你需要了解的六種神經網絡
譯文【51CTO.com快譯】神經網絡如今在人工智能領域中已經變得非常流行,但是很多人對它們仍然缺乏了解。首先,很多人識別不清各種類型的神經網絡及其解決的問題,更不用說如何對它們進行區分了。其次,在某種程度上甚至更糟的是,人們在談論神經網絡時通常不加區分地使用“深度學習”這一術語。
以下將討論目前一些行業主流的神經網絡架構,而人工智能行業人士應該對這些架構都非常熟悉:
1.前饋神經網絡
這是一種最基本的神經網絡類型,得益于技術的進步和發展,開發人員可以添加更多的隱藏層,而不必太擔心其計算時間過長。而在深度學習技術的“教父”Geoff Hinton在1990年推出了反向傳播算法之后,前饋神經網絡開始得到廣泛應用。
這種類型的神經網絡基本上由一個輸入層、多個隱藏層和一個輸出層組成。其運行沒有循環,信息只能向前流動。前饋神經網絡通常適用于數值數據的監督學習,但也存在一些缺點:
- 不能與順序數據一起使用;
- 不能很好地處理圖像數據,因為其模型的性能嚴重依賴于特征,而人工查找圖像或文本數據的特征本身是一項相當困難的工作。
于是行業廠商又相繼開發了卷積神經網絡和遞歸神經網絡。
2.卷積神經網絡(CNN)
在卷積神經網絡(CNN)普及之前,人們采用很多算法對圖像分類。人們過去常常根據圖像創建特征,然后將這些特征輸入到諸如支持向量機(SVM)之類的分類算法中。一些算法也將圖像的像素水平值作為特征向量。例如,用戶可以訓練具有784個特征的支持向量機(SVM),其中每個特征都是28×28的圖像像素值。
那么,為什么要使用卷積神經網絡(CNN),為什么其效果要好得多?因為可以將卷積神經網絡(CNN)視為圖像的自動特征提取器。如果用戶使用帶有像素矢量的算法,則會丟失很多像素之間的空間交互關系,而卷積神經網絡(CNN)會有效地使用相鄰像素信息,首先通過卷積有效地對圖像進行下采樣,然后在最后使用預測層。
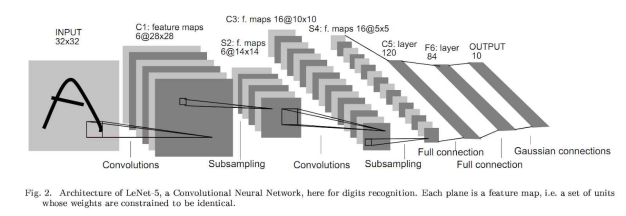
人工智能科學家Yann le cun在1998年首次提出了用于數字分類的這一概念,他使用一個卷積層來預測數字。后來在2012年被Alexnet推廣,它使用多個卷積層在Imagenet上實現了更先進的預測。因此,從而使其成為圖像分類的首選算法。
隨著時間的推移,神經網絡這個特定領域取得了各種進展,研究人員為卷積神經網絡(CNN)開發了各種架構,例如VGG、Resnet、Inception、Xception等,這些架構不斷地推動了圖像分類的發展。
相比之下,卷積神經網絡(CNN)也用于對象檢測,這可能是一個問題,因為除了對圖像進行分類之外,人們還希望檢測圖像中各個對象周圍的邊界框。在過去,研究人員采用許多架構(例如YOLO、RetinaNet、Faster RCNN等)以解決目標檢測問題,所有這些架構都使用卷積神經網絡(CNN)作為其架構的一部分。
