













一文讀懂 Linux 內存分配全過程
本文轉載自微信公眾號「Linux內核那些事」,作者songsong001。轉載本文請聯系Linux內核那些事公眾號。
在《你真的理解內存分配》一文中,我們介紹了 malloc 申請內存的原理,但其在內核怎么實現的呢?所以,本文主要分析在 Linux 內核中對堆內存分配的實現過程。
本文使用 Linux 2.6.32 版本代碼
內存分區對象
在《你真的理解內存分配》一文中介紹過,Linux 會把進程虛擬內存空間劃分為多個分區,在 Linux 內核中使用 vm_area_struct 對象來表示,其定義如下:
- struct vm_area_struct {
- struct mm_struct *vm_mm; // 分區所屬的內存管理對象
- unsigned long vm_start; // 分區的開始地址
- unsigned long vm_end; // 分區的結束地址
- struct vm_area_struct *vm_next; // 通過這個指針把進程所有的內存分區連接成一個鏈表
- ...
- struct rb_node vm_rb; // 紅黑樹的節點, 用于保存到內存分區紅黑樹中
- ...
- };
我們對 vm_area_struct 對象進行了簡化,只保留了本文需要的字段。
內核就是使用 vm_area_struct 對象來記錄一個內存分區(如 代碼段、數據段 和 堆空間 等),下面介紹一下 vm_area_struct 對象各個字段的作用:
- vm_mm:指定了當前內存分區所屬的內存管理對象。
- vm_start:內存分區的開始地址。
- vm_end:內存分區的結束地址。
- vm_next:通過這個指針把進程中所有的內存分區連接成一個鏈表。
- vm_rb:另外,為了快速查找內存分區,內核還把進程的所有內存分區保存到一棵紅黑樹中。vm_rb 就是紅黑樹的節點,用于把內存分區保存到紅黑樹中。
假如進程 A 現在有 4 個內存分區,它們的范圍如下:
- 代碼段:00400000 ~ 00401000
- 數據段:00600000 ~ 00601000
- 堆空間:00983000 ~ 009a4000
- 棧空間:7f37ce866000 ~ 7f3fce867000
那么這 4 個內存分區在內核中的結構如 圖1 所示:
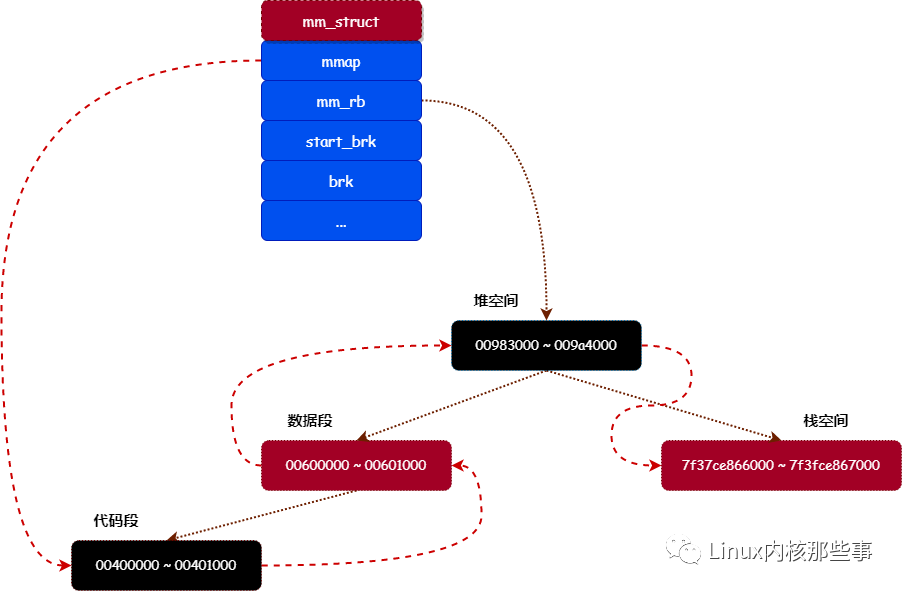
在 圖1 中,我們可以看到有個 mm_struct 的對象,此對象每個進程都持有一個,是進程虛擬內存空間和物理內存空間的管理對象。我們簡單介紹一下這個對象,其定義如下:
- struct mm_struct {
- struct vm_area_struct *mmap; // 指向由進程內存分區連接成的鏈表
- struct rb_root mm_rb; // 內核使用紅黑樹保存進程的所有內存分區, 這個是紅黑樹的根節點
- unsigned long start_brk, brk; // 堆空間的開始地址和結束地址
- ...
