遇事不決,XGBoost,梯度提升比深度學習更容易贏得Kaggle競賽
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
在Kaggle上參加機器學習比賽,用什么算法最容易拿獎金?
你可能會說:當然是深度學習。
還真不是,據統計獲勝最多的是像XGBoost這種梯度提升算法。
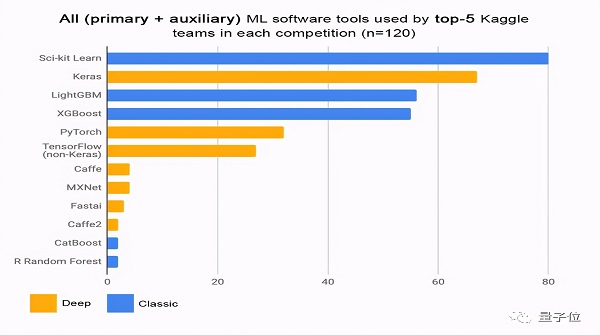
這就奇了怪了,深度學習在圖像、語言等領域大放異彩,怎么在機器學習比賽里還不如老前輩了。
一位Reddit網友把這個問題發在機器學習板塊(r/MachineLearning),并給出了一個直覺上的結論:
提升算法在比賽中提供的表格類數據中表現最好,而深度學習適合非常大的非表格數據集(例如張量、圖片、音頻、文本)。
但這背后的原理能不能用數學原理來解釋?
更進一步,能不能僅通過數據集的類型和規模來判斷哪種算法更適用于手頭的任務。
這能節省很多時間啊,舉個極端點的例子,如果嘗試用AlphaGo做Logistic回歸,你就走遠了。
問題吸引了很多人參與討論,有人回復到:
這是一個十分活躍的研究領域,完全可以就這個主題做一篇博士論文了。
關鍵在能不能人工提取特征
有網友表示,雖然很難給出詳細論證,但可以猜測一下。
基于樹的梯度提升算法可以簡單地分離數據,就像這樣:
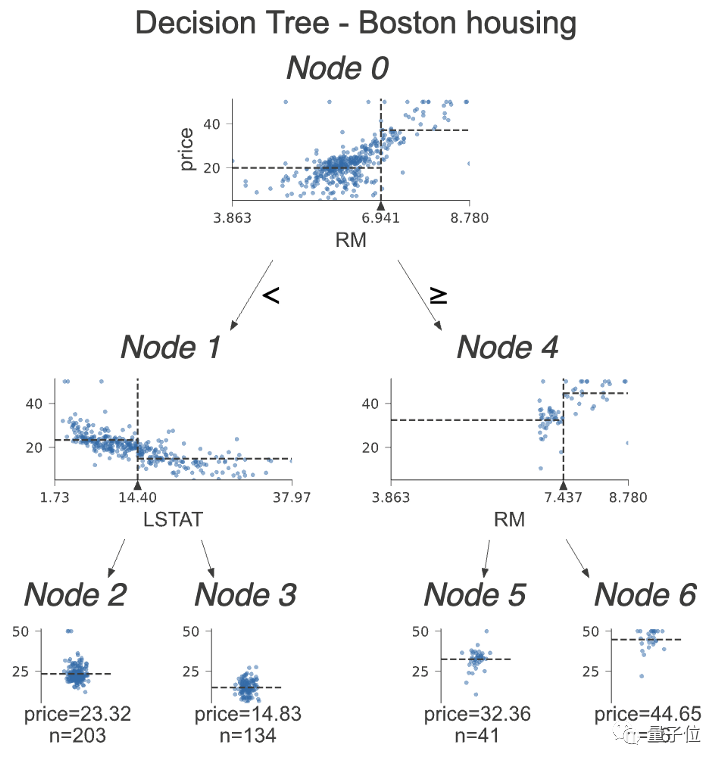
如果特征小于某個值就向左,反之就向右,一步一步把數據拆解。
在深度學習中,要用到多個隱藏層才能把輸入空間變換成線性可分割:
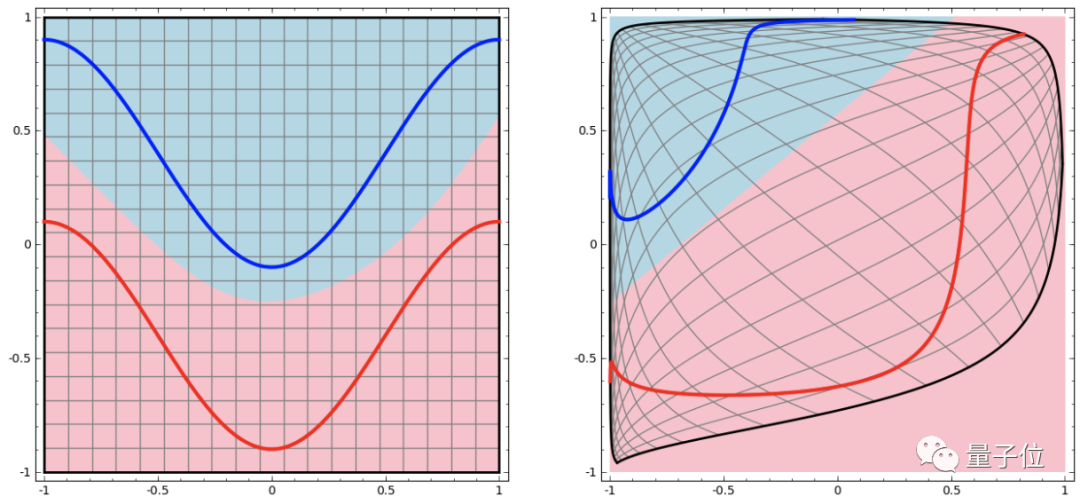
這個過程就像是把輸入空間在高維進行“揉捏”:

