













人工干預如何提高模型性能?看這文就夠了
有一些行業對誤報非常敏感,如金融行業,在對信用卡欺詐檢測時,如果檢測系統將用戶的行為錯誤地分類為欺詐,這將對該金融機構的聲譽產生負面影響。又如在醫學領域對癌癥診斷時,對假陽性反應是很敏感的。另外,在使用 GPT-3 等模型時,自動和客戶聊天的機器人,其回復的文本不應該包含一些不合時宜的語言。
下面我先從使用機器學習模型來推理系統入手,再展開人工干預的推理循環的技術介紹。
基于模型的推理
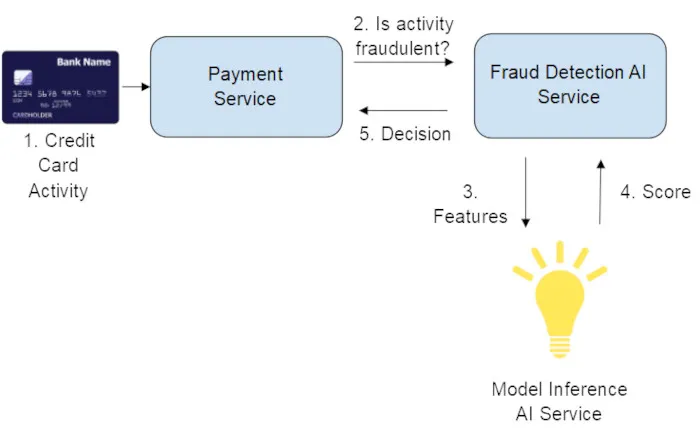
圖1. 經典模型推斷系統
上述為典型的信用卡欺詐用例機器學習模型,是系統和事件序列的簡化視圖,僅由模型負責決定給定活動是否為欺詐行為。
如何選擇閾值?
閾值的大小是根據精度和召回率的要求來選擇[5]。在圖1的示例中,精確度定義為正確預測的欺詐活動數(真陽性樣本數)除以預測為欺詐的活動總數(真陽性樣本數+假陽性樣本數)。召回率定義為正確預測的欺詐活動的數量(真陽性樣本數)除以正確預測為欺詐的活動數量的總和,以及預測為不欺詐的實際欺詐活動的數量(真陽性樣本數+假陰性樣本數)。
為實現系統目標,我們需要在精度和召回率之間進行權衡。圖2展示的精確率-召回率(PR)曲線是一個有效工具。
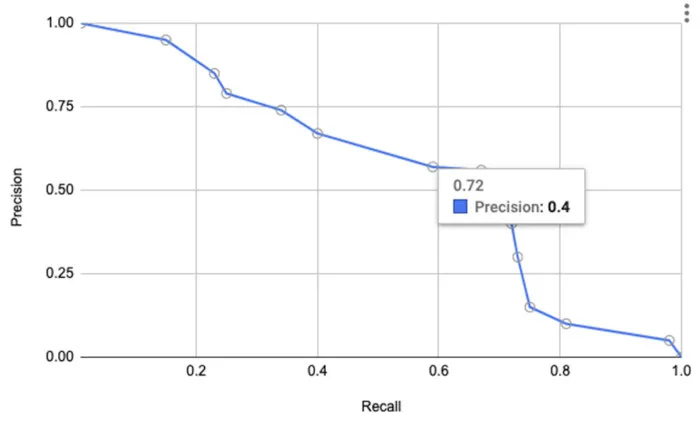
圖2.精確率-召回率(PR)曲線
在較高召回率下,精度是如何降低的?當召回率為 0.72 時,精度逐漸降低到約為 0.4。為了捕獲 70% 的欺詐案件,可能產生大量假陽性樣本,精確率達 40%。對于這種情況,假陽性的數量是不可接受的。在合理的召回量下需要實現更高的精度,因此從圖1開始,我們需要大于0.99的精度率。
