緩存系列:緩存一致性問題的解決思路
大家好,我是李哥。
上次我們討論了在分布式系統下的緩存架構體系,從瀏覽器緩存到客戶端緩存,再到CDN緩存,再到反向代理緩存,再到本地緩存,再到分布式緩存。整個鏈路中有非常多的緩存。
在整個緩存鏈路,存在各種各樣的問題,常見的問題有緩存穿透、緩存擊穿、緩存雪崩、緩存數據一致性問題等。不常見的問題有緩存傾斜、緩存阻塞、緩存慢查詢、緩存主從一致性問題、緩存高可用、緩存故障發現與故障恢復、集群擴容收縮、大Key熱Key等等。
今天我們來聊聊緩存一致性問題,對于這個問題,不管在工作中還是面試中,都是一個非常常見的問題。
今天我們的主題是: 緩存一致性問題
老規矩,上大綱:

1、緩存一致性問題是什么
我們知道,緩存的工作原理是先從緩存中獲取數據,如果有數據則直接返回給用戶,如果沒有數據則從慢速設備上讀取實際數據并且將數據放入緩存。就像這樣:

但是,這樣的架構是存在問題的, 因為數據庫與緩存是不同的組件,操作必須有先后順序,無法像數據庫的事務一樣滿足ACID的特性,所以就會出現數據在緩存中與在數據庫中不一致的問題 。
緩存一致性問題的表現:同一份數據,緩存中的數據與數據庫中的數據不一致,那么上升到業務層面就有著千奇百怪的現象了,比如每次讀都是讀的老數據,或者每次讀是一份過時的數據等。
2、解決方案
對于寫入操作:
- 只寫DB,不寫Cache,依賴下次查詢
- 先寫DB,(同步/異步)再寫Cache
- 先寫Cache,再寫DB
對于更新操作:
- 先更新DB,再刪除Cache
- 先刪除Cache,再更新DB
- 先刪除Cache,再更新DB,再刪除Cache
2.1、只寫DB,不寫Cache,依賴下次查詢
這種是我們常見的設計方案,這種方案只寫數據庫不寫緩存,依賴下一次請求從數據庫取出數據再放入緩存。細心的讀者已經發現了,這種設計有可能引發新的問題:緩存擊穿(復習緩存擊穿:DB有數據,Cache無數據,瞬間流量將DB擊穿)。
這種可能性是存在的,但是可能性比較小,因為緩存擊穿的前提條件是大量請求透過緩存打入數據庫層,但是因為我們討論本次小標題的前提條件是新寫入,一般不會有很大的瞬間流量進來。就算有,那也不屬于本文緩存一致性問題的討論范圍了。

2.2、先寫數據庫,再寫緩存
這種也是我們常見的設計方案,先寫數據庫,再寫緩存,上面的圖也有體現這一點。

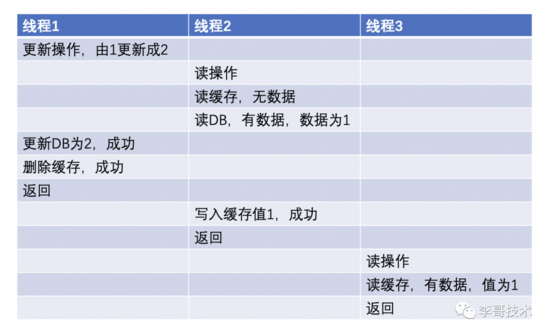
所以在這種場景下,線程1再去讀數據的時候,讀數據則優先走緩存,緩存此時值為1,所以讀到的值是1,此時線程1懵逼了啊......我剛才不是更新成2了嗎?
大家還記得之前的一篇文章《 緩存系列:緩存擊穿的解決思路 》,在面臨緩存穿透的時候,我們其中一個解決方案是:查詢數據庫如果沒有數據,則約定一個空數據格式放入緩存中,當再次查詢的時候,先查詢緩存,發現是一個空數據格式,則直接返回空,避免數據庫被瞬間流量擊垮。在這個方案下,還有第二個步驟,當數據保存后,需要主動將數據放入緩存,以便下次能夠查詢。
所以如果你的系統中如果有做緩存穿透的防護,有可能你寫完數據庫后還需要記得寫緩存。
2.3、先寫緩存,再寫數據庫
顧名思義,就是一個寫操作,先寫緩存,成功后,再寫數據庫。
那么,如果寫數據庫失敗呢?
