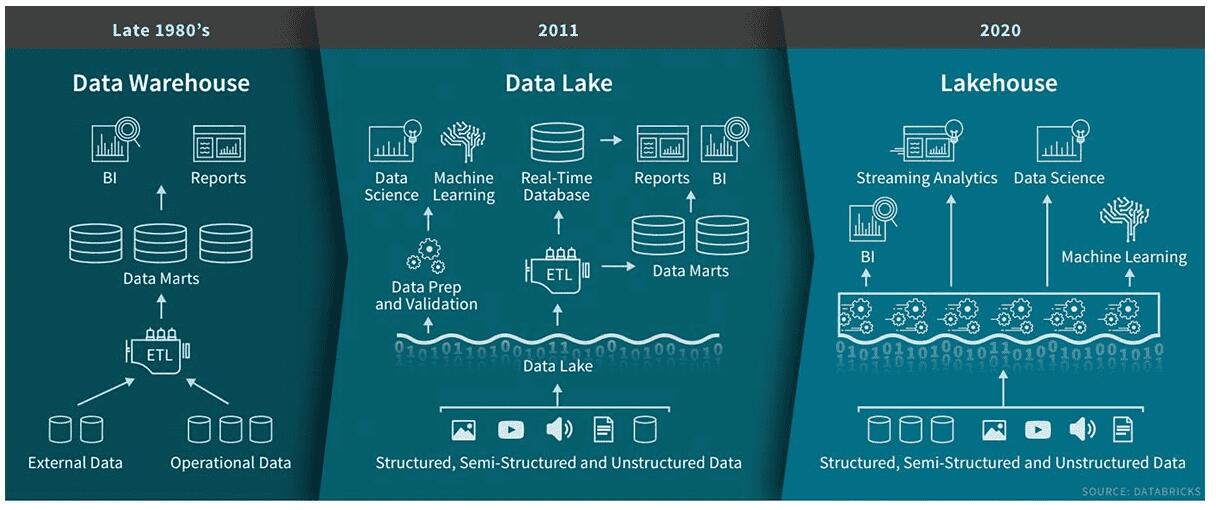 > Databricks’ perspective on DWH vs Data Lake vs Lakehouse
> Databricks’ perspective on DWH vs Data Lake vs Lakehouse
數據平臺是將數據帶到整個公司中的數據的環境。數據倉庫是第一個企業中央數據平臺。但是,隨著各種數據格式和源,它們并不足夠靈活。引入數據湖可以容易地從任何源以任何格式存儲原始數據。這是通過推遲模式創建和數據解釋來實現的,直到實際使用數據。這些湖泊經常轉向所謂的數據沼澤,在那里沒有人能夠有效地真正使用數據。添加了所有數據,但沒有準備對數據進行使用。繼任者是LakeHouse,數據湖與數據庫工具相結合,以輕松創建數據的可用視圖。替代方案是數據網,它不會集中數據,但是利用多個分散的數據環境,以更好地跨團隊進行規模。我稍后會更徹底地覆蓋數據網格。
但首先,讓我們看看我們實際解決的問題。這些不同數據平臺的驅動程序是什么?我將從烏托邦理想開始,我們正在追逐,繼續在實踐中出現的平臺,并用你可以采取的兩步包裝。在數據平臺方向上的兩個步驟,使機器學習解決方案,授權數據科學家,并分享內部工作方式。