數據集越復雜,需要的隱藏層就越多,變換過程很可能失敗,反而讓數據更加纏在一起:
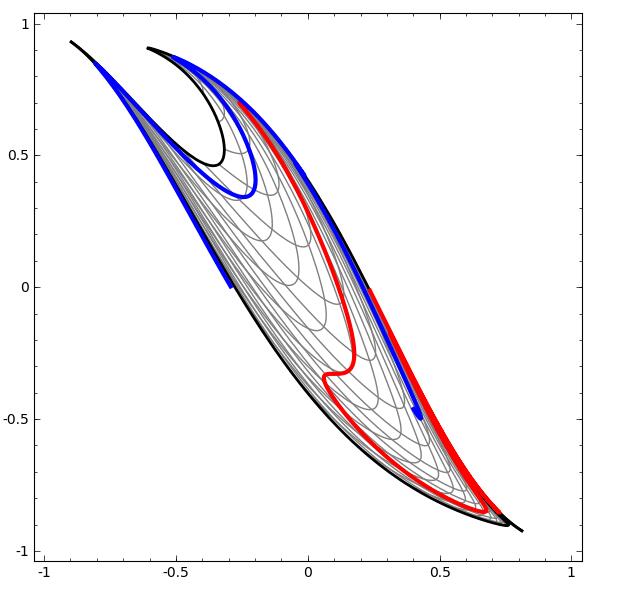
即使成功了,相對梯度提升樹來說也是效率極低的。
深度學習的優勢是,面對人類很難手工提取特征的復雜數據可以自動創建隱藏特征。
而且即使你手工創建了特征,深度網絡無論如何還是會自己創建隱藏特征。
而Kaggle比賽中使用的表格數據,特征往往已經有了,就是表頭,那么直接使用梯度提升就好。
就像Kaggle Avito挑戰的冠軍所說:“遇事不決,XGBoost”。

吃數據的怪物
另一個高贊回復是:
大多數Kaggle比賽的數據集都不夠喂出一個神經網絡怪物。

在小數據集上深度學習容易過擬合,正則化的方法又依賴許多條件。在給定數據集的比賽上,還是梯度提升比較迅速、穩定。
而參數越多的深度神經網絡需要越多的數據,比賽提供的數據集有限,數據維度也比較低,發揮不出深度學習的實力。
一位在Kaggle上成績很好的大神補充到:
不同的深度網絡適用于某種數據集,如CNN適合處理圖像,RNN適合處理特定的序列等。比賽給的數據集很難找到合適的預訓練模型可用。
總的來看,深度學習在表格數據上的性能肯定優于梯度提升,但是需要大量時間優化網絡架構。
Kaggle上的勝出方案一般是將二者結合,加上梯度提升,有經驗的選手在幾個小時內就能得到不錯的結果。