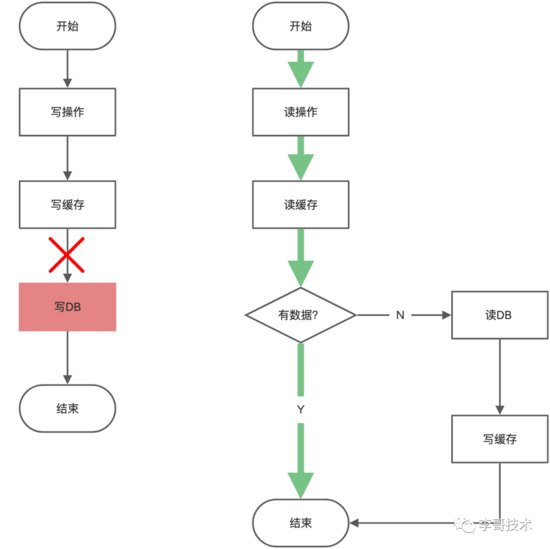
如果寫失敗了,在下次讀的時候那么就會讀取到臟數據的情況。
如果寫數據庫失敗,有兩種方案
- 刪除緩存
- 異步任務繼續寫數據庫
這兩個方案都有問題!
下面我們挨個分析。
刪除緩存。如果刪除緩存失敗呢?再用異步任務重試刪除?那你是否有考慮重試的時候這種短暫不一致的情況?還是說接受這種數據不一致的情況?系統復雜度被你提高了多少?
異步任務繼續寫數據庫。異步任務如果寫失敗呢?重試?重試也一直失敗呢?重試任務落庫+定時任務兜底?可以,那么,短暫的數據不一致是否接受?系統復雜度被你提高了多少?
所以,這種先寫緩存再寫數據庫的方案一般不會正式使用,一旦出問題,很難保證數據的最終一致性。
接下來我們討論一下更新數據的情況。
2.4、先更新數據庫,再刪除緩存
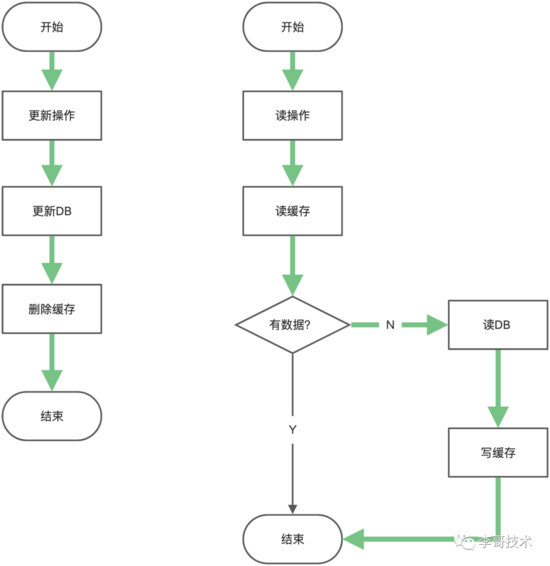
這種情況下,你可能想說這是你們現在正在使用的技術方案,但是我想說是這個方案是存在問題的,別慌反駁,大家看看這張圖:
首先,這種技術方案,確實是我們在日常開發中是最常見的,但是作為開發的我們,也應該明白它存在什么問題,以及能夠有哪些應對措施,下面談談我個人對這個解決方案的一些改進。
- 延遲刪除緩存。
- 先刪除緩存,再更新數據庫。
- 延遲雙刪策略。
- 定時任務增量/全量更新緩存數據。
- 監聽數據庫binlog增量數據更新緩存。
方案一:延遲刪除緩存。這種改進方案的優點是能有效的防止數據不一致,但不能夠完全防止。為什么說不能夠完全防止呢?因為查詢數據的那個線程有可能也延遲了一定時間才去更新緩存。這個改進方案的缺點是無法嚴格的控制時間,這個時間需要開發人員根據經驗給出,第二個缺點是延遲行為有可能讓系統引入一些新的依賴,你可能想說是否可以用jdk自帶的延遲隊列呢?可以,但是如果延遲期間,服務重啟了,怎么處理?第三個缺點是可能導致系統的復雜度提高、維護成本提高、可讀性降低。
方案二:先刪除緩存,再更新數據庫。這個方案我們下面單獨細說,這里咱不介紹。
方案三:延遲雙刪策略。這個方案我們下面單獨細說,這里咱不介紹。
