自然語言處理領(lǐng)域的核心:序列學(xué)習(xí)
生活中的所有事物都是與時(shí)間相關(guān)的,也就形成了一個(gè)序列。為了對(duì)序列數(shù)據(jù)(文本、演講、視頻等)我們可以使用神經(jīng)網(wǎng)絡(luò)并導(dǎo)入整個(gè)序列,但是這樣我們的數(shù)據(jù)輸入尺寸是固定的,局限性就很明顯。如果重要的時(shí)序特征事件恰好落在輸入窗以外,就會(huì)產(chǎn)生更大的問題。所以我們需要的是:
-
能對(duì)任意長度序列做逐個(gè)元素讀取的神經(jīng)網(wǎng)絡(luò)(比如視頻就是一系列的圖片;我們每次給神經(jīng)網(wǎng)絡(luò)一張圖);
-
有記憶的神經(jīng)網(wǎng)絡(luò),能夠記得若干個(gè)時(shí)間步以前的事件、這些問題和需求已經(jīng)催生出多中不同的循環(huán)神經(jīng)網(wǎng)絡(luò)。
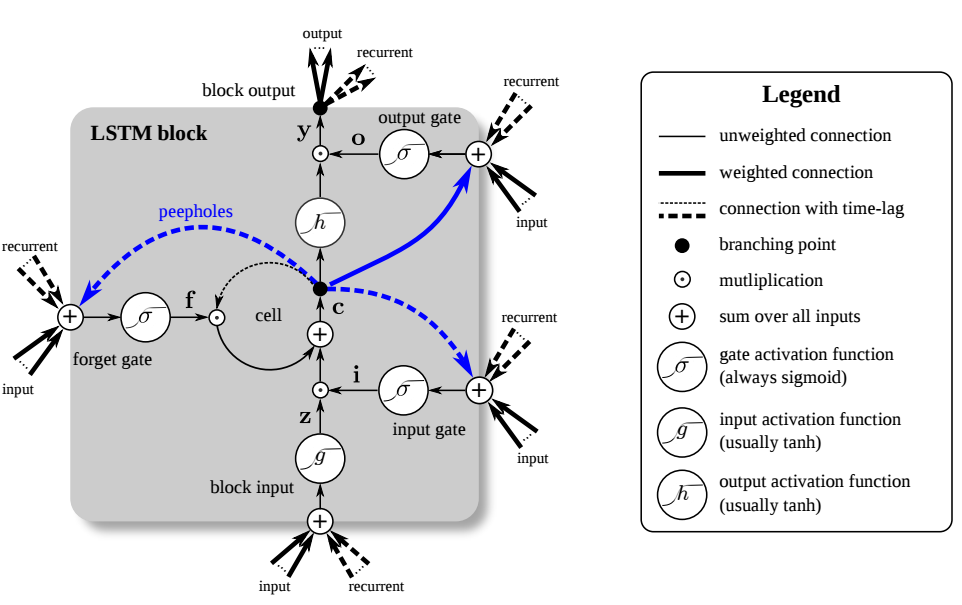
圖1:長短期記憶(LSTM)單元。LSTM有四個(gè)輸入權(quán)重和四個(gè)循環(huán)權(quán)重。Peepholes是記憶細(xì)胞和門之間的額外連接,但他們對(duì)性能提升幫助不到,所以常被忽略。
循環(huán)神經(jīng)網(wǎng)絡(luò)
若我們想讓一個(gè)常規(guī)的神經(jīng)網(wǎng)絡(luò)解決兩個(gè)數(shù)相加的問題,那我們只需要輸入兩個(gè)數(shù)字,再訓(xùn)練兩數(shù)之和的預(yù)測即可。如果現(xiàn)在有3個(gè)數(shù)要相加,那么我們可以:
-
拓展網(wǎng)絡(luò)架構(gòu),添加輸入和權(quán)重,再重新訓(xùn)練;
-
把第一次的輸出(即兩數(shù)之和)和第三個(gè)數(shù)作為輸入,再返回給網(wǎng)絡(luò)。
方案(2)顯然更好,因?yàn)槲覀兿M苊庵匦掠?xùn)練整個(gè)網(wǎng)絡(luò)(網(wǎng)絡(luò)已經(jīng)“知道”如何將兩個(gè)數(shù)相加)。如果我們的任務(wù)變成:先對(duì)兩數(shù)做加法,再減去兩個(gè)不同的數(shù),那這個(gè)方案又不好使了。即使我們使用額外的權(quán)重,也不能保證正確的輸出。相反,我們可以嘗試“修改程序”,把網(wǎng)絡(luò)由“加法”變成“減法”。通過隱藏層的加權(quán)可以實(shí)現(xiàn)這一步(見圖2),如此便讓網(wǎng)絡(luò)的內(nèi)核隨著每個(gè)新的輸入而變化。網(wǎng)絡(luò)將學(xué)習(xí)著在相加兩個(gè)數(shù)之后,把程序從“加法”變成“減法”,然后就解決了問題。