盡管我們選擇了更高的精度進行權衡,但在 0.99 的精度率下,召回率為 0.15,遠遠不夠的。下面我們討論下如何利用人工干預下,以更高的召回率實現更高的精度。
人工干預
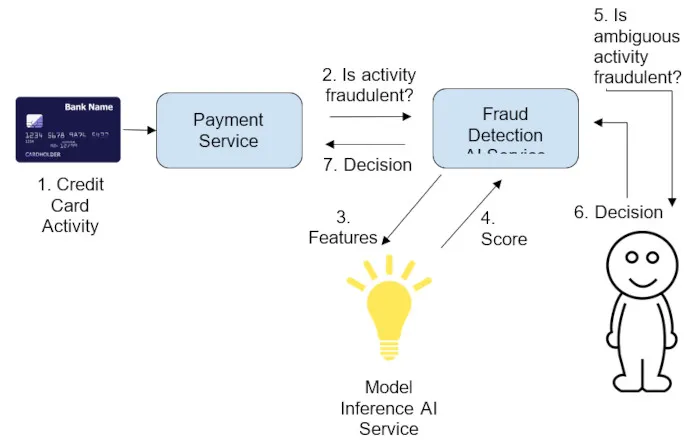
圖3.通過人機交互來提高模型性能
增加召回率的一種方法是在推理循環中人工干預。如此一來,模型置信度較低的運算結果子集將被發送給人工代理進行手動檢查。當選擇確定有資格作為不明確的預測子集閾值時,該考慮將多少樣本交給人工代理,畢竟人力資源成本往往更貴。所以為了幫助選擇閾值,可以下圖:
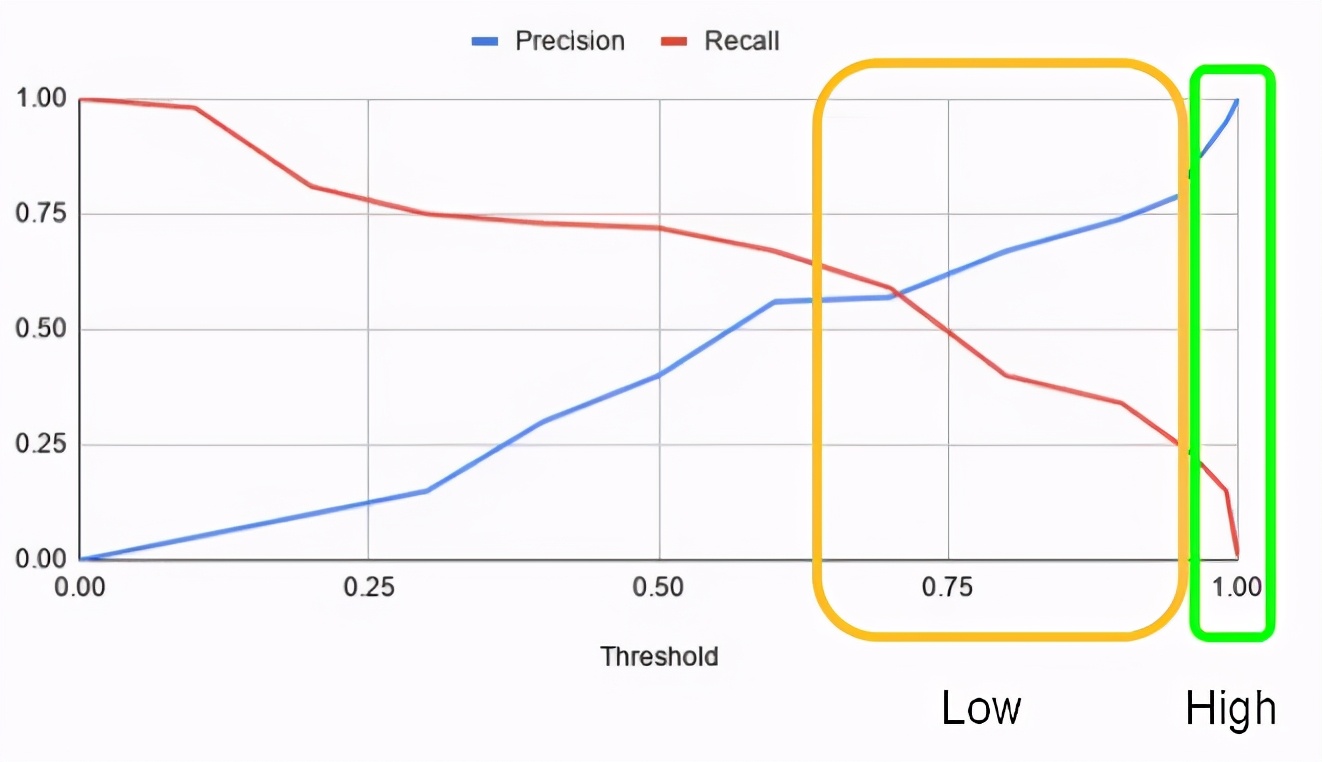
圖4.精確召回閾值曲線
在上述案例里,假設分數接近 1.0 表示正標簽(欺詐),分數接近0.0表示負標簽(非欺詐)。圖4中顯示了兩個區域:
- 綠色區域表示正樣本標簽的高置信度區域,即允許進行模型自行決策,并且所得到的模型精度是可以接受的(受影響的終端用戶通常可以容忍較低的假陽率)。
- 黃色區域表示正樣本標簽的置信度低的區域,在該區域中,模型自動決策的精度水平是不可接受的(假陽率很高會對業務產生重大負面影響)
黃色區域是人工干預通過手動檢查提高精度的區域范圍。可以使用相同的方法處理負樣本標簽:接近0.0的區域是高置信度區域。黃色區域中的所有項目或項目子集可進行手動檢查。在人工檢查過程中,人工代理決定該樣本識別的最終結果。關鍵假設是,在對歧義案件做出決策時,人為因素要優于機器學習模型。
但由于人力資源稀缺,因此在選擇閾值時,發送給人工代理的請求量是重要的考慮因素。圖5展示的是針對閾值繪制的數量和召回率的示例。“數量”的定義為每小時將發送給人工代理進行檢查的項目數。從圖5可以看出,閾值為0.7的數量為16,000個項目(每小時)。
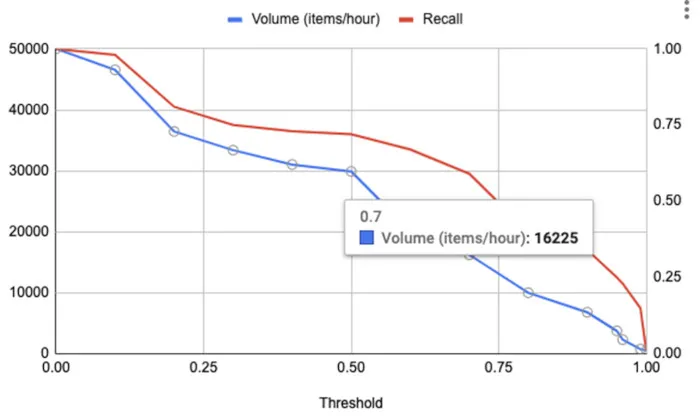