- };
我們來介紹下 mm_struct 對象各個字段的作用:
- mmap:指向由進程所有內存分區連接成的鏈表。
- mm_rb:內核為了加快查找內存分區的速度,使用了紅黑樹保存所有內存分區,這個就是紅黑樹的根節點。
- start_brk:堆空間的開始內存地址。
- brk:堆空間的頂部內存地址。
我們來回顧一下進程虛擬內存空間的布局圖,如 圖2 所示:
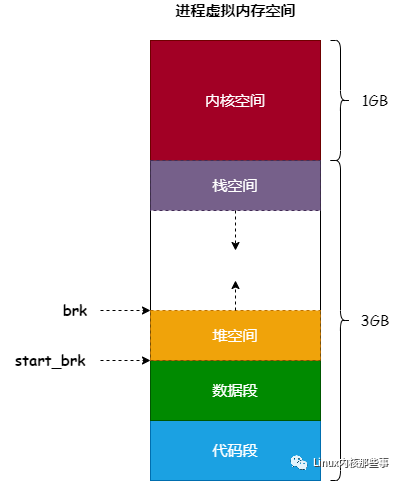
start_brk 和 brk 字段用來記錄堆空間的范圍, 如 圖2 所示。一般來說,start_brk 是不會變的,而 brk 會隨著分配內存和釋放內存而變化。
虛擬內存分配
在《你真的理解內存分配》一文中說過,調用 malloc 申請內存時,最終會調用 brk 系統調用來從堆空間中分配內存。我們來分析一下 brk 系統調用的實現:
- unsigned long sys_brk(unsigned long brk)
- {
- unsigned long rlim, retval;
- unsigned long newbrk, oldbrk;
- struct mm_struct *mm = current->mm;
- ...
- down_write(&mm->mmap_sem); // 對內存管理對象進行上鎖
- ...
- // 判斷堆空間的大小是否超出限制, 如果超出限制, 就不進行處理
- rlim = current->signal->rlim[RLIMIT_DATA].rlim_cur;
- if (rlim < RLIM_INFINITY
- && (brk - mm->start_brk) + (mm->end_data - mm->start_data) > rlim)
- goto out;
- newbrk = PAGE_ALIGN(brk); // 新的brk值
- oldbrk = PAGE_ALIGN(mm->brk); // 舊的brk值
- if (oldbrk == newbrk) // 如果新舊的位置都一樣, 就不需要進行處理
- goto set_brk;
- ...
- // 調用 do_brk 函數進行下一步處理
- if (do_brk(oldbrk, newbrk-oldbrk) != oldbrk)
- goto out;
- set_brk:
- mm->brk = brk; // 設置堆空間的頂部位置(brk指針)
- out:
- retval = mm->brk;
- up_write(&mm->mmap_sem);
- return retval;
- }
總結上面的代碼,主要有以下幾個步驟:
1、判斷堆空間的大小是否超出限制,如果超出限制,就不作任何處理,直接返回舊的 brk 值。
2、如果新的 brk 值跟舊的 brk 值一致,那么也不用作任何處理。
3、如果新的 brk 值發生變化,那么就調用 do_brk 函數進行下一步處理。
4、設置進程的 brk 指針(堆空間頂部)為新的 brk 的值。
我們看到第 3 步調用了 do_brk 函數來處理,do_brk 函數的實現有點小復雜,所以這里介紹一下大概處理流程:
- 通過堆空間的起始地址 start_brk 從進程內存分區紅黑樹中找到其對應的內存分區對象(也就是 vm_area_struct)。
- 把堆空間的內存分區對象的 vm_end 字段設置為新的 brk 值。
至此,brk 系統調用的工作就完成了(上面沒有分析釋放內存的情況),總結來說,brk 系統調用的工作主要有兩部分:
把進程的 brk 指針設置為新的 brk 值。
把堆空間的內存分區對象的 vm_end 字段設置為新的 brk 值。
物理內存分配
從上面的分析知道,brk 系統調用申請的是 虛擬內存,但存儲數據只能使用 物理內存。所以,虛擬內存必須映射到物理內存才能被使用。
那么什么時候才進行內存映射呢?