烏托邦理想
如果來自所有部門的所有數據,則不會很容易訪問。從一個中心位置訪問,使您的所有數據科學家們可以在需要時獲得所需的數據。他們可以專注于先進的機器學習,而數據工程師可以確保數據已準備好使用。
讓我們見面Jane,我們的專家數據科學家。她正在開發一個新的數據科學產品:收入預測。中央數據平臺提供了客戶,產品和銷售的所有數據。Jane在平臺中構建完整數據集并將其加載到她的Jupyter Lab環境中。在與模型的目標與業務的一系列對齊之后,她很快開發了模型的第一版。
因此,該平臺提供了科學家需要開發她的模型的一切,包括數據,計算和工作環境。平臺開發人員(云和數據工程師)確保它是可擴展,實時和性能的。它們還提供數據譜系,數據治理和元數據等附加服務。科學家們完全賦予了工程困難。這在視覺上表示如下:
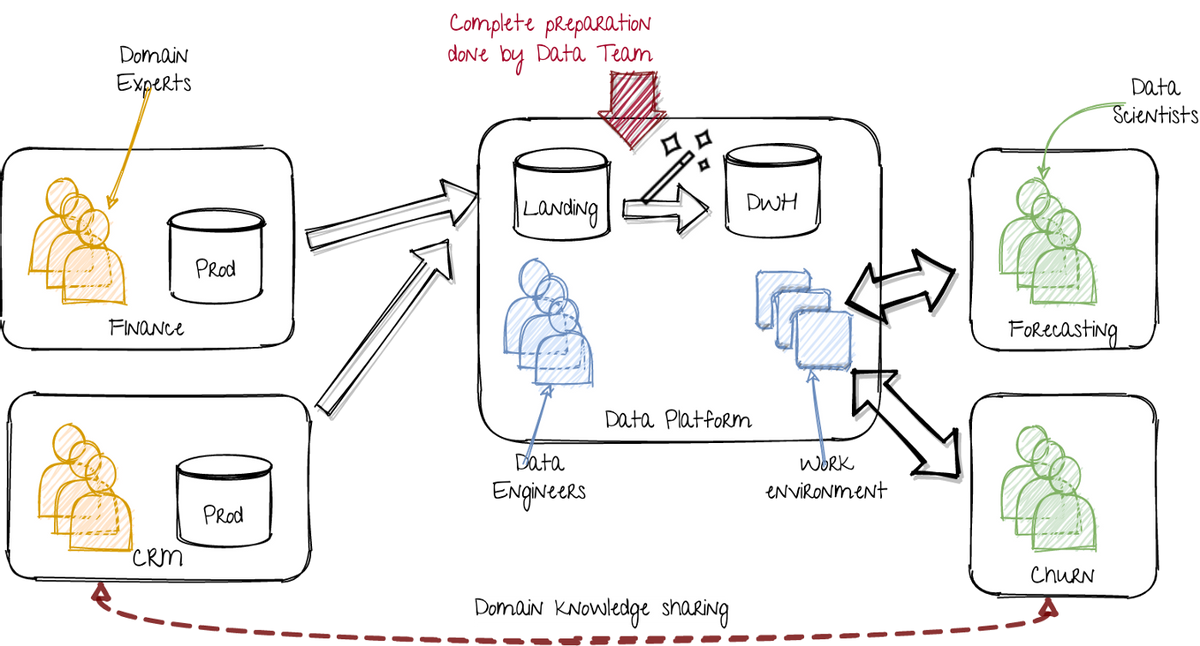
> Utopian world: Single data platform taking care of all the data issues. Image by author.
