Epoch不僅過時,而且有害?Reddit機器學習板塊展開討論
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
有一天,一個調參俠在訓練一個深度學習模型,要用到的兩個數據集損失函數不同,數據集的大小還不是固定的,每天都在增加。
他有點發愁,這該怎么設置Epoch數呢?
在糾結的過程中,他突然想到:干嘛非得定一個Epoch數?只要對每個Batch進行獨立同分布抽樣 (IID Sampling)不就得了。
為了驗證這個想法,調參俠去看了很多論文。發現越來越多的人介紹他們的訓練方法時,只說進行了多少個Iteration,而拋棄了Epoch。
他想到,Epoch暗示并強調了數據集是有限的,這不僅麻煩,還有潛在的“危害”。把Epoch去掉,讓循環嵌套的層數少一層總是好的。
于是他在Reddit發起了討論:Epoch是不是過時了,甚至還有危害?

Epoch多余嗎?
有人對這個觀點表示贊同:
挺有道理,當數據集大小有很大差距,Batch大小相同時,設置一樣的Epoch數,豈不是大數據集參數更新的次數多,小數據集參數更新次數少了,這似乎不對勁。
Epoch最大的好處是確保每個樣本被定期使用。當使用IID抽樣時,你只要能想辦法確保所有樣本被同樣頻繁地使用就好了。
但調參俠覺得讓每個樣本被定期使用就是他懷疑的點,IID抽樣已經確保分布相同了,再讓他們同頻率被使用就是一種誤導。

反對者認為:
不能因為你覺得車沒開在路的正中間就放開方向盤不管了,雖然大撒把不會改變你正好在路中間的概率,但它增加了方差。

調參俠最后總結道,這個爭議有點像統計學里的“頻率派 VS 貝葉斯派”,即認為數據集到底應該是確定的還是不確定的。
該怎么比較模型?
調參俠還注意到,有人用Batch Loss做損失曲線。他認為這比Epoch Loss更有參考價值。
反對者覺得,你這個方式是挺好的,但Epoch依然有用。
因為即使在相同的硬件上,不同模型的算法效率不同也會帶來巨大差異。
像各種Transformer和CNN這種底層代碼實現都差不多,但是別的模型就可能有很不一樣。比如我們自己的CUDA LSTM實現,至少和CudnnLSTM一樣快,比原版TensorFlow實現快4倍左右。
最后,有個網友以CV模型為例對這個話題做出精彩總結,列了4種損失可視化方式,并介紹了什么情況該用哪個。
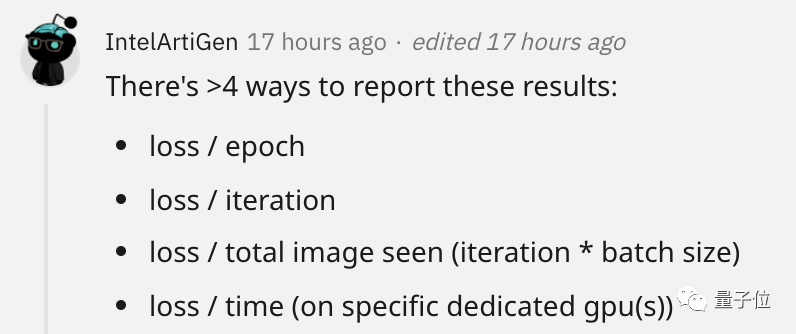
Loss/Epoch告訴你一個模型要觀察同一個圖像多少次才能理解它。
Loss/Iteration告訴你需要多少次參數更新。當比較優化器時這很有用,可以幫助你加快訓練速度或達到更高的精度。
Loss/Total Image Seen告訴你算法看到了多少圖像時的損失。適合比較兩種算法使用數據的效率。
如果你的算法在50萬張時達到70%、100萬張時達到75%,這可能比50萬張時達到50%,100萬張時達到80%的還要好。
另外,它還消除了Batch Size的影響。這允許在不同GPU上訓練的具有不同Batch Size的模型之間進行公平的比較。
Loss/Time也很重要,因為如果一個新模型減少了100個Epoch,但每個Iteration都慢100倍,我就不會選擇這個模型。
雖然Loss/Time關系到硬件的具體表現,不夠精準,我不會把這個寫到論文里。但在自己的機器上這是很好的評估模型的參數。
使用數據增強時呢?
有網友提出,數據增強 (Data Augmentation)時Epoch也有點多余。因為數據集太小,人為給每個樣本添加很多只有微小差距的版本,沒必要讓他們被同頻率使用。
反對者認為,數據增強作為正則化的一種形式減少了過擬合,但你引入的實際信息在訓練模型時仍然局限于原始數據集。如果你的原始數據集足夠小,Epoch表示你向模型展示了整個訓練集,仍然是有意義的。
有人問道:
你是想表達“紀元(Epoch)”的紀元結束了嗎?
調參俠:
對,現在是“時代(Era)”的時代。
△無盡隨機增強的首字母縮寫ERA意為“時代”