在《你真的理解內存分配》一文中介紹過,當對沒有映射的虛擬內存地址進行讀寫操作時,CPU 將會觸發 缺頁異常。內核接收到 缺頁異常 后, 會調用 do_page_fault 函數進行修復。
我們來分析一下 do_page_fault 函數的實現(精簡后):
- void do_page_fault(struct pt_regs *regs, unsigned long error_code)
- {
- struct vm_area_struct *vma;
- struct task_struct *tsk;
- unsigned long address;
- struct mm_struct *mm;
- int write;
- int fault;
- tsk = current;
- mm = tsk->mm;
- address = read_cr2(); // 獲取導致頁缺失異常的虛擬內存地址
- ...
- vma = find_vma(mm, address); // 通過虛擬內存地址從進程內存分區中查找對應的內存分區對象
- ...
- if (likely(vma->vm_start <= address)) // 如果找到內存分區對象
- goto good_area;
- ...
- good_area:
- write = error_code & PF_WRITE;
- ...
- // 調用 handle_mm_fault 函數對虛擬內存地址進行映射操作
- fault = handle_mm_fault(mm, vma, address, write ? FAULT_FLAG_WRITE : 0);
- ...
- }
do_page_fault 函數主要完成以下操作:
獲取導致頁缺失異常的虛擬內存地址,保存到 address 變量中。
調用 find_vma 函數從進程內存分區中查找異常的虛擬內存地址對應的內存分區對象。
如果找到內存分區對象,那么調用 handle_mm_fault 函數對虛擬內存地址進行映射操作。
從上面的分析可知,對虛擬內存進行映射操作是通過 handle_mm_fault 函數完成的,而 handle_mm_fault 函數的主要工作就是完成對進程 頁表 的填充。
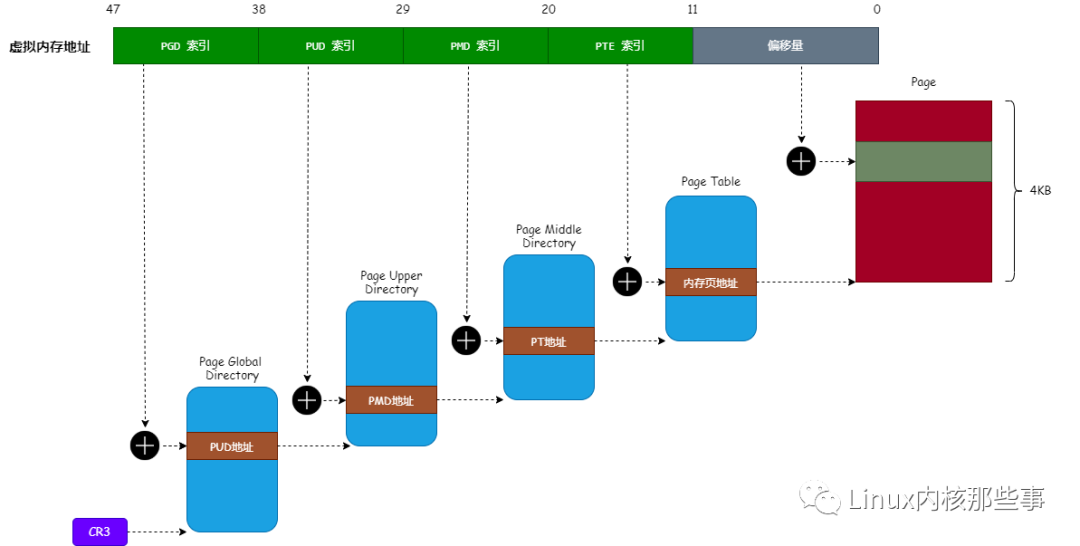
我們通過 圖3 來理解內存映射的原理,可以參考文章《一文讀懂 HugePages的原理》:
下面我們來分析一下 handle_mm_fault 的實現,代碼如下:
- int handle_mm_fault(struct mm_struct *mm, struct vm_area_struct *vma,
- unsigned long address, unsigned int flags)
- {
- pgd_t *pgd; // 頁全局目錄項
- pud_t *pud; // 頁上級目錄項
- pmd_t *pmd; // 頁中間目錄項
- pte_t *pte; // 頁表項
- ...