在左側,各個部門使用相應的數據運行其應用程序。在技術產品公司中,這包括在特定領域努力的團隊。數據可以居住在任何存儲中:MS Excel文件,數據庫,CSV文件,Kafka主題,云桶,您將其命名為。
在中間,數據平臺團隊提取該數據,并將其加載到數據湖的著陸區。第一步是標準化日期和數字格式和列名稱的方面。這可以包括為歷史觀點拍攝數據的快照。生成的數據集收集存儲在所謂的“暫存”圖層中。然后將數據組合并放置在靜電層中。策級層是包含相干數據集,唯一標識符和清晰關系的數據存儲。因此,我將此稱為DWH(數據倉庫)。但是,它可以是任何可用存儲,包括大規模云數據庫(BigQuery),Hive表,Blob存儲(S3)或Delta Lake Parquet文件。該策級層的目標是提供易于使用所有數據的總視圖。
在右側,數據科學團隊使用平臺的工作環境和數據集來解決它們的用例。
當這不起作用
理想的聲音很棒。不幸的是,簡的真實體驗略有不同:
Jane需要一些額外的數據集可以在數據平臺上提供。為了獲得頭部開始,金融部門為初步分析提供了一些CSV出口。簡探測了預測需要在產品組上報告,而這些數據是在各個產品上。在幾個會議之后,她了解哪些內部產品名稱屬于哪些組。產品的收入在組件中分開,部分是基礎產品,部分是附加組件。折扣是另一個故事;因為它們從總賬單中減去了,因此歸屬變得有點棘手。另一個驚喜。三個月前公共產品煥然一新,重命名,結合一些舊的利基產品。隨著一些困難而且只丟棄最小的數據,她管理將舊數據與大多數類似的新產品匹配。
管理數據平臺的數據工程師呢?好吧,他們只是入門:
最后,拾取了數據工程機票,數據工程師開始提取,加載和轉換各種數據集。第一個步驟很容易,但現在他們需要在數據上創建可用視圖。他們需要與各種(可能)未來的用戶交談以了解哪些轉變很重要。他們與簡言組織了一些細化會議。然后他們需要返回數據產生部門以弄清楚數據實際意味著什么,以及它如何映射到區域。該部門忙于一些新的內部產品。因此,他們將數據工程師轉發給數據科學團隊,這顯然已經完成了一些準備工作。
簡而言之,這不是非常順利的。
有一些關鍵問題:
- 數據科學家需要能夠創建使用情況特定的轉換。
- 平臺團隊需要準備他們不擁有的域的數據,以便于使用案例他們無法正常工作。
- 數據平臺團隊成為數據科學家團隊的瓶頸。
由此產生的解決方法
為了能夠解釋和轉換與特定用例相關的高度詳細數據,您需要很多域知識。每個用例還需要特定的數據準備。因此,數據工程師可以只做數據科學家所需的一部分。雖然數據科學家潛入商業案例,但他們獲得了很多域名知識。這使它們能夠準備數據。
這導致以下解決方法:
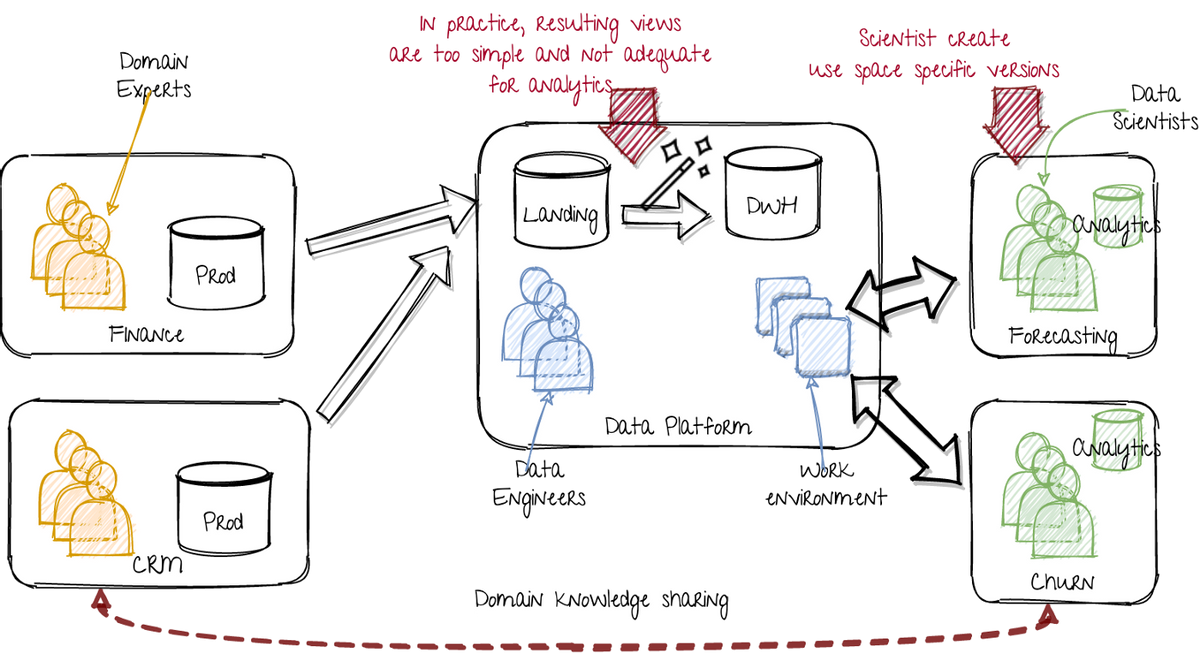
> Extra data storage within the data science teams. Image by author.
