看完這一篇,ShardingSphere-jdbc 實戰(zhàn)再也不怕了
談到分庫分表中間件時,我們自然而然的會想到 ShardingSphere-JDBC 。
這篇文章,我們聊聊 ShardingSphere-JDBC 相關知識點,并實戰(zhàn)演示一番。

1、ShardingSphere 生態(tài)
Apache ShardingSphere 是一款分布式的數(shù)據(jù)庫生態(tài)系統(tǒng),它包含兩大產品:
- ShardingSphere-Proxy
- ShardingSphere-JDBC
一、ShardingSphere-Proxy
ShardingSphere-Proxy 被定位為透明化的數(shù)據(jù)庫代理端,提供封裝了數(shù)據(jù)庫二進制協(xié)議的服務端版本,用于完成對異構語言的支持。

代理層介于應用程序與數(shù)據(jù)庫間,每次請求都需要做一次轉發(fā),請求會存在額外的時延。
這種方式對于應用非常友好,應用基本零改動,和語言無關,可以通過連接共享減少連接數(shù)消耗。
二、ShardingSphere-JDBC
ShardingSphere-JDBC 是 ShardingSphere 的第一個產品,也是 ShardingSphere 的前身, 我們經常簡稱之為:sharding-jdbc 。
它定位為輕量級 Java 框架,在 Java 的 JDBC 層提供的額外服務。它使用客戶端直連數(shù)據(jù)庫,以 jar 包形式提供服務,無需額外部署和依賴,可理解為增強版的 JDBC 驅動,完全兼容 JDBC 和各種 ORM 框架。

當我們在 Proxy 和 JDBC 兩種模式選擇時,可以參考下表對照:
JDBC | Proxy | |
數(shù)據(jù)庫 | ? | MySQL/PostgreSQL |
連接消耗數(shù) | ? | 低 |
異構語言 | ? | 任意 |
性能 | ? | 損耗略高 |
無中心化 | ? | 否 |
靜態(tài)入口 | ? | 有 |
越來越多的公司都在生產環(huán)境使用了 sharding-jdbc ,最核心的原因就是:簡單(原理簡單,易于實現(xiàn),方便運維)。
2、基本原理
在后端開發(fā)中,JDBC 編程是最基本的操作。不管 ORM 框架是 Mybatis 還是 Hibernate ,亦或是 spring-jpa ,他們的底層實現(xiàn)是 JDBC 的模型。

sharding-jdbc 的本質上就是實現(xiàn) JDBC 的核心接口。

接口 | 實現(xiàn)類 |
DataSource | ShardingDataSource |
Connection | ShardingConnection |
Statement | ShardingStatement |
PreparedStatement | ShardingPreparedStatement |
ResultSet | ShardingResultSet |
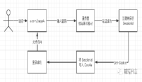
雖然我們理解了 sharding-jdbc 的本質,但是真正實現(xiàn)起來還有非常多的細節(jié),下圖展示了 Prxoy 和 JDBC 兩種模式的核心流程。

1.SQL 解析
分為詞法解析和語法解析。先通過詞法解析器將 SQL 拆分為一個個不可再分的單詞。再使用語法解析器對 SQL 進行理解,并最終提煉出解析上下文。
解析上下文包括表、選擇項、排序項、分組項、聚合函數(shù)、分頁信息、查詢條件以及可能需要修改的占位符的標記。
2.執(zhí)行器優(yōu)化
合并和優(yōu)化分片條件,如 OR 等。
3.SQL 路由
根據(jù)解析上下文匹配用戶配置的分片策略,并生成路由路徑。目前支持分片路由和廣播路由。
4.SQL 改寫
將 SQL 改寫為在真實數(shù)據(jù)庫中可以正確執(zhí)行的語句。SQL 改寫分為正確性改寫和優(yōu)化改寫。
5.SQL 執(zhí)行
通過多線程執(zhí)行器異步執(zhí)行。
6.結果歸并
將多個執(zhí)行結果集歸并以便于通過統(tǒng)一的 JDBC 接口輸出。結果歸并包括流式歸并、內存歸并和使用裝飾者模式的追加歸并這幾種方式。
本文的重點在于實戰(zhàn)層面, sharding-jdbc 的實現(xiàn)原理細節(jié)我們會在后續(xù)的文章一一給大家呈現(xiàn) 。
3、實戰(zhàn)案例
筆者曾經為武漢一家 O2O 公司訂單服務做過分庫分表架構設計 ,當企業(yè)用戶創(chuàng)建一條采購訂單 , 會生成如下記錄:
- 訂單基礎表t_ent_order :單條記錄
- 訂單詳情表t_ent_order_detail :單條記錄
- 訂單明細表t_ent_order_item:N 條記錄
訂單數(shù)據(jù)采用了如下的分庫分表策略:
- 訂單基礎表按照 ent_id (企業(yè)用戶編號) 分庫 ,訂單詳情表保持一致;
- 訂單明細表按照 ent_id (企業(yè)用戶編號) 分庫,同時也要按照 ent_id (企業(yè)編號) 分表。
首先創(chuàng)建 4 個庫,分別是:ds_0、ds_1、ds_2、ds_3 。
這四個分庫,每個分庫都包含 訂單基礎表 , 訂單詳情表 ,訂單明細表 。但是因為明細表需要分表,所以包含多張表。