- pgd = pgd_offset(mm, address); // 獲取虛擬內存地址對應的頁全局目錄項
- pud = pud_alloc(mm, pgd, address); // 獲取虛擬內存地址對應的頁上級目錄項
- ...
- pmd = pmd_alloc(mm, pud, address); // 獲取虛擬內存地址對應的頁中間目錄項
- ...
- pte = pte_alloc_map(mm, pmd, address); // 獲取虛擬內存地址對應的頁表項
- ...
- // 對頁表項進行映射
- return handle_pte_fault(mm, vma, address, pte, pmd, flags);
- 18}
handle_mm_fault 函數主要對每一級的頁表進行映射(對照 圖3 就容易理解),最終調用 handle_pte_fault 函數對 頁表項 進行映射。
我們繼續來分析 handle_pte_fault 函數的實現,代碼如下:
- static inline int
- handle_pte_fault(struct mm_struct *mm, struct vm_area_struct *vma,
- unsigned long address, pte_t *pte, pmd_t *pmd,
- unsigned int flags)
- {
- pte_t entry;
- entry = *pte;
- if (!pte_present(entry)) { // 還沒有映射到物理內存
- if (pte_none(entry)) {
- ...
- // 調用 do_anonymous_page 函數進行匿名頁映射(堆空間就是使用匿名頁)
- return do_anonymous_page(mm, vma, address, pte, pmd, flags);
- }
- ...
- }
- ...
- }
上面代碼簡化了很多與本文無關的邏輯。從上面代碼可以看出,handle_pte_fault 函數最終會調用 do_anonymous_page 來完成內存映射操作,我們接著來分析下 do_anonymous_page 函數的實現:
- static int
- do_anonymous_page(struct mm_struct *mm, struct vm_area_struct *vma,
- unsigned long address, pte_t *page_table, pmd_t *pmd,
- unsigned int flags)
- {
- struct page *page;
- spinlock_t *ptl;
- pte_t entry;
- if (!(flags & FAULT_FLAG_WRITE)) { // 如果是讀操作導致的異常
- // 使用 `零頁` 進行映射
- entry = pte_mkspecial(pfn_pte(my_zero_pfn(address), vma->vm_page_prot));
- ...
- goto setpte;
- }
- ...
- // 如果是寫操作導致的異常
- // 申請一塊新的物理內存頁
- page = alloc_zeroed_user_highpage_movable(vma, address);
- ...
- // 根據物理內存頁的地址生成映射關系
- entry = mk_pte(page, vma->vm_page_prot);
- if (vma->vm_flags & VM_WRITE)
- entry = pte_mkwrite(pte_mkdirty(entry));
- ...
- setpte:
- set_pte_at(mm, address, page_table, entry); // 設置頁表項為新的映射關系
- ...
- return 0;
- }
do_anonymous_page 函數的實現比較有趣,它會根據 缺頁異常 是由讀操作還是寫操作導致的,分為兩個不同的處理邏輯,如下:
如果是讀操作導致的,那么將會使用 零頁 進行映射(零頁 是 Linux 內核中一個比較特殊的內存頁,所有讀操作引起的 缺頁異常 都會指向此頁,從而可以減少物理內存的消耗),并且設置其為只讀(因為 零頁 是不能進行寫操作)。如果下次對此頁進行寫操作,將會觸發寫操作的 缺頁異常,從而進入下面步驟。
如果是寫操作導致的,就申請一塊新的物理內存頁,然后根據物理內存頁的地址生成映射關系,再對頁表項進行填充(映射)。
總結
本文主要介紹了 Linux 內存分配的整個過程,當然只是介紹從堆空間分配的內存的過程。Linux 分配內存的方式還有很多,比如 mmap、HugePages 等,有興趣的可以查閱相關的資料和書籍。





