數據科學團隊現在將數據從中央數據平臺轉換為其模型培訓的準備。盡管數據平臺理想地提供完全可用的數據集,但實際上它太簡單,對所有客戶來說都不足夠了。
這種新的情況有一些好處:
- 數據科學家變得更加自我。
- 數據工程師不必為組織中的每個人創建視圖。它們可以專注于數據的標準化接口。
- 數據工程師可以專注于保持數據最近并提供良好的訪問方法。
但是,有些事情仍然出了問題:
- 數據科學家的數據集及其生產流水線與數據平臺具有相同的標準。它們不會監視,并不適用于失敗,并且任務調度并不標準化。
- 通過更分散的轉換,多個數據科學團隊正在重新發明眾所周知的輪子。
新的理想:數據網格
稍后,已經出現了數據網格的概念(請參閱此有趣的博客文章和此操作。數據來自組織中的多個位置。數據網格而不是創建所有組合數據的單個表示,而不是創建所有組合數據的單個表示。為了使數據公司廣泛可用,每個團隊的數據也被視為該團隊的產品。該公司的團隊還要注意創建其數據的可用意見。在這種情況下,機器學習(ML)產品團隊(數據科學家)還將將其轉換的數據作為產品提供給其他數據科學家。他們從各種其他產品團隊中獲取自己的數據。因此,每個產品團隊(或團隊團隊)不僅開發了他們的產品,而且還向其他團隊提供了可用的景色。在我解釋的是優勢之前,讓我畫出新的情況:
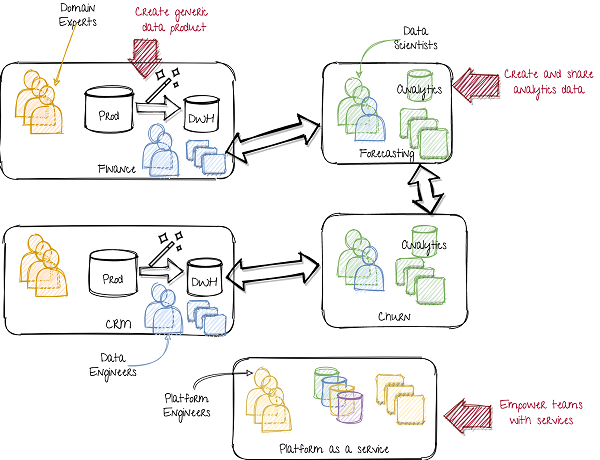
> A data mesh approach. Image by author.