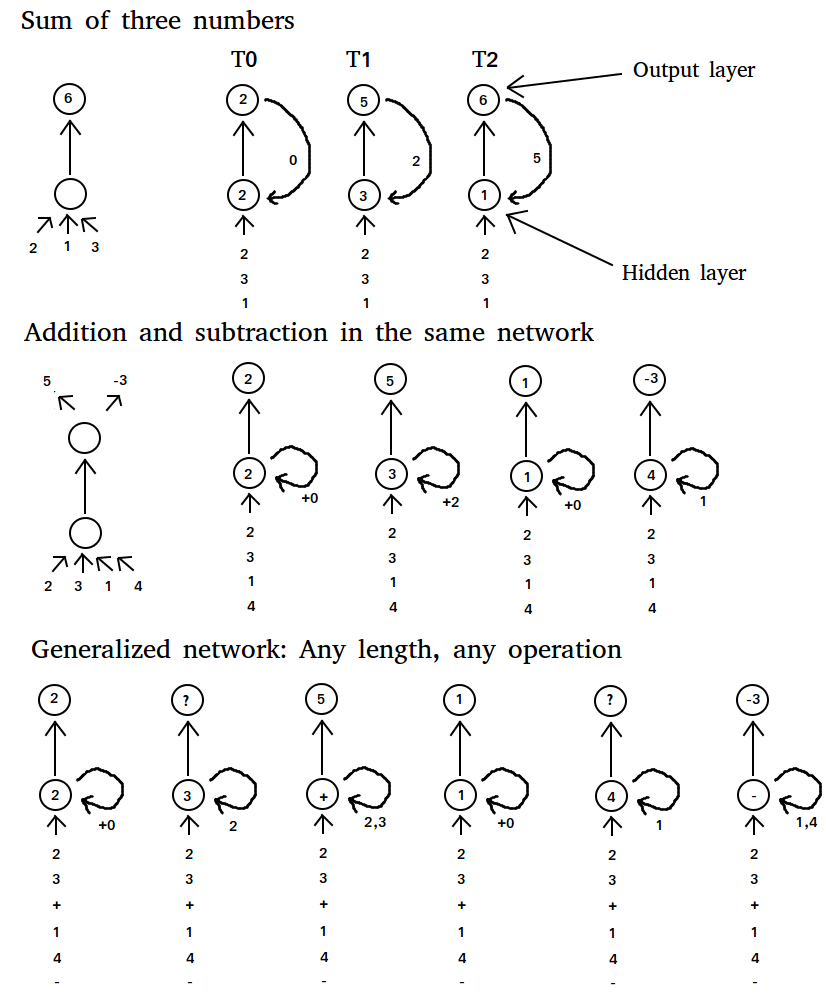
我們甚至可以泛化這一方法,傳遞給網(wǎng)絡(luò)兩個(gè)數(shù)字,再傳入一個(gè)“特殊”的數(shù)字——代表著數(shù)學(xué)運(yùn)算“加法”,“減法”或“乘法”。實(shí)踐當(dāng)中這樣或許不盡完美,但也能得到大體正確的結(jié)果了。不過這里的主要問題倒不在于得到正確結(jié)果,而是我們可以訓(xùn)練循環(huán)神經(jīng)網(wǎng)絡(luò),使之能夠?qū)W習(xí)任意輸入序列所產(chǎn)生的特殊輸出,這就威力大了。
例如,我們可以教網(wǎng)絡(luò)學(xué)會(huì)詞語的序列。Soumith Chintala和Wojciech Zaremba寫了一篇優(yōu)秀的博客講述用RNN做自然語言處理。RNN也可以用于生成序列。Andrej Karpathy寫了這篇[有趣而生動(dòng)的博客],展示了字詞級(jí)別的RNN,可以模仿各種文風(fēng),從莎士比亞,到Linux源碼,再到給小孩兒起名。
長短期記憶(Long Short Term Memory, LSTM)
長短期記憶單元使用自連接的線性單元,權(quán)重為常數(shù)1.0。這使得流入自循環(huán)的值(前向傳播)或梯度(反向傳播)可以保持不變(乘以1.0的輸入或誤差還是原來的值;前一時(shí)間步的輸出或誤差也和下一時(shí)間步的輸出相同),因而所有的值和梯度都可以在需要的時(shí)候準(zhǔn)確回調(diào)。這個(gè)自循環(huán)的單元,記憶細(xì)胞,提供了一種可以儲(chǔ)存信息的記憶功能,對(duì)之前的若干個(gè)時(shí)間步當(dāng)中有效。這對(duì)很多任務(wù)都極其有效,比如文本數(shù)據(jù),LSTM可以存儲(chǔ)前一段的信息,并對(duì)當(dāng)前段落的序列應(yīng)用這些信息。
另外,深度網(wǎng)絡(luò)中一個(gè)很普遍的問題叫作“梯度消失”問題,也即,梯度隨著層數(shù)增多而越來越小。有了LSTM中的記憶細(xì)胞,就有了連續(xù)的梯度流(誤差保持原值),從而消除了梯度消失問題,能夠?qū)W習(xí)幾百個(gè)時(shí)間步那么長的序列。
然而有時(shí)我們會(huì)想要拋掉舊有信息,替換以更新、更相關(guān)的信息。同時(shí)我們又不想釋放無效信息干擾其余部分的網(wǎng)絡(luò)。為了解決這個(gè)問題,LSTM單元擁有一個(gè)遺忘門,在不對(duì)網(wǎng)絡(luò)釋放信息的情況下刪除自循環(huán)單元內(nèi)的信息(見圖1)。遺忘門將記憶細(xì)胞里的值乘以0~1之間的數(shù)字,其中0表示遺忘,1表示保持原樣。具體的數(shù)值宥當(dāng)前輸入和上一時(shí)間步的LSTM單元輸出決定。