圖5.容量圖(每小時請求數量)和針對閾值的調用
圖4和圖5中的兩個曲線圖都可用來滿足可接受的人工復查量,選擇合適的閾值來滿足期望召回率。讓我們快速練習下,在召回率為0.59(閾值0.7)時,復查量(請參見圖5)約為每小時16K個項目。在相同的召回率水平下,模型精度約為0.6(見圖4)。假設人員代理池的容納量為每小時16K件商品,并且還假設人員代理的準確性和召回率是95%,經過人工審查后,召回水平為0.59時所得到的精度將介于0.95和0.99之間。使用這設定,我們能將召回率從0.15提高到0.56(0.59 [模型] * 0.95 [人]),同時保持大于0.95的精確度。
使用人工干預的最佳做法
為了獲得高質量的人工檢查,為人工代理建立明確定義的培訓是很重要的,人工代理將負責人工檢查項目。培訓計劃和定期反饋循環將有助于長期保持人工檢查項目的高質量,有助于最大程度地減少人為錯誤,維持每個項目決策的SLA要求。
另一種開銷稍微大的策略是安排三個人工代理對同一項目進行審查,并從這三個代理的決策結果中進行多數表決來確定最終結果。
在微服務的實踐也適用上述方法,這包括對以下內容的適當監視:
- 從系統中收到商品到對商品做出決定的時間
- 代理池的整體運行狀況
- 發送給人工審查的項目數量
- 每小時的項目分類統計
由于各種原因模型精度和召回率可能會隨時間變化。重要的是要通過跟蹤精確/召回率來重新訪問選定的閾值。
剛才我們回顧了涉及人工干預的機器學習推理系統如何在保持較高精確度的同時,幫助提高召回率。這種方法在對假陽性敏感的業務場景案例中特別有用。精確率-召回率閾值曲線是選擇人工審查和自動模型決策的閾值的好工具。但是涉及人工代理會導致開發成本增加,并可能導致增加正在經歷快速增長的系統的瓶頸區域。我們需要各方面評估和權衡。





