在左側,部門或產品團隊將通用數據作為服務提供。雖然一組規范化表(DWH)是一種可能性,但它也可以包括事件流(Kafka)或Blob存儲。這需要產品團隊中的更多數據工程功能。而不是帶有數據工程師的中央團隊,數據工程師現在正在分布在所有產品團隊中,包括分析和ML團隊。
在中間,中央數據平臺已從數據產品團隊(要求域知識)更改為數據平臺作為服務團隊(需要技術知識)。他們開發內部平臺,授權所有團隊創建自己的數據存儲實例,功能存儲,數據處理,數據譜系,調度,過程監控,模型工件,模型服務實例等。因此,先前數據平臺團隊的所有技術技能都用于創建工具。這樣,每個團隊都可以成為自己(小規模)數據平臺團隊。這確保了整個公司的工作和高標準的統一方式。
在右側,數據科學團隊不僅是數據的消費者,還不僅是數據的制作者。他們的特征工程和數據宣傳的結果與其他數據科學團隊共享。
這有很多好處:
- 在域知識是創建的轉換。
- 數據平臺團隊瓶頸被刪除。
- 自給自足的產品團隊。
挑戰是:
- 將中心平臺設置為服務團隊。
- 防止新的中央數據平臺成為成為新瓶頸的服務團隊。
- 以共同的工作方式將所有團隊納入這種新方法。
在此設置中,中央平臺作為服務團隊(或團隊)具有關鍵作用。它們以簡單的自行服務方式設置并提供基礎架構和軟件服務。當他們創建平臺作為服務時,該團隊不需要大量的域特定知識。它只專注于技術方面,使其成為可重復的,并與所有團隊分享解決方案。這促進設置尺度非常好!我的同事Ruurtjan陣列在這個博客中展示了如何從團隊成分角度來實現縮放。然而,有一個大風險:采取瀑布方法。
數據網格方法解決了與數據重用相關的域知識的難度。這是通過將數據的責任移動到生產和使用該數據的團隊的責任來完成。而不是擁有所有數據的中央團隊,我們現在需要一個中央團隊,以方便所有團隊管理他們的數據。
陷阱是在讓這個中央團隊開始和運行時采取瀑布方法。在船上之前,不要創建所有必需的基礎架構和服務。只要沒有使用服務的單一團隊,就沒有增加值。因此,您需要迭代地增長和改善服務,而團隊則可以使用它。
第二個風險是使平臺成為服務團隊決定了工作方式。這將使團隊成為整個公司的瓶頸。在敏捷和迭代的方法中,一些團隊需要新的工具或服務,該服務尚未為公司采用準備好生產。作為服務團隊的平臺,而不是限制那些早期的采用者,而是應該允許和賦予新工具和服務的發現和試驗。讓他們授權產品團隊并加入軍隊。這將為兩支球隊提供分享工具和服務的經驗進一步跨本公司。