在其他時(shí)間,記憶細(xì)胞還需要保持多個(gè)時(shí)間步內(nèi)不變,為此LSTM增加了另一道門,輸入門(或?qū)懭腴T)。當(dāng)輸入門關(guān)閉時(shí),新信息就不會(huì)流入,原有信息得到保護(hù)。
另一個(gè)門將記憶細(xì)胞的輸出值乘以0(抹除輸出)~1()之間的數(shù),當(dāng)多個(gè)記憶相互競爭時(shí)這很有用:一個(gè)記憶細(xì)胞可能說:“我的記憶非常重要!所以我現(xiàn)在就要釋放”,但是網(wǎng)絡(luò)卻可能說:“你的記憶是很重要,不過現(xiàn)在又其他更重要的記憶細(xì)胞,所以我給你的輸出門賦予一個(gè)微小的數(shù)值,給其他門大數(shù)值,這樣他們會(huì)勝出”。
LSTM單元的連接方式初看可能有些復(fù)雜,你需要一些時(shí)間去理解。但是當(dāng)你分別考察各個(gè)部件的時(shí)候,會(huì)發(fā)現(xiàn)其結(jié)構(gòu)其實(shí)跟普通的循環(huán)神經(jīng)網(wǎng)絡(luò)沒啥兩樣——輸入和循環(huán)權(quán)重流向所有的門,連接到自循環(huán)記憶細(xì)胞。
想要更深入地了解LSTM并認(rèn)識(shí)整個(gè)架構(gòu),我推薦閱讀:LSTM: A Search Space Odyssey和original LSTM paper。
詞嵌入(Word Embedding)

圖3:菜譜的二維詞嵌入空間,這里我們局部放大了“南歐”的聚類群
想象"cat"和其他所有與"cat"相關(guān)聯(lián)的詞匯,你可能會(huì)想到"kitten","feline"。再想一些不那么相似,但是又比"car"要相似得多的,比如"lion","tiger","dog","animal"或者動(dòng)詞"purring","mewing","sleeping"等等。
再想象一個(gè)三維的空間,我們把詞"cat"放在正中間。上面提到的詞語當(dāng)中,與"cat"相似的,空間位置也離得更近;比如"kitty","feline"就離中央很近;"tiger"和"lion"就稍微遠(yuǎn)一點(diǎn);"dog"再遠(yuǎn)一點(diǎn);而"car"就不知遠(yuǎn)到哪里去了。可以看圖3這個(gè)詞嵌入二維空間的例子。
如果我們我們用向量來代表空間里的每一個(gè)詞,那么每個(gè)向量就由3個(gè)坐標(biāo)構(gòu)成,比如"cat"是(0, 0, 0),"kitty"可能是(0,1, 0,2, -0,3)而"car"則是(10, 0, -15)。這個(gè)向量空間,就是詞嵌入空間,每個(gè)詞對(duì)應(yīng)的三個(gè)坐標(biāo)可以用做算法的輸入數(shù)據(jù)。