3.遞歸神經網絡(LSTM/GRU /注意力)
卷積神經網絡(CNN)主要針對圖像的含義進行分類,遞歸神經網絡(RNN)主要針對文本的含義分類。遞歸神經網絡(RNN)可以幫助人們學習文本的順序結構,其中每個單詞都取決于前一個單詞或前一個句子中的一個單詞。
為了簡單地解釋遞歸神經網絡(RNN),可以將其中看作一個黑盒,將一個隱藏狀態(一個向量)和一個單詞向量作為輸入,并輸出一個輸出向量和下一個隱藏狀態。這個黑盒具有一些權重,需要使用損耗的反向傳播進行調整。同樣,將相同的單元格應用于所有單詞,以便在句子中的單詞之間共享權重。這種現象稱為權重共享。

以下是同一個遞歸神經網絡(RNN)單元的擴展版本,其中每個遞歸神經網絡(RNN)單元在每個單詞“令牌”上運行(令牌是服務端生成的一串字符串,作為客戶端進行請求的一個標識),并將隱藏狀態傳遞給下一個單元。對于長度為4的序列(例如“the quick brown fox”), 遞歸神經網絡(RNN)單元最終給出4個輸出向量,可以將它們連接起來,然后用作密集前饋神經架構的一部分,如下圖所示,以解決最終任務語言建模或分類任務:
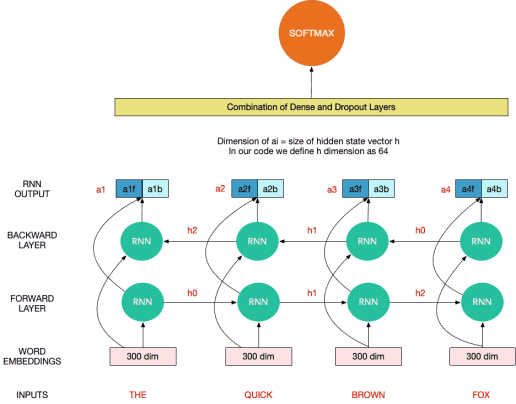
長短期記憶網絡(LSTM)和門控制循環單元(GRU)是遞歸神經網絡(RNN)的子類,它們通過引入不同的門來增加時間記憶信息(也稱為消失梯度問題),這些門通過添加或刪除信息來調節神經元狀態。
從更高的層面來看,可以將LSTM/GRU理解為遞歸神經網絡(RNN)單元的一種用法,以了解長期依賴性。RNN/LSTM/GRU主要用于各種語言建模任務,這些任務的目標是在給定輸入單詞流的情況下預測下一個單詞,或用于具有順序模式的任務。
接下來要提到的是基于關注的模型,但是在這里只討論直覺。在過去,傳統的文本特征提取方法如TFIDF/CountVectorizer等都是通過提取關鍵字來實現的。有些詞語比其他詞語更有助于確定文本的類別。然而,在這種方法中,有點失去了文本的順序結構。使用LSTM和深度學習方法,可以處理序列結構,但是失去了賦予更重要的詞語更高權重的能力。
那么能兩全其美嗎?答案是肯定的。事實上,關注就是用戶所需要的。正好專家所說:“并不是所有的詞語都能平等地表達句子的意思。因此,我們引入一種關注機制來提取對句子含義更重要的詞語,并匯總這些信息性單詞表達的含義形成句子向量。”
4. Transformers
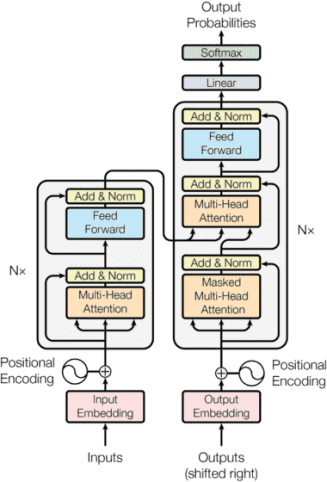
Transformers已經成為實施任何一個自然語言處理(NLP)任務的實際標準,最近推出的GPT-3 Transformers是迄今為止規模最大的一個神經網絡。
在過去,LSTM和GRU架構以及關注機制曾經是解決語言建模問題和翻譯系統的最先進方法。這些架構的主要問題是它們本質上是遞歸的,并且運行時間隨著序列長度的增加而增加。也就是說,這些架構采用一個句子并以順序的方式處理每個單詞,因此當句子長度增加時,其整體運行時間也會增加。