是否可以轉換到數據網?是否有可能在中央數據平臺和數據網之間具有內容?我們如何務實地采取第一步?我們盡快收獲盡快收益。在一個針對您組織的基礎架構功能上量身定制的解決方案中。此帖子的其余部分將解釋如何轉換到可實現機器學習解決方案,授權數據科學家的數據平臺的轉換,并分享內部工作方式。
第一步:輕量級的中央數據平臺
您可以創建該數據平臺的第一步是什么?不幸的是,沒有餅干刀模板。該方法應依賴于具體情況,包括現有的技術堆棧,可用技能和能力,流程和一般Devops以及MLOPS成熟。我可以給你通用的建議,希望有一個有用的滲透率。
一種方法是將以前版本的優勢與未來的墊腳石結合起來,更高級版本(如數據網格):
- 數據工程師專注于提取和負載,變換最小。
- 域特定(數據科學)團隊專注于高級轉換。
- 工具應提供授權團隊。
該方法是創建一個輕量級的中央數據平臺,包括以下步驟:
- 使用特定用例拍攝一個數據科學團隊。
- 設置一支團隊,包括平臺工程師和數據工程師。
- 該平臺工程師提供數據科學團隊,其中包含分析環境,包含至少存儲和處理。
- 數據工程師從源表中加載原始數據,添加基本標準化轉換,并將其提供給使用案例團隊。與平臺工程師一起,他們創造了所需的服務。
- 數據科學家與數據平臺工程師合作,在調度,運行和運行數據轉換,模型訓練循環和模型服務時,可以成為自我。他們與數據工程師合作,專業化其數據轉換。
在這種情況下,數據科學家仍然必須做很多數據播種。但是,我們接受它而不是假設不會發生,而是為他們提供最佳工作的工具。
這種方法的一個關鍵方面是從一個用例開始焦點。數據工程師,平臺工程師和數據科學家首先解決這一案例。與此同時,他們在稍后開發必要的工具方面獲得經驗。
結果如下:
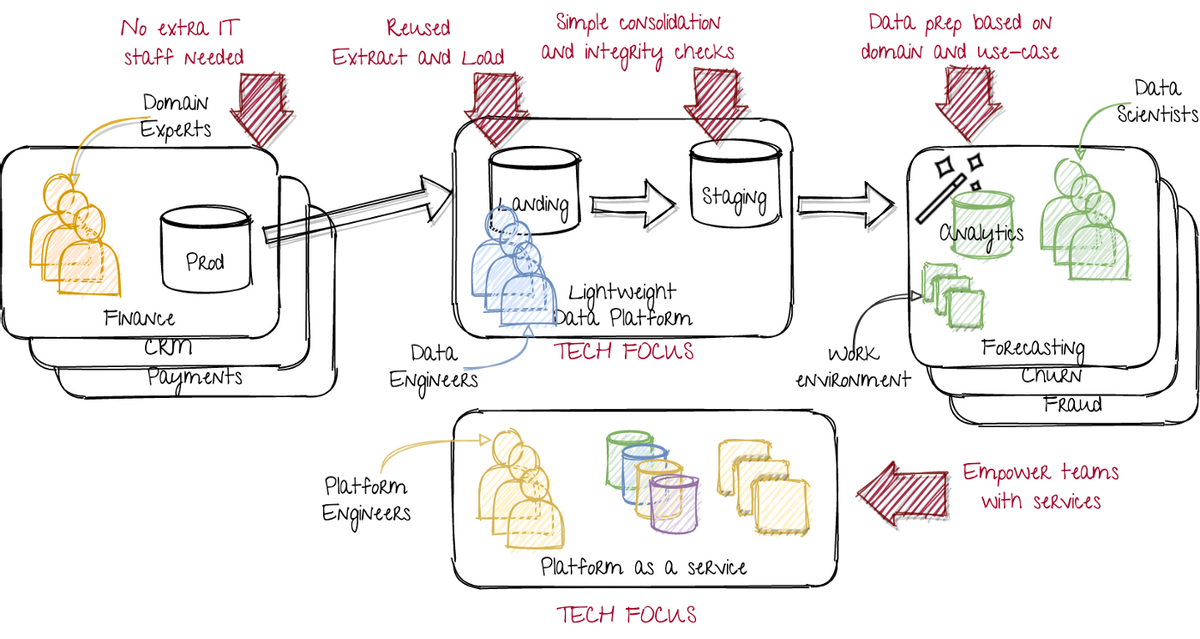
> A lightweight data platform, as a step toward the data mesh. Image by author.
在左側,我們保留了原始情況,部門或產品團隊只是開發或運營生產實例。這限制了公司廣泛的變化。
在中間,數據工程師專注于具有高質量管道的輕量級數據建模。他們主要有助于加載數據,并提供標準化的訪問方法。他們具有強大的技術焦點,包括基礎設施和服務。
在右側,數據科學團隊專注于根據所有必需的域知識創建數據產品。他們通過從客戶(使用他們的數據產品)和上游數據來源的團隊來獲得所述域知識。他們運行所有必需的分析和轉換,同時由平臺作為服務團隊支持。他們有一個強大的領域和用例焦點。