然后 springboot 項目中配置依賴 :
配置文件中配置如下:

- 配置數(shù)據(jù)源,上面配置數(shù)據(jù)源是:ds0、ds1、ds2、ds3 ;
- 配置打印日志,也就是:sql.show ,在測試環(huán)境建議打開 ,便于調試;
- 配置哪些表需要分庫分表 ,在 shardingsphere.datasource.sharding.tables 節(jié)點下面配置:

上圖中我們看到配置分片規(guī)則包含如下兩點:
1.真實節(jié)點
對于我們的應用來講,我們查詢的邏輯表是:t_ent_order_item 。
它們在數(shù)據(jù)庫中的真實形態(tài)是:t_ent_order_item_0? 到 t_ent_order_item_7。
真實數(shù)據(jù)節(jié)點是指數(shù)據(jù)分片的最小單元,由數(shù)據(jù)源名稱和數(shù)據(jù)表組成。
訂單明細表的真實節(jié)點是:ds$->{0..3}.t_ent_order_item_$->{0..7} 。
2.分庫分表算法
配置分庫策略和分表策略 , 每種策略都需要配置分片字段( sharding-columns )和分片算法。
4、基因法 & 自定義復合分片算法
分片算法和阿里開源的數(shù)據(jù)庫中間件 cobar 路由算法非常類似的。
假設現(xiàn)在需要將訂單表平均拆分到4個分庫 shard0 ,shard1 ,shard2 ,shard3 。
首先將 [0-1023] 平均分為4個區(qū)段:[0-255],[256-511],[512-767],[768-1023],然后對字符串(或子串,由用戶自定義)做 hash, hash 結果對 1024 取模,最終得出的結果 slot 落入哪個區(qū)段,便路由到哪個分庫。

看起來分片算法很簡單,但我們需要按照訂單 ID 查詢訂單信息時依然需要路由四個分片,效率不高,那么如何優(yōu)化呢 ?
答案是:基因法 & 自定義復合分片算法。
基因法是指在訂單 ID 中攜帶企業(yè)用戶編號信息,我們可以在創(chuàng)建訂單 order_id 時使用雪花算法,然后將 slot 的值保存在 10位工作機器 ID 里。

通過訂單 order_id 可以反查出 slot , 就可以定位該用戶的訂單數(shù)據(jù)存儲在哪個分片里。
下圖展示了訂單 ID 使用雪花算法的生成過程,生成的編號會攜帶企業(yè)用戶 ID 信息。

解決了分布式 ID 問題,接下來的一個問題:sharding-jdbc 可否支持按照訂單 ID ,企業(yè)用戶 ID 兩個字段來決定分片路由嗎?
答案是:自定義復合分片算法。我們只需要實現(xiàn) ComplexKeysShardingAlgorithm 類即可。