Transformer是基于關注模型的架構。Transformer完全依賴于一種關注機制來繪制輸入和輸出之間的全局依賴關系。這使得它可以更快、更準確地成為解決自然語言處理(NLP)領域中各種問題的首選架構。
5.生成對抗網絡(GAN)
近年來,在數據科學領域中看到了一些人工智能系統偽造的人臉圖像,無論是在論文、博客還是視頻中。現在已經到了一個難以區分實際的人臉和由人工智能生成的人臉的階段。而所有這些圖像都是通過生成對抗網絡(GAN)實現的。生成對抗網絡(GAN)很有可能改變人們制作視頻游戲和特效的方式。使用這種方法,可以按需創建逼真的紋理或角色,從而帶來了無限的可能性。
生成對抗網絡(GAN)通常使用兩個對抗神經網絡來訓練計算機,以充分了解數據集的性質,并生成足以亂真的偽造圖像。其中一個神經網絡生成偽造圖像(生成器),另一個嘗試對哪些偽造圖像進行分類(鑒別器)。通過相互對抗和競爭,這兩個神經網絡的功能和性能會隨著時間的推移而不斷改進。
人們可以將“生成器”想象成小偷,將“鑒別器”想象成警察。小偷偷竊的次數越多,其手段越高明。與此同時在這一過程中,警察也越來越善于抓小偷。
這兩個神經網絡中的損失主要取決于另一個網絡的性能:
- 鑒別器的網絡損失是生成器網絡質量的函數:如果鑒別器被生成器的虛假圖像所欺騙,則損失率很高。
- 生成器的網絡損失是鑒別器網絡質量的函數:如果生成器無法欺騙鑒別器,則損失率很高。
在訓練階段,將依次訓練鑒別器神經網絡和發生器神經網絡,以期提高這兩者的性能。其最終目標是獲得權重,以幫助生成器創建逼真的圖像。使用者可以將使用生成器神經網絡從隨機噪聲生成高質量的偽造圖像。
6.自編碼器
自編碼器是一種深度學習函數,可以近似表示從X到X的映射,即輸入=輸出。它們首先將輸入要素壓縮為低維表示形式,然后從該表示形式重構輸出。
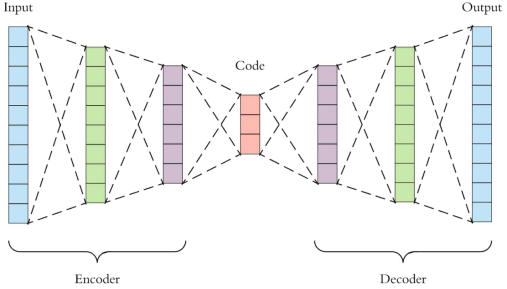
在很多情況下,這種表示向量可以作為模型特征,因此可以用于降維。
自編碼器也用于異常檢測,在這種情況下,可以嘗試使用自編碼器來重建示例,如果重建損失率過高,則可以預測該示例是異常的。
結論
神經網絡本質上是有史以來最偉大的模型之一,它們可以很好地概括人們所能想到的大多數建模用例。如今,這些不同種類和版本的神經網絡正被用于解決醫療、金融和汽車行業等領域面臨的各種重要問題,同時也被蘋果、谷歌和Facebook這樣的科技公司用來提供推薦和幫助搜索查詢。例如,谷歌公司使用BERT(一種基于Transformers的模型)為其搜索查詢提供幫助。
原文標題:Types of Neural Networks You Need To Know About,作者:Kevin Vu
【51CTO譯稿,合作站點轉載請注明原文譯者和出處為51CTO.com】