典型的詞嵌入空間含有上千個(gè)詞和上百個(gè)維度,人類是很難直觀理解的,但是相似的詞距離近這個(gè)規(guī)律仍然成立。對(duì)于機(jī)器來說,這是一種很好的詞匯表征,可以提高自然語言處理能力。
如果你想要學(xué)習(xí)更多詞嵌入的內(nèi)容,以及如何應(yīng)用于創(chuàng)建模型“理解”語言,推薦閱讀:Understanding Natural Language with Deep Neural Networks Using Torch,作者:Soumith Chintala和Wojciech Zaremba。
編碼-解碼
讓我們暫時(shí)停下自然語言處理,來想象一個(gè)西紅柿,想象那些適合西紅柿的配料或菜肴。如果你的想法和那些網(wǎng)上最常見的菜譜差不多,那你想到的可能是諸如奶酪和薩拉米;帕爾馬干酪、羅勒、通心粉;或其他配料比如橄欖油、百里香和西芹等等。(換作中國人來想,肯定是雞蛋)。這些配料主要都是意大利、地中海菜系。
還是那個(gè)西紅柿,如果要吃墨西哥菜系,你想到的可能是豆子、玉米、辣椒、芫荽葉或鱷梨。
你剛才所想的,就是把詞匯“西紅柿”的表征變換成了新的表征:“墨西哥菜里的西紅柿”。
“編碼”(Encoder)做的是同樣的事,它通過變換詞匯的表征,把輸入詞匯逐個(gè)變換為新的“思維向量”。就像給“西紅柿”加入了上下文“墨西哥菜”,這是“編碼-解碼”架構(gòu)的第一步。
編碼-解碼架構(gòu)的第二步是基于這樣一個(gè)事實(shí):不同的語種在詞嵌入空間里,具有相似的幾何結(jié)構(gòu),即便對(duì)同一個(gè)事物,描述用詞完全不同。比如在德語里“貓”是"Katze",狗是"Hund",與英語截然不同,但是兩個(gè)詞之間的關(guān)系確實(shí)一樣。Karze與Hund的關(guān)系,跟Car與Dog的關(guān)系完全一致,換言之,即使詞匯本身不同,他們背后的“思維向量”確實(shí)一樣的。當(dāng)然也有些詞匯很難用其他語言表達(dá)(比如中文里的“緣分”之類),但是這種情況比較稀罕,總體上是成立的。
基于以上思想,我們就可以構(gòu)建解碼網(wǎng)絡(luò)了。我們把英語編碼器產(chǎn)生的“思維向量”傳遞給德語解碼器。德語解碼器會(huì)把這些思維向量或關(guān)系變換映射到德語詞嵌入空間里,然后就會(huì)產(chǎn)生一句話,保持英語句子里的關(guān)系。如此我們就有了一個(gè)能做翻譯的網(wǎng)絡(luò),這個(gè)思想目前仍在發(fā)展,結(jié)果雖然不完美,但卻在極快提高,不久就會(huì)成為翻譯的最佳方法。