復合分片的算法流程非常簡單:
1.分片鍵中有主鍵值,則直接通過主鍵解析出路由分片;
2.分片鍵中不存在主鍵值 ,則按照其他分片字段值解析出路由分片。
5、擴容方案
既然做了分庫分表,如何實現(xiàn)平滑擴容也是一個非常有趣的話題。
在數(shù)據(jù)同步之前,需要梳理遷移范圍。
1.業(yè)務唯一主鍵;
在進行數(shù)據(jù)同步前,需要先梳理所有表的唯一業(yè)務 ID,只有確定了唯一業(yè)務 ID 才能實現(xiàn)數(shù)據(jù)的同步操作。
需要注意的是:業(yè)務中是否有使用數(shù)據(jù)庫自增 ID 做為業(yè)務 ID 使用的,如果有需要業(yè)務先進行改造 。另外確保每個表是否都有唯一索引,一旦表中沒有唯一索引,就會在數(shù)據(jù)同步過程中造成數(shù)據(jù)重復的風險,所以我們先將沒有唯一索引的表根據(jù)業(yè)務場景增加唯一索引(有可能是聯(lián)合唯一索引)。
2.遷移哪些表,遷移后的分庫分表規(guī)則;
分表規(guī)則不同決定著 rehash 和數(shù)據(jù)校驗的不同。需逐個表梳理是用戶ID緯度分表還是非用戶ID緯度分表、是否只分庫不分表、是否不分庫不分表等等。
接下來,進入數(shù)據(jù)同步環(huán)節(jié)。
整體方案見下圖,數(shù)據(jù)同步基于 binlog ,獨立的中間服務做同步,對業(yè)務代碼無侵入。

首先需要做歷史數(shù)據(jù)全量同步:也就是將舊庫遷移到新庫。
單獨一個服務,使用游標的方式從舊庫分片 select 語句,經過 rehash 后批量插入 (batch insert)到新庫,需要配置jdbc 連接串參數(shù) rewriteBatchedStatements=true 才能使批處理操作生效。
因為歷史數(shù)據(jù)也會存在不斷的更新,如果先開啟歷史數(shù)據(jù)全量同步,則剛同步完成的數(shù)據(jù)有可能不是最新的。
所以我們會先開啟增量數(shù)據(jù)單向同步(從舊庫到新庫),此時只是開啟積壓 kafka 消息并不會真正消費;然后在開始歷史數(shù)據(jù)全量同步,當歷史全量數(shù)據(jù)同步完成后,在開啟消費 kafka 消息進行增量數(shù)據(jù)同步(提高全量同步效率減少積壓也是關鍵的一環(huán)),這樣來保證遷移數(shù)據(jù)過程中的數(shù)據(jù)一致。
增量數(shù)據(jù)同步考慮到灰度切流穩(wěn)定性、容災 和可回滾能力 ,采用實時雙向同步方案,切流過程中一旦新庫出現(xiàn)穩(wěn)定性問題或者新庫出現(xiàn)數(shù)據(jù)一致問題,可快速回滾切回舊庫,保證數(shù)據(jù)庫的穩(wěn)定和數(shù)據(jù)可靠。
增量數(shù)據(jù)實時同步的大體思路 :
1.過濾循環(huán)消息
需要過濾掉循環(huán)同步的 binlog 消息 ;
2.數(shù)據(jù)合并
同一條記錄的多條操作只保留最后一條。為了提高性能,數(shù)據(jù)同步組件接到 kafka 消息后不會立刻進行數(shù)據(jù)流轉,而是先存到本地阻塞隊列,然后由本地定時任務每X秒將本地隊列中的N條數(shù)據(jù)進行數(shù)據(jù)流轉操作。此時N條數(shù)據(jù)有可能是對同一張表同一條記錄的操作,所以此處只需要保留最后一條(類似于 redis aof 重寫);
3.update 轉 insert
數(shù)據(jù)合并時,如果數(shù)據(jù)中有 insert + update 只保留最后一條 update ,會執(zhí)行失敗,所以此處需要將 update 轉為 insert 語句 ;
4.按新表合并
將最終要提交的 N 條數(shù)據(jù),按照新表進行拆分合并,這樣可以直接按照新表緯度進行數(shù)據(jù)庫批量操作,提高插入效率。
擴容方案文字來自 《256變4096:分庫分表擴容如何實現(xiàn)平滑數(shù)據(jù)遷移》,筆者做了些許調整。
6、總結
sharding-jdbc 的本質是實現(xiàn) JDBC 的核心接口,架構相對簡單。
實戰(zhàn)過程中,需要配置數(shù)據(jù)源信息,邏輯表對應的真實節(jié)點和分庫分表策略(分片字段和分片算法)
實現(xiàn)分布式主鍵直接路由到對應分片,則需要使用基因法 & 自定義復合分片算法 。
平滑擴容的核心是全量同步和實時雙向同步,工程上有不少細節(jié)。
實戰(zhàn)代碼地址:
https://github.com/makemyownlife/shardingsphere-jdbc-demo