在底部,平臺作為服務團隊的工作組件創建可重用組件。因此,他們具有技術焦點。他們為具有域名焦點的數據科學團隊提供服務。作為服務團隊的平臺應由其要求推動。
下一步:跨團隊擴展和分享
下一步是擴展。可以在各種維度上完成縮放,包括獲取更多源數據集,接入更多的數據科學團隊,或者將更多的授權平臺添加為服務(思考要素存儲,型號,依此類推)。同樣,這些選擇取決于情況。
目前,讓我們參加一個典型的步驟:接入更多數據科學團隊。第一支球隊的登上隊確保了發達的服務很有用。第一個團隊是推出的客戶。作為服務團隊的平臺確保了良好的市場適合內部客戶。下一個團隊應該更快,更順利地運行。
使用多個團隊使用該服務,下一個障礙將是允許在數據科學團隊之間共享數據。這可能需要服務的一些變化和工作方式。但如果達到該里程碑,平臺倡議將真正改善所有后續團隊的生活。這導致以下情況:
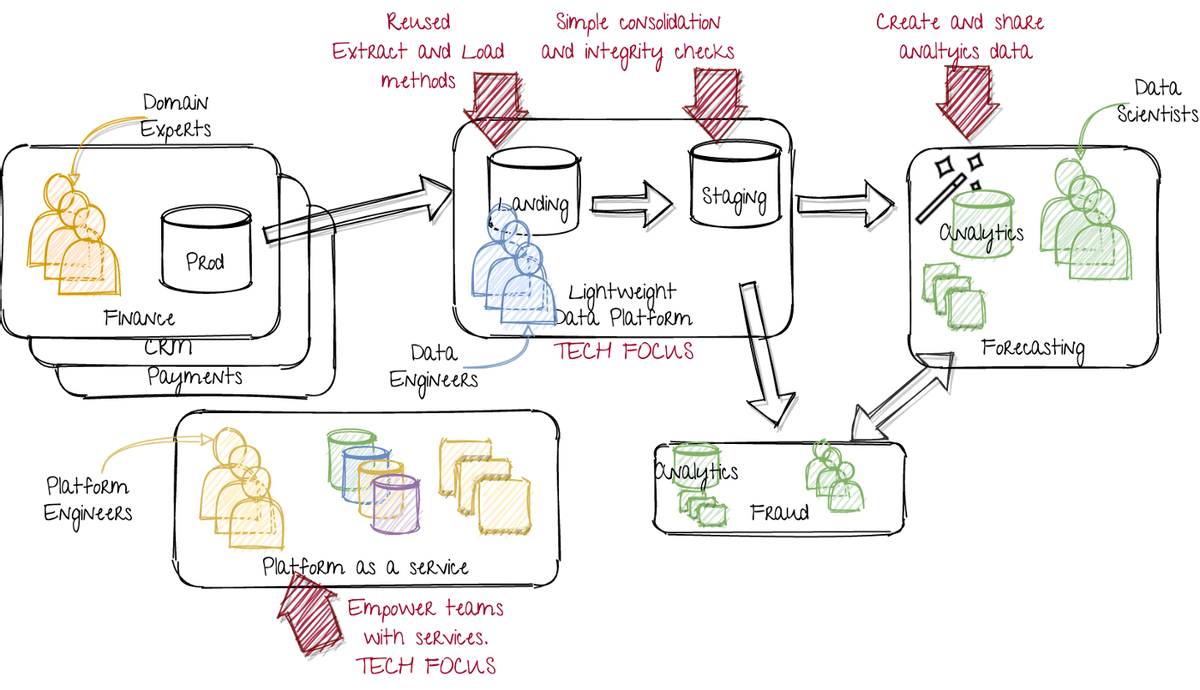
> Scaling up by on-boarding more teams
與上一個圖像相比,我們現在有一個額外的數據科學團隊,開發欺詐檢測產品。他們應該能夠從平臺工程師中重用開發的服務并從第一支預測團隊中重復使用數據。
以下步驟:專業化和縮放
不要忘記這些數據平臺舉措的目標。目標是啟用更多數據產品。因此,除了登上多個數據科學團隊,還可以努力向生產模式工作。授權第一個(少數)團隊實際嵌入他們的模型預測到業務中。
使用這些平臺,流程和工作方式,下一步不太清楚。有很多機會可以提高服務素質和團隊合作。
根據業務需求,可以提高所提供服務的質量。也許需要一個實時特征存儲,一個新的型號服務平臺,自動ml工具或更好的模型監控?
就球隊的一致性而言,可能需要一些班次。也許很多案例需要一個“客戶360視圖”,這可能導致創建一個團隊來管理該統一視圖,具有一些自動生成的功能。各種類似的常見問題可以用作創建新的常見解決方案的主動性。
總結
通過對其開發的敏捷方法,我已經顯示了一種朝著更多數據驅動組織移動的方式。該帖子希望將您的情況進行比較,而不是將任何解決方案提出“最佳方式”。
這種方法的關鍵組成部分是:
- 敏捷(內部)客戶集中的方法。
- 平臺思考。
- 刪除瓶頸,同時提供一個靈活性的平臺,并賦予數據科學團隊。
- 自由團隊,自由和自主。它們可以自由地使用適合它們的服務,并可以自主準備他們的數據。