方案四:定時任務增量/全量更新緩存數據。這種解題方式是最直接最暴力的,它的優點是能夠保證數據的最終一致性。它的缺點有:可能需要引入分布式調度任務(如果不引入則又存在多實例同時更新的情況,純屬浪費資源,或者加分布式鎖)、如果是增量同步的話則需要有一種方式方法區分出什么數據才是增量數據,這種方式可能有業務侵入和性能影響、如果是全量同步的話數據量太多又太耗時,嚴重的話可能導致任務阻塞以及加重數據不一致的問題。經過分析,優點很明顯,一般情況下,異步主動的對緩存數據更新是一種不可采取的方式。但是也會有一些業務場景,數據變更不太頻繁,但是訪問非常頻繁,并且更新數據更新時間已經同步更新緩存了,再使用這種異步將DB數據載入緩存作為兜底的策略是可行的。
方案五:監聽數據庫binlog增量數據更新緩存。
這種方式讓開發不再關注緩存層,專注于業務開發,只關注于數據庫,而不用關心緩存。
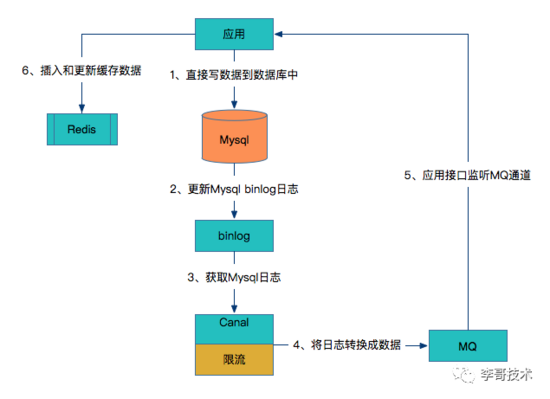
可以看到這種方案對研發人員來說比較輕量,不用關心緩存層面,而且這個方案雖然比較重,但是卻容易形成統一的解決方案。
2.5、先刪除緩存,再更新數據庫
這種方式也比較容易理解,先刪除緩存數據,再更新DB的數據,如果刪除緩存失敗了,直接返回失敗;如果更新DB失敗了,影響的也只是刪除緩存而已,下次查詢的時候重新種一次即可。
那如果,會不會因為刪除了緩存的數據,從而導致DB被擊穿呢?這種可能性是存在的,但是可能性比較小。
再說了,這種方案真的可以解決問題嗎?如果在刪除緩存后,馬上有新線程查詢緩存,新線程發現緩存不存在(剛被刪),新線程查詢數據庫后將數據放于緩存,老線程刪除數據庫成功。此時數據庫無數據,緩存有數據。
2.6、先刪除緩存,再更新數據庫,再刪除緩存
基于2.5,在這個基礎上可以做出一些改進,那就是延遲雙刪。
延遲雙刪的流程:刪除緩存->刪除DB->延遲一段時間再刪除緩存。
延遲雙刪能解決大部分的問題,但是在極端情況下,還是會出現問題,造成數據不一致。
這里存在一個問題,延遲一段時間,是延遲多久?1s?3s?這是一個經驗值,一般情況是1s~2s。具體取值根據監控實際情況而定。那既然是估計值,那么就一定存在誤差,所以必然極端情況下的數據不一致問題。
解決這個問題的方法之前也說了,監聽數據庫binlog增量數據更新緩存,或者還可以使用異步消息等。
3、總結
在實際的工作中,或者在面試中,如果有人問你各種沒有場景化的純粹的技術問題,比如說有人看了上面的種種方案還是會提出疑問,你的這些方案仍然存在數據不一致的問題啊,那怎么解決呢?
技術是為了業務服務的,所以,在所有不同的業務場景下,對于技術的選擇,和方案的設計都是不同的。我們需要反問他,具體的業務場景是什么?我們需要根據具體的業務場景來選擇最合適的技術方案。
我們要明確的是:一個技術方案不可能cover住所有的場景,脫離業務的技術都是